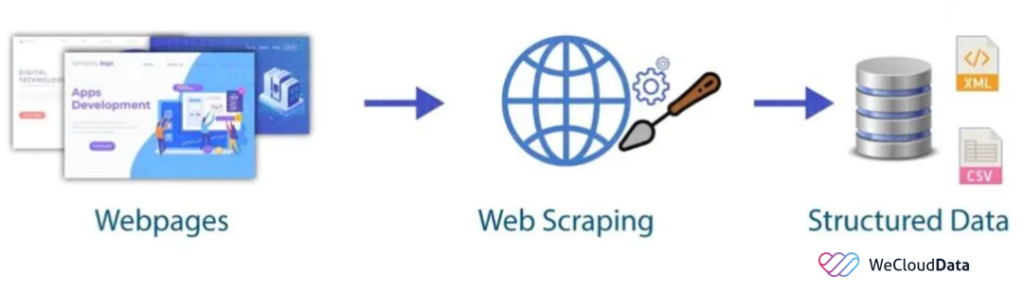
Web scraping is searching and extracting data from web pages over the internet using different scraping tools. The formal definition of web scraping is “An automated method used to extract large amounts of data from websites.” Python is one of the top choices for web scraping because it has many libraries that can handle complex HTML structures, parse text, and interact with web forms.
In this blog, we will learn web scraping by following a case scenario. We will explore how to do web scraping using Python and how web scraping works. Let’s get started with WeCloudData!
How does Web scraping work?
Web scraping is a powerful technique that allows data extraction from websites automatically. This data can include images, text, tables, and more. The process of scraping involves sending a request to a website, parsing the HTML code of that website, extracting the relevant data, and storing it in data frames, CSV files, or XML files. Web scraping saves time and resources along with providing valuable insights from the data. It is used in a variety of applications across multiple domains including;
- Data Analysis
- Content Aggregation
- Competitor Analysis
- Machine Learning
Why Use Python for Web Scraping?
Python is a versatile programming language and is the first choice of programmers for data scraping due to its simplicity and the availability of powerful libraries. Following are some of the many reasons Python is preferred over other languages;
- Easy to Learn: Python’s syntax is beginner-friendly, making it learnable for beginners.
- Rich Libraries: Libraries like BeautifulSoup, Requests, and Scrapy are Python libraries that are specifically designed for data scraping.
- Versatility: Python is versatile and can handle everything from simple scraping tasks to complex, multi-page scraping projects.
- Community Support: Python has a large and active community, so you’ll find plenty of tutorials, forums, and resources to help you.
Python Libraries for Data Scraping
Python offers multiple libraries for data scraping but we will only cover these libraries in this blog.
BeautifulSoup
BeautifulSoup is ideal for processing documents in XML and HTML formats. It provides a simple API to quickly sift through a document’s structure to extract elements like tags, meta titles, and texts. It is recognized for its strong error-handling features, which make it easier to deal with messy web data.
Request
The request library is famous for its simplicity and strength when submitting HTTP requests. Sending requests, managing cookies, handling authentication, and more are all made simple by Request’s clear and simple API.
Getting Started with Web Scraping in Python
Here’s a simple and easy-to-follow tutorial on how to use Python for web scraping. For this web scraping project we will use Google Collab, Request, BeautifulSoup, Pandas, and Times libraries.
Select the Website
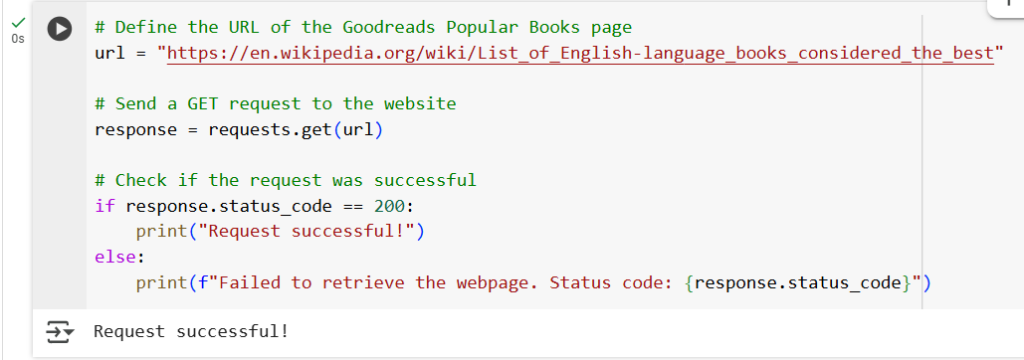
The first step in web scraping is choosing the website for scraping. In this tutorial, we will scrap data related to the “List of English-language books considered the best ”. Here is the link for the webpage we will scrape data from.
Understand the Website Structure
The next step is to check the website’s layout. To inspect the HTML code, right-click on the page and choose “Inspect”. Use the inspector tool to identify the names of the elements you’ll need for your scraping code. Note the class names and IDs of these elements as the Python code will use them.
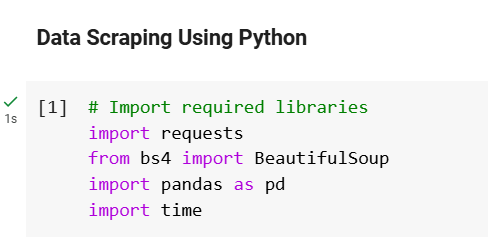
Import Required Libraries
We will use these Python libraries to scrape the website efficiently:
- Requests: For sending HTTP requests to the website.
- BeautifulSoup: For parsing the HTML code and extracting data.
- Pandas: For organizing the scraped data into a structured format.
- Time: For adding delays between requests to avoid overloading the website.
Send a Request to the Website
Use the ‘requests’ library to send an HTTP request to the website and retrieve its HTML content. Below is the code for sending requests to the website.
Parse the HTML Content
Now that our request status is successful we have access to the content on the webpage next step is to parse that content. We will use ‘BeautifulSoup’ to parse the HTML content and extract the data we require.

Identify Table
By following the link we get that the list of books is in the form of a table so we need to identify the table first. The code attempts to locate the table right after the “List” section header. If that fails, it falls back to the first table with the class wikitable.

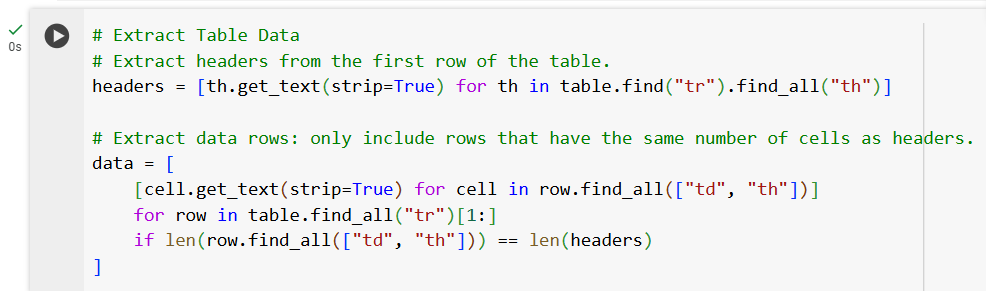
Extract Table Data
Now we find the table next step is to extract the book’s data from the table. The headers are extracted from the first table row, and then each subsequent row is processed if it has the same number of cells as the header.
Create a Pandas Data Frame From the Data
The data is then loaded into a pandas DataFrame using this line of code.
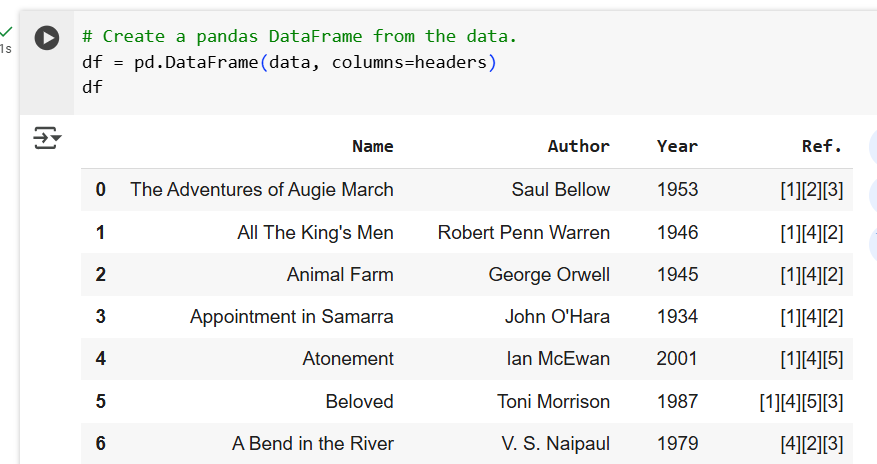
Save the Table Data
Finally will save the data in a CSV file for further analysis. This is the last step in the data scraping project.
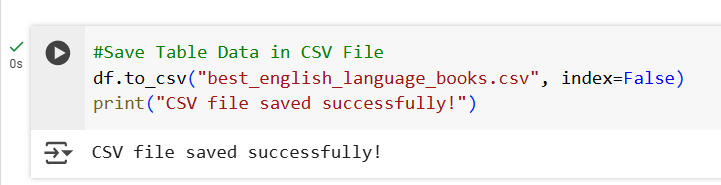
Hurrah! You’ve just completed your first project consisting of web scraping with python! 🎉 It was a fun and rewarding journey, wasn’t it?
Learn Through Engaging Video Tutorials
WeCloud Data also offers a curated YouTube video on web scraping financial data. This workshop is a fantastic resource that provides:
- Step-by-Step Guidance: Walk through the entire process of scraping financial data from online sources.
- Advanced Techniques: Understand how to apply data scraping in the financial domain, an essential skill for analysts and data enthusiasts.
- Complementary Learning: Enhance your understanding of data scraping techniques that are covered in WeCloudData’s Python Fundamental Course.
Unlock Your Potential with WeCloudData
Choosing WeCloud Data means choosing a partner who is committed to your growth. With their immersive python training programs, comprehensive Python courses and engaging video tutorials, you’re well-equipped to navigate the world of data and unlock endless opportunities. What WeCloudData offers;
- Hands-On Learning: The course emphasizes practical, hands-on learning with real-world examples.
- Expert Instructors: Learn from industry professionals with years of experience in Python and data science.
- Flexible Learning: The course is available online, making it easy to learn at your own pace.
- Career Support: WeCloudData offers career services to help you land your dream job after completing the course.
Embrace the journey, enhance your skills, and transform your career with WeCloud Data today!
