The blog is posted by WeCloudData’s Data Science Bootcamp student Weichen Lu.
Once, I was talking with my colleague about outdoor activities, and he told me that he is a fishing enthusiast. It didn’t bring up my attention at first since I am not a fishing guy. However, he proposed an idea to use Google Maps to search for all available fishing sites because of the difficulty with the official fishing website. The idea was brilliant and it attracted me as well. In the end, that’s how we started our first project at WeCloudData.
The first part of the project was to collect all the data from Fishing Ontario website, which was also the most challenge part. We had to use a package called Selenium to extract the data because the web page is dynamic. To be more specific, Selenium is a package which allows you to do the automation. We basically did some coding in Python and ran some automated tests on the Fishing Ontario website, which automatically extracts all 669 lakes in zone 16, along with its key information. You can check out the following videos in order to have a better understanding of how Selenium was used.
This demo shows you how Selenium gets into the page of data storage.
This demo shows you how the selenium extracts the information from each lake.
We did some data processing since not all of the information was required. There are multiple features for each lake and only the essential information had been extracted. For each extracted lake, it contains seven key features which are Lake Name, Municipality, Geographic Township, MNRF District, Coordinates, Waterbody and Fish Species. During the process of extracting data, the feature of each lake was stored into a data frame where the columns are those features, and it was ordered by the Lake Name in alphabetical order. Due to the loading time issue of the website, we extracted the data separately and saved it as a CSV file. Once we got all the data, we combined them into a final CSV file.
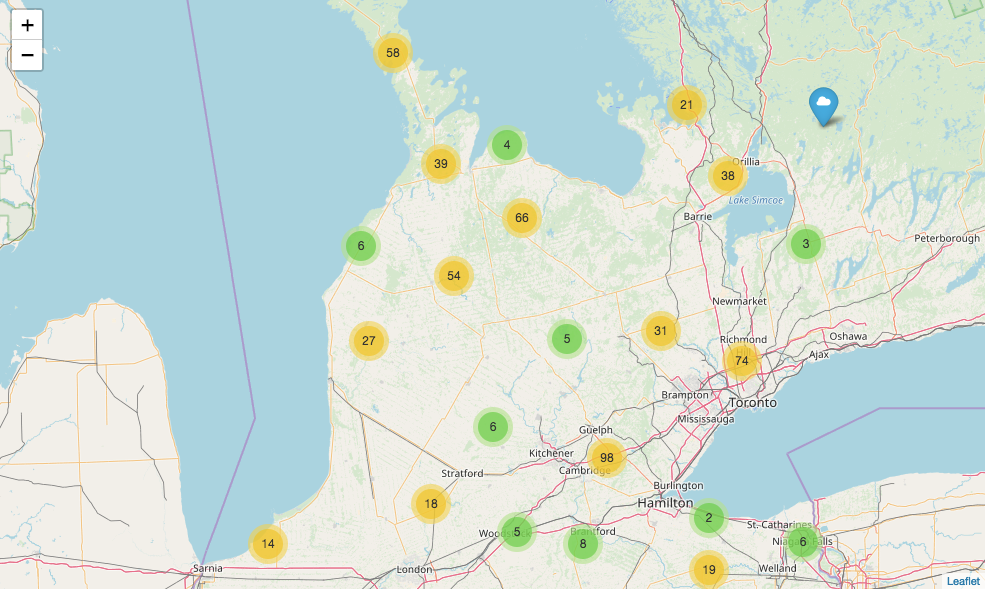
Furthermore, the second part of the project was to perform data visualization so we used three packages for completion, which were gmaps, googlemaps, and folium. First of all, folium is a package for people to perform map visualization on the open street map which everyone can edit and contribute to. We used folium because it has various fancy features, such as marker clustering. To demonstrate it, let’s look at the following images.
This is marker clustering using folium.

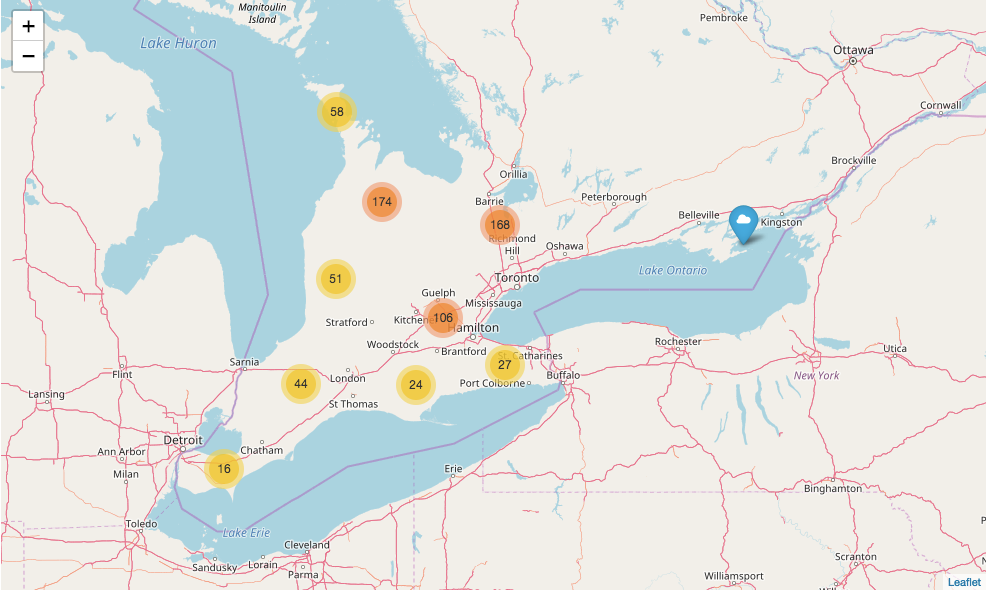
You can click the cluster.
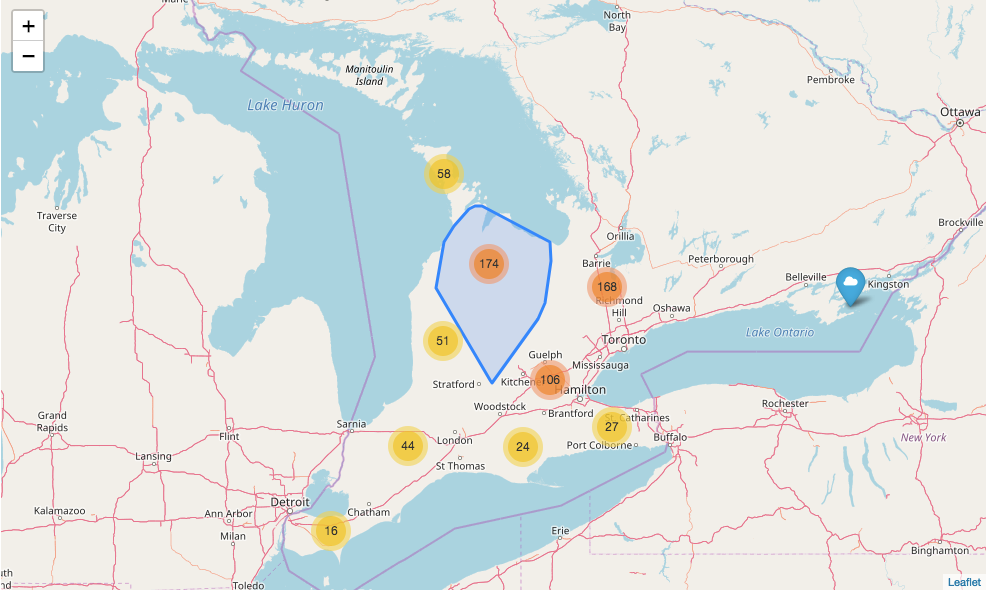

More clusters inside.

On the other hand, you might notice that there is a blue marker on the map which is actually the outlier not included in the cluster.
Overall, this is just a brief interlude where the exciting part is on the Google map.
Firstly, we have to configure the Google map with its API key in order to do the map visualization on Python and the API key can be obtained from the Google console. Once the configuration part has been completed, we are good to go. The Google map visualization contains three parts where each of them is correlated.
The first part is about searching lakes along with its key information. We write a couple of functions which allows you to enter text into the input and will return the information and location of those lakes, which contains the characters you type. If the results not found, you will have to type it again.
It just works like that.
The second part is about getting the direction, distance, and duration between your current location and the lakes you searched for previously. It will ask you to enter the address, city, and country to set up your current location. You can also select the mode from one of: driving, walking, bicycling, and transit to get there.
This is how it looks like.
The final part is to show the density of lakes and fish species by using a heat map.
Here is the heat map for the distribution of lakes.
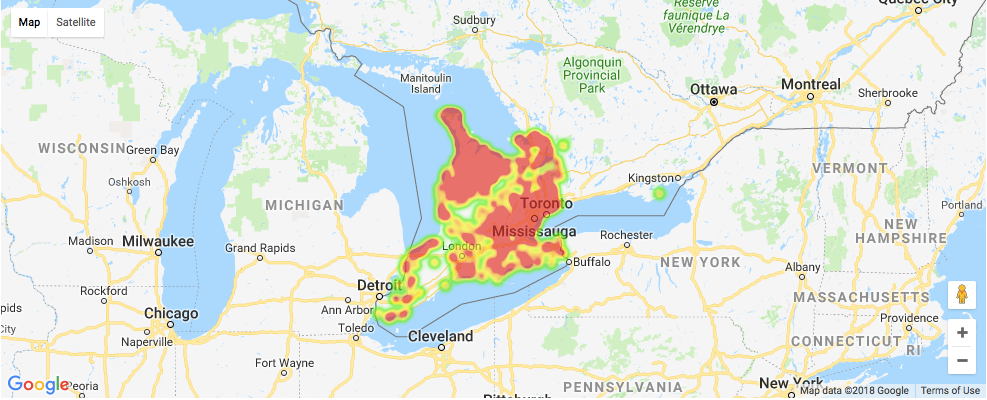

Take a closer look at the heat map for the distribution of each fish species.
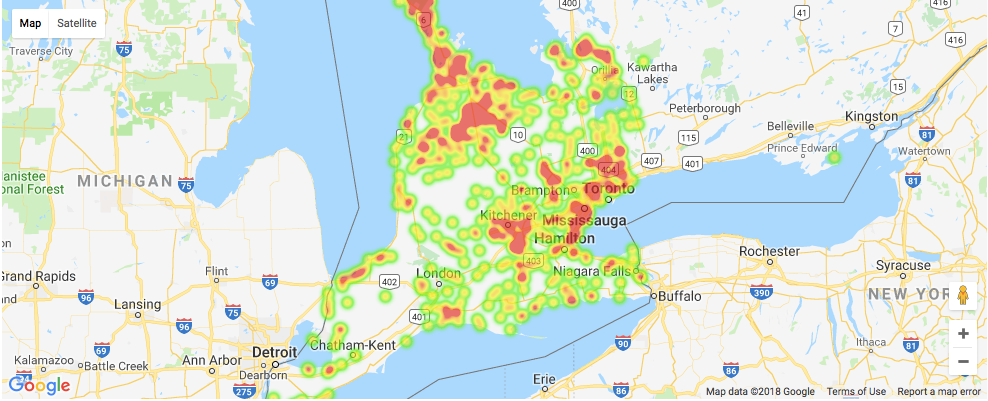

You will see a dictionary where its keys are an integer starting from 1 and the corresponding values are a different type of fish species. All you need to do is enter the integer to get the heat map for the corresponding fish species.
Here is the demo.
So that concludes our project. If you are interested in trying it out, you can visit the following GitHub link.
To see Weichen’s original blog post please click here. To follow and see Weichen’s latest blog posts, please click here.
To find out more about the courses our students have taken to complete these projects and what you can learn from WeCloudData, click here to see our upcoming course schedule.
