The credit score is a numeric expression measuring people’s creditworthiness. The banking usually utilizes it as a method to support the decision-making about credit applications. In this blog, I will talk about how to develop a standard scorecard with Python (Pandas, Sklearn), which is the most popular and simplest form for credit scoring, to measure the creditworthiness of the customers.
Project Motivation:
Nowadays, creditworthiness is very important for everyone since it is regarded as an indicator of how dependable an individual is. In various situations, service suppliers need to evaluate customers’ credit history first and then decide whether they will provide the service or not. However, it is time-consuming to check the entire personal portfolios and generate a credit report manually. Thus, the credit score is developed and applied for this purpose because it is time-saving and easily comprehensible.
The process of generating the credit score is called credit scoring. It is widely applied in many industries especially in the banking. The banks usually use it to determine who should get credit, how much credit they should receive, and which operational strategy can be taken to reduce the credit risk. Generally, it contains two main parts:
- Building the statistical model
- Applying a statistical model to assign a score to a credit application or an existing credit account
Here I will introduce the most popular credit scoring method called scorecard. There are two main reasons why the scorecard is the most common form of credit scoring. First, it is easy to interpret for people who have no related background and experience, such as the clients. Second, the development process of the scorecard is standard and widely understood, which means the companies don’t have to spend much money on it. A sample scorecard is shown below. I will talk about how to use it later.

Data Exploration and Feature Engineering:
Now I’m going to give some details about how to develop a scorecard. The dataset I used here is from the Kaggle competition. The detailed information is listed in the Figure-2. The first variable is the target variable, which is a binary categorical variable. And the rest of the variables are the features.
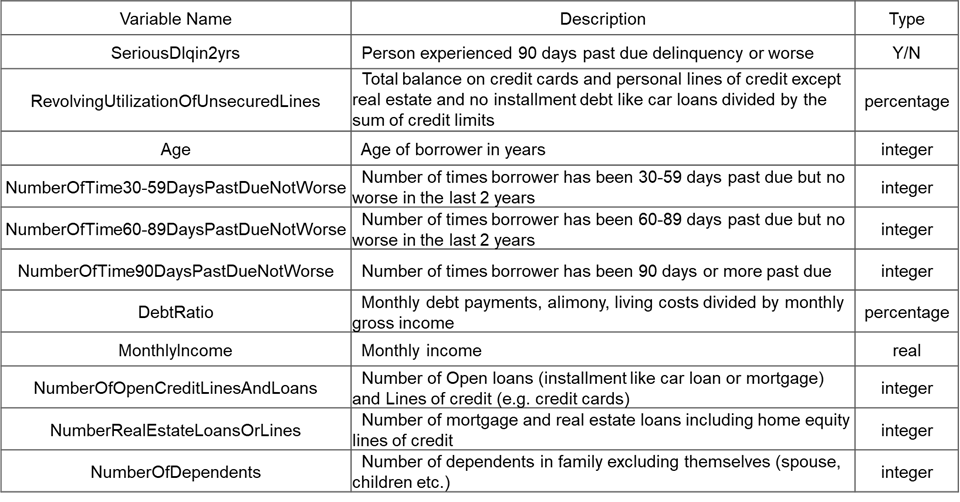
After gaining an insight into the data set, I start to apply some feature engineering methods on it. First, I check each feature if it contains missing values, and then impute the missing values with median.
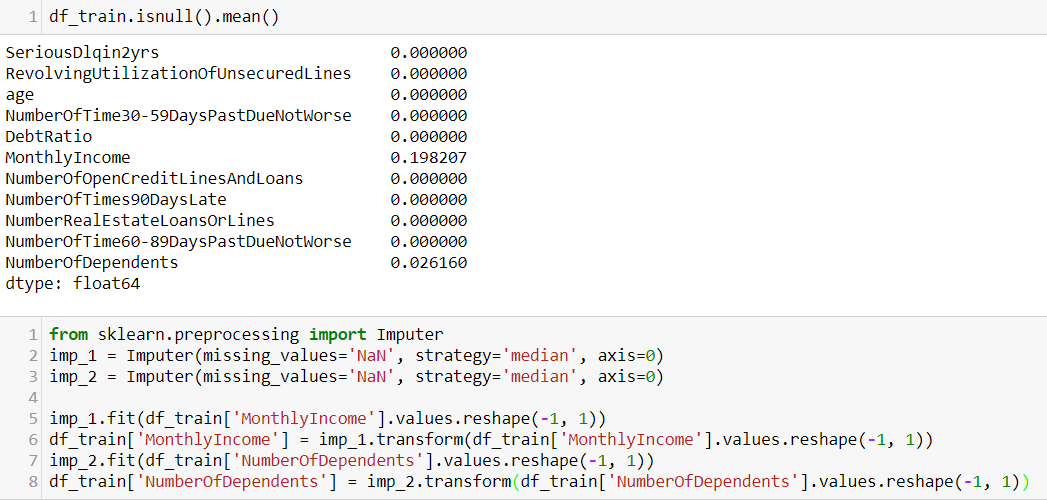
Next, I do the outlier treatment. Generally, the methods used for outliers depends on the type of outliers. For example, if the outlier is due to mechanical error or problems during measurement, it can be treated as missing data. In this data set, there are some extremely large value, but they are all reasonable values. Thus, I apply top and bottom coding to deal with them. In Figure-3, you can see after applying the top coding, the distribution of the feature is more normal.
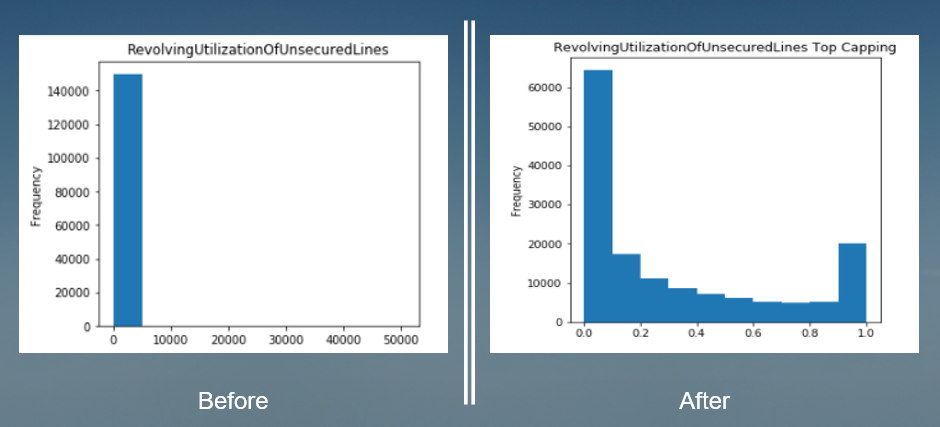
According to the sample scorecard shown in Figure-1, it is obvious that each feature should be grouped into various attributes (or groups). There are some reasons for grouping the features.
- Gain an insight into relationships attributes of a feature and performance.
- Apply linear models on nonlinear dependencies.
- Understand deeper on the behaviours of risk predictors, which can help in developing better strategies for portfolio management.
Binning is a proper method used for this purpose. After the treatment, I assign each value to the attribute in which it should be, which also means all numeric values are converted to categorical. Here is an example of the outcome of binning.
After grouping all the features, the feature engineering is completed. Next step is to calculate the weight of evidence for each attribute and the information value for each characteristics (or feature). As mentioned before, I have used binning to convert all numeric value into categorical. However, we cannot fit model with these categorical values, so we have to assign some numeric values to these groups. The purpose of the Weight of Evidence (WoE) is exactly to assign a unique value to each group of categorical variables. The Information Value (IV) measures predictive power of the characteristic, which is used for feature selection. The formula of WoE and IV is given below. Here the “Good” means the customer won’t have serious delinquency or target variable is equal to 0, and “Bad” means the customer will have serious delinquency or target variable is equal to 1.
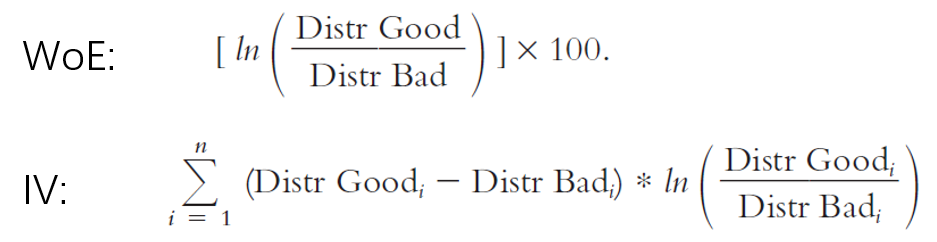
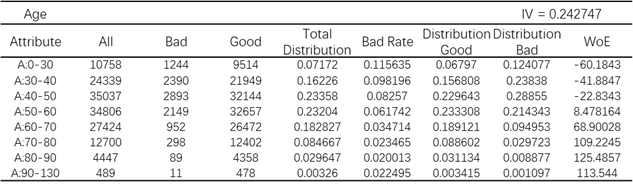
Usually, characteristics analysis reports are produced to get WoE and IV. Here I define a function in Python to generate the reports automatically. As an example, the characteristics analysis report for “Age” is shown in Figure-5.
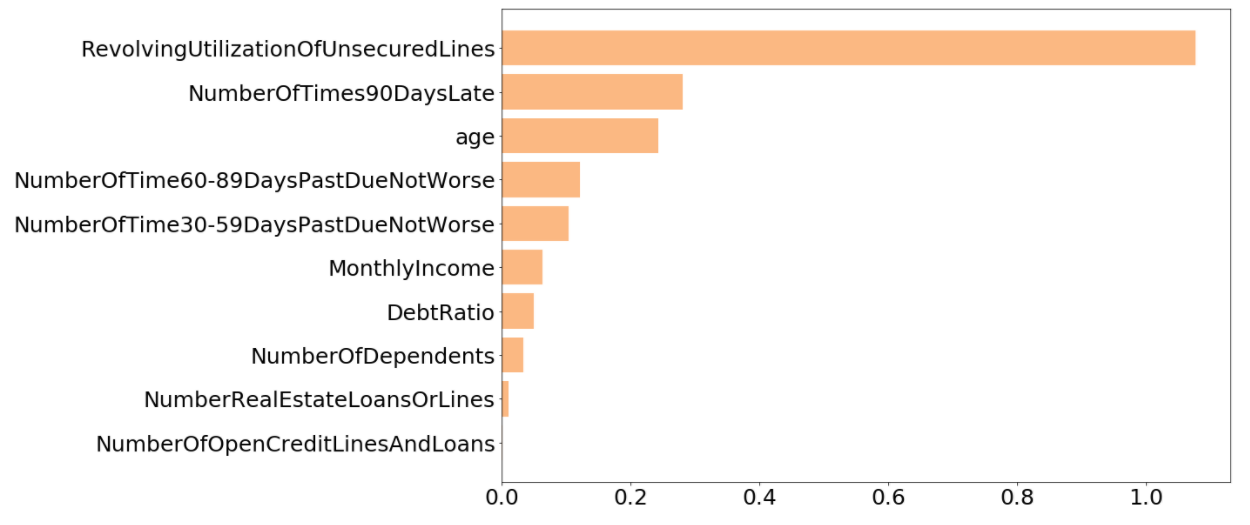
Then I make a bar chart to compare the IV of all the features. In the bar chart, you can see the last two features “NumberOfOpenCreditLinesAndLoans” and “NumberRealEstateLoansOrLines” have pretty low IV, so here I choose other eight feature for model fitting.
Model Fitting and Scorecard Point Calculation:
After the feature selection, I replace the attributes with the corresponding WoE. Until now, I get the proper data set for the model training. The model used for developing scorecard is a logistic regression, which is a popular model for binary classification. I apply cross-validation and grid search to tune the parameters. Then, I use the test data set to check the prediction accuracy of the model. Since the Kaggle won’t give the values for target variable, I have to submit my result online to obtain the accuracy. To show the effect of data processing, I train the model with raw data and the processed data. Based on the result given by the Kaggle, the accuracy is improved from 0.693956 to 0.800946 after the data processing.
The final step is calculating the scorecard point for each attribute and produce the final scorecard. The score for each attribute can be calculated with the formula:
Score = (β×WoE+ α/n)×Factor + Offset/n
Where:
β — logistic regression coefficient for characteristics that contains the given attribute
α — logistic regression intercept
WoE — Weight of Evidence value for the given attribute
n — the number of characteristics included in the model
Factor, Offset — scaling parameter
The first four parameters have already been calculated is the previous part. The following formulas are used for calculating factor and offset.
- Factor = pdo/Ln(2)
- Offset = Score — (Factor × ln(Odds))
Here, pdo means points to double the odds and the bad rate has been already calculated in the characteristics analysis reports above. If a scorecard has the base odds of 50:1 at 600 points and the pdo of 20 (odds to double every 20 points), the factor and offset would be:
Factor = 20/Ln(2) = 28.85
Offset = 600- 28.85 × Ln (50) = 487.14
When finishing all the calculation, the process of developing the scorecard is done. Part of the scorecard is shown in Figure-7.
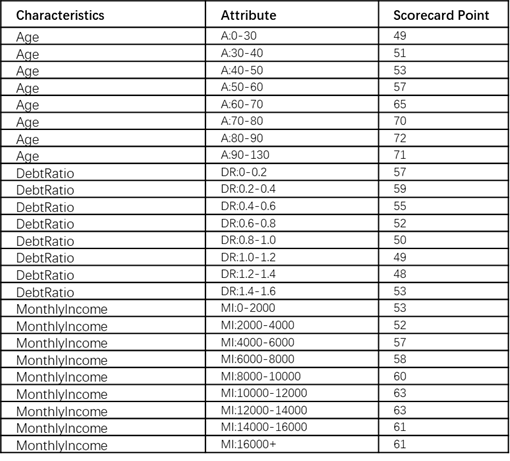
When you have new customers coming, you just need to find the correct attribute in each characteristic according to the data and get the score. The final credit score can be calculated as the sum of the score of each characteristic. For instance, the bank has a new applicant for a credit card with age of 45, debt ratio of 0.5 and monthly income of 5000 dollars. The credit score should be: 53 + 55 + 57 = 165.
To develop a more accurate scorecard, people usually have to consider more situations. For example, there are some individuals identified as “Bad” in the population but their application is approved, while there will be some “Good” persons that have been declined. Thus, reject inference is supposed to be involved in the development process. I don’t do this part because it requires the data set of rejected cases which I don’t have in my data. If you want to know more about this part, I highly recommend you to read Credit Risk Scorecards — Developing and Implementing Intelligent Credit Scoring written by Naeem Siddiqi.
This blog is posted by WeCloudData’s Data Science Immersive Bootcamp student Hongri Jia (Linkedin)
To see Hongri’s original blog post please click here. To follow and see Hongri’s latest blog posts, please click here.
To find out more about the courses our students have taken to complete these projects and what you can learn from WeCloudData, click here to see our upcoming course schedule.
