The blog is posted by WeCloudData’s student Luis Vieira.
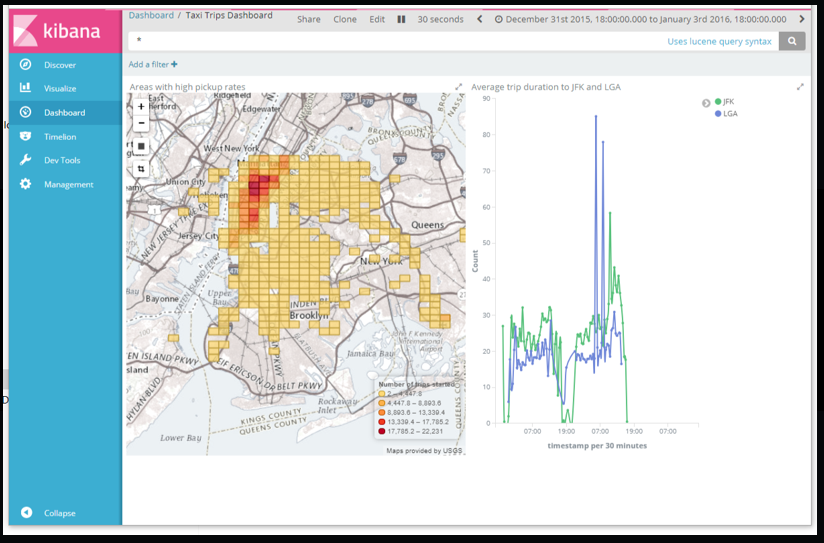
I will be showing how to build a real-time dashboard on Amazon Webservices for two different use cases, and a registry of open data from New York City Taxi and Limousine Commission (TLC) Trip Record Data. By the end you should have a Kibana Dashboard as following:
- Build a Real-time Stream Processing Pipeline with Apache Flink on Amazon Webservices;
- Build and Run Streaming Applications with Amazon Kinesis and Firehose Consumer.
In today’s business environments, data is generated in a continuous fashion by a steadily increasing number of diverse data sources.
Architecture
A reliable and scalable streaming architecture based on Flink, Kinesis Data Streams, and Kinesis Data Firehose
- Service Level Agreement — Requirements
- Consistency
- Low latency
- High availability
- High throughput
- Scale
- Data durability



2. Building elements
- Create the streams to capture and store the taxi fleet records; – Add or remove shards to scale throughput;
- Provision and manage cluster for your big data needs (EMR) – Apache Flink (Read events from kinesis, process performing transformation);
- Setup Elasticsearch cluster to integrate with Kibana;
- Lambda:
– Cloud Formation/Flink (Supports the stack and populates);
– Firehose (Transform records and load to Elasticsearch Service);
- Set up Firehose to delivery stream data;
- Inspect derived data with Kibana;
3. Let’s demo using Cloud Formation — Apache Flink
**Before you start, you will need to create an AWS Account.
3.1. CloudFormation-Flink: Building the runtime artifacts and creating the infrastructure
- Execute the first CloudFormation template to create an AWS CodePipeline pipeline, which builds the artifacts by means of AWS CodeBuild in a serverless fashion: Execute HERE. (check your region*)
- When the first template is created and the runtime artifacts are built, execute the second CloudFormation template, which creates the resources of the reference architecture described earlier: Execute HERE. (check your region*)
3.2. Set Flink on EMR: Enable Web Connection
- *You will have this screen.

Step 1: Open an SSH Tunnel to the Amazon EMR Master Node;
Download PuTTY: latest release (0.74)
This page contains download links for the latest released version of PuTTY. Currently this is 0.74, released on…
www.chiark.greenend.org.uk
Step 2: Configure a proxy management tool;
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-proxy.html
- Step 1: EMR-EC2

- Step 2: Flink Interface


3.3. Ingesting trip events into the Amazon Kinesis stream

3.4 Exploring Kibana


3.5 Scaling


4. Let’s demo using Kinesis Firehose
Building the runtime artifacts and creating the infrastructure. (Steps)
4.1 Create Kinesis Stream Data.
4.2 Connect Kinesis consumers.
- Delivery records with Firehose.
4.3 Create Firehose
- Enable Lambda to transform source records (taxi fleet records);
- Specify the index for ES (**Kibana index);
- Select Elasticsearch Service destination;
- Set bucket to backup;
4.4 Inspect derived data with Kibana

5. References
New York City Taxi and Limousine Commission (TLC) Trip Record Data
Data of Trips taken by taxis and for-hire vehicles in New York City.
I hope this blog helped you clearing concepts regarding Real-Time Stream Data and Dashboard on AWS. Don’t forget to like this blog if you genuinely liked it.
Follow for more awesome blogs!
