The blog is posted by WeCloudData’s student Amany Abdelhalim.

In this article, I am illustrating how to collect tweets into a kinesis data stream and then analyze the tweets using kinesis data analytics.</p></p>
The steps that I followed:
- Create a kinesis data stream.

I created a kinesis data stream which I called “twitter” with one shard.

2. Prepare the script that will collect the tweets and write them into the kinesis data stream.
I prepared the following python script, where I select 11 attributes from each tweet. An make sure to write them into the “twitter” kinesis data stream that I created in the first step. I ran the script from my local machine. But you can run the script on an EC2 instance and you can even run the script using nohup to ensure that the script runs in the background even if after disconnecting the ssh session.</p></p></p></p>
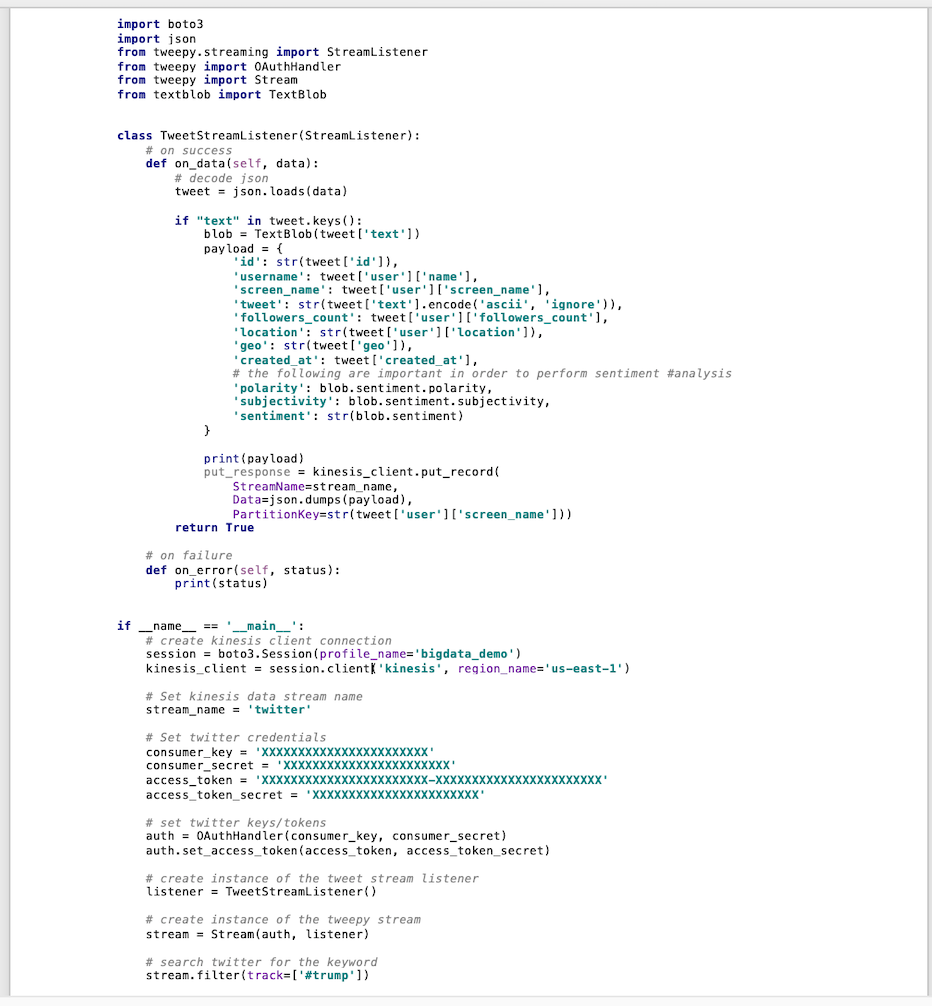
Python Script
In the above script I am hard coding my twitter credentials which is not recommended. There are other safer options available, such as using environment variables or passing arguments to your script.
3. Create an application in kinesis data analytics that will be used to analyze the data in the kinesis data stream.
I created an application in kinesis data analytics and I called it “twitter_analysis”. I also chose to process the data using SQL which is the default option, then I clicked create application.

After the application was successfully created, I clicked on connect streaming data in order to choose the source of the data stream. The source of the data stream can only be one streaming data source.

a-selectable-par=””>&gt;agraph=””>There is two options, where you can choose an existing source that you have created before or you can configure a new stream.</p>&lt;/p></p></p>
The default is “choose a source”. I selected the kinesis data stream that I created before which is the “twitter” data stream.</p>

I hit the “Discover schema” button.


&gt;ctable-paragraph=””>The name of the “twitter” kinesis data stream that I have to use in the SQL editor is shown below which is “SOURCE_SQL_STREAM_001”.</p></p></p></p>
I clicked on the “Go to SQL editor” button.


&gt;data-selectable-paragraph=””>The following shows a sample of the streaming data coming from the source kinesis data stream “twitter”, which is referred to as the “SOURCE_SQL_STREAM_001” stream.</p></p></p></p>

&gt;ble-paragraph=””>The first tab “Save and run SQL” will allow you to write SQL statements and run the code on the streaming source data.</p></p></p></p>

&gt;ble-paragraph=””>The following window opens when you select the tab “Add SQL from templates” which will show you some ready made templates that allow you to perform some analysis on the stream data such as anomaly detection.</p></p></p></p>

ass=”gk gl ap cd gm b gn go gp gq gr gs gt gu gv gw gx gy gz ha hb hc cv” data-selecta=””>&gt;ble-paragraph=””>Below, I will show three examples of SQL statements that I wrote in the SQL Editor and I hit the tab “save and run SQL” to display the results.The following examples illustrate how to write SQL in the SQL Editor and display results; you can perform far more useful queries on the streaming data after cleaning it..</p></p></p></p>
Example1:
In the following example, I am only selecting the tweets column.
&gt;ble-paragraph=””>As you can see, first I created a stream that will be holding the output that I desire, I called the stream “TEMP_STREAM”.</p></p></p></p>
&gt;ble-paragraph=””>Then I prepared a PUMP by the keywords “CREATE OR REPLACE PUMP” to insert into the output stream “TEMP_STREAM” the values of the tweet coulmn selected from the source stream “SOURCE_SQL_STREAM_001”.</p></p></p></p>

The following shows the output of the “TEMP_STREAM”.

Example2:
In the following example, I am only selecting the tweets that have the word trump present.
ble-paragraph=””>As you can see, first I created a stream that will be holding the output that I desire. I called the stream “TEMP_STREAM”.</p></p>
&gt;=””>>=”gk gl ap cd gm b gn go gp gq gr gs gt gu gv gw gx gy gz ha hb hc cv” data-selectable-paragraph=””>Then I prepared a PUMP by the keywords “CREATE OR REPLACE PUMP” to insert into the output stream “TEMP_STREAM” the values of the tweet coulmn selected from the source stream “SOURCE_SQL_STREAM_001” that have the word “trump” present.</p></p></p></p>

The following shows the output of the “TEMP_STREAM”.

Example3:
In the following example, I am only selecting the tweets that have a have a negative sentiment.</p>
selectable-paragraph=””>As you can see, first
a-selectable-paragraph=””>I created a stream that will be holding the output that I desire, I called the stream “TEMP_STREAM”.</p></p>
&gt;CREATE OR REPLACE PUMP” to insert into the output stream “TEMP_STREAM” th
e values of the tweet coulmn selected from the source stream “SOURCE_SQL_STREAM_001” that have a negative sentiment.</p></p></p></p>

&gt;>data-selectable-paragraph=””>The following shows the output of the “TEMP_STREAM” which is updated every 2 to 10 seconds if new results are available.</p></p></p></p>

>new results every 2–10 seconds. So as you can see new tweets were added as time goes by and tweets with negative sentiment gets added to the source stream.</p></p></p></p>
 </p>
</p>
Or to a Firehose delivery stream, to continuously deliver SQL results to AWS destinations.</p></p>

The limit of destinations is three destinations for each application.


You can also choose the output format: Json or CSV.
 </p>
</p>
&gt;>ctable-paragraph=””>>As a Note if you choose your destination to be kinesis firehose, you can write the results in redshift and display the results on Superset dashboard.</p></p></p></p>
