In the modern tech-driven business environment, making quicker and informed decisions is key to staying ahead of the competition. However, extracting valuable timely insights from an organization’s data is a difficult task. Data volume is expanding along with data sources like SaaS applications, IoT devices, and other external data resources. How to bring together data from these multiple sources? The answer is by building Data Pipelines.
Let’s learn more about Data Pipelines with WeCloudData. WeCloudData is a leading data and AI training academy. We offer many courses related to AI, Machine Learning, Generative AI, Data Engineering and computer vision. We also provide practical project based courses on Python (basic to advanced), SQL and data visualization with Tableau, PowerBI. We offer hybrid learning with mentorship.
In this blog, we’ll explore what data pipelines are, their importance, how data pipelines work, and their benefits for modern businesses.
What is a Data Pipeline?
A data pipeline is like algorithms providing a set of actions for moving raw information from multiple sources to a information store such as a information warehouse while transforming and optimizing it along the way. Think of a data pipeline as a conveyor belt that transports raw material (information) through different phases of refinement until it’s ready for use.
Raw data hold no value, it must be moved, filtered, transformed and analyzed for the decision making. Many big data projects like exploratory data analysis, data visualization and computer vision tasks are supported by well-organized data pipelines. Data pipelines are an important part of data engineering and have multiple use cases in domains like healthcare, finance, and e-commerce. Whether it’s a information warehouse, dashboard, or machine learning model, data pipelines ensure that information moves smoothly from its origin to its final destination.
Why Are Data Pipelines Important?
Organizations are flooded with information from a variety of sources. Meaningful insights are almost impossible to obtain without an organized method of handling this enormous amount of data (big data). Here are some factor highlighting Data pipelines importance:
- Centralized Data Access: It create a single source of truth for information analysis by combining information from multiple sources.
- Better Data Quality: it guarantee that the information is accurate and consistent by automating information transformation and cleaning.
- Scalability: Without impacting performance, it can be expanded to accommodate increasing workloads as information volumes increase.
- Automation: By eliminating the need for manual intervention, it minimize errors and save time.
- Faster Decision-Making: Businesses can make well-informed decisions quickly when reliable and timely data is available.
How Does a Data Pipeline Work?
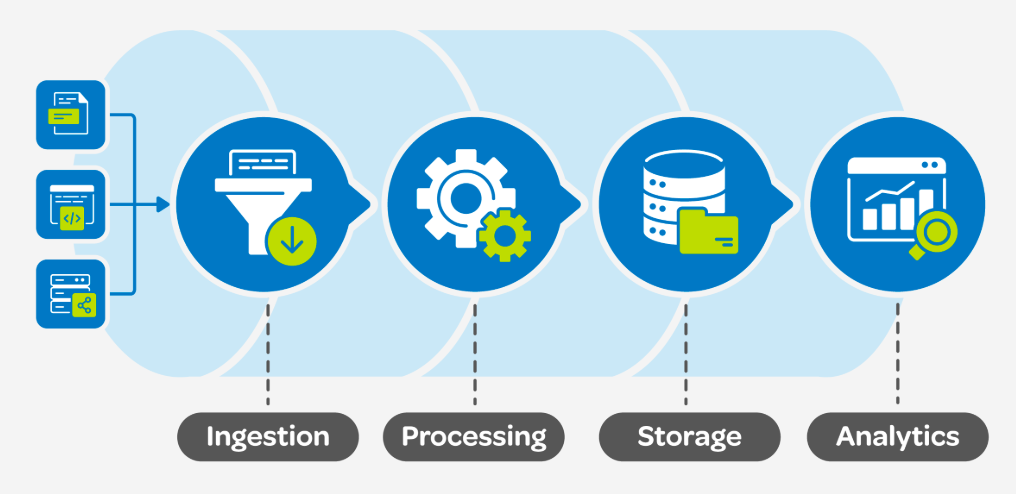
To understand how data pipelines work we need to understand the process. A data pipeline consists of several processes each designed to handle a specific task in the information journey. Let’s explore the critical components of data pipeline architecture below.
Data ingestion
Data ingestion is the first process in the data pipeline. At this stage the structures or unstructured data is collected from various data sources like IoT devices, SaaS (software -as-a-service) programs and mobile devices. Various validations are performed at data ingestion stage to make sure data is accurate and consistent.
Data Transformation
Data Transformation is needed to change raw data into usable format compatible with the destination data repository. At this stage data is sorted, reformatted, filtered, verified and validated. Technologies like Apache Spark , and ETL (Extract, Transform, Load) tools are used for processing.
Data Storage
The next stage is the data storage , where transformed data is stored within a data repository. The data repositories include, data warehouse, data lake or databases. Popular data storage services include Amazon Redshift, Snowflake, Google BigQuery, Snowflake, and Hadoop.
Data Consumption
The data pipeline process ends with making the information available to end-users, such as data analysts, data scientists, or business intelligence tools. Visualization tools like Tableau and PowerBI help users interpret the data.
Types of Data Pipelines
Data pipelines can be categorized based on their functionality and use cases:
Batch Processing Pipelines
As the name implies in batch processing pipeline, information is loaded in “batches” into a repository at scheduled intervals (e.g., daily or hourly). Batch processing pipelines are ideal for the use cases where real-time processing isn’t required, such as generating monthly reports.
Real-Time Processing Pipelines
Real-time processing pipelines use cases include fraud detection, IoT monitoring , and live dashboards. These process information in real-time as soon as it’s generated, enabling instant insights.
ETL Pipelines
ETL pipelines are used in information warehousing and business intelligence. ETL (Extract, Transform, Load) pipelines are designed to extract information from sources, transform it into a usable format, and load it into a destination system. To learn more about ETL follow this link.
ELT Pipelines
With the growth of cloud information warehouses, ETL pipeline strategy is becoming more and more popular. ELT (Extract, Load, Transform) pipelines load information into destination before performing information transformation on raw information.
Real-World Applications of Data Pipelines
Data pipeline have multiple case studies in different domain , here are some of the real-world applications listed below;
Healthcare: Well built medical information processing enhances treatment results, facilitating predictive analytics, and processing patient information.
Marketing: In the marketing world helps in monitoring campaign effectiveness, customizing client interactions, and calculating return on investment.
IoT: For IoT devices, it helps in tracking device performance, detecting maintenance requirements, and streamlining processes.
Ready to Start Your Data Career?
Join WeCloudData and gain hands-on experience in Data Engineering or Data Science with industry experts. Our bootcamps prepare you for real-world challenges, ensuring career success.
Explore our programs here!
