Natural Language Processing (NLP) has transformed technology by allowing machines to understand, decode, and generate human language. NLP plays a crucial role in multiple domains and NLP projects ranging from it’s automating customer service, improving search engines, or analyzing social media sentiments.
In this blog, we will use a case study-Automated Resume Screening to understand and explore the life cycle of an NLP project. Let’s get started with WeCloudData!
What is NLP?
Before we get into the NLP life cycle, let’s define what NLP stands for. NLP, or Natural Language Processing, is a subfield of artificial intelligence that studies the interaction between computers and human language. In particular, NLP is leading the era of Generative AI. From the ability of image generation models to the assistance skills of LLM like ChatGPT, Natural Language Processing is part of our day-to-day activities. Other examples powered by NLP include chatbots for customer service with spoken commands, and digital assistants like Amazon’s Alexa, and Apple’s Siri.
A Case Study: Resume Screening for Recruitment
Assume you work for a company that receives hundreds of job applications for multiple vacancies. Manually sorting and shortlisting resumes takes time and is prone to bias. The company has decided to develop an NLP project to automate resume screening. Let’s walk through the NLP life cycle for this project.
Problem Definition and Goal Setting
The first step in the NLP life cycle is to define the problem that needs a solution because every successful NLP project plan starts with a clear understanding of the problem.
Problem Definition: The problem is that manual resume screening is slow and inconsistent and there is a need for a well-trained NLP model that can automate the process and shorten hiring time.
Goal Setting: This project aims to extract critical details from resumes (e.g. skills, experience, education), match individuals to job descriptions and rank resumes according to relevancy.
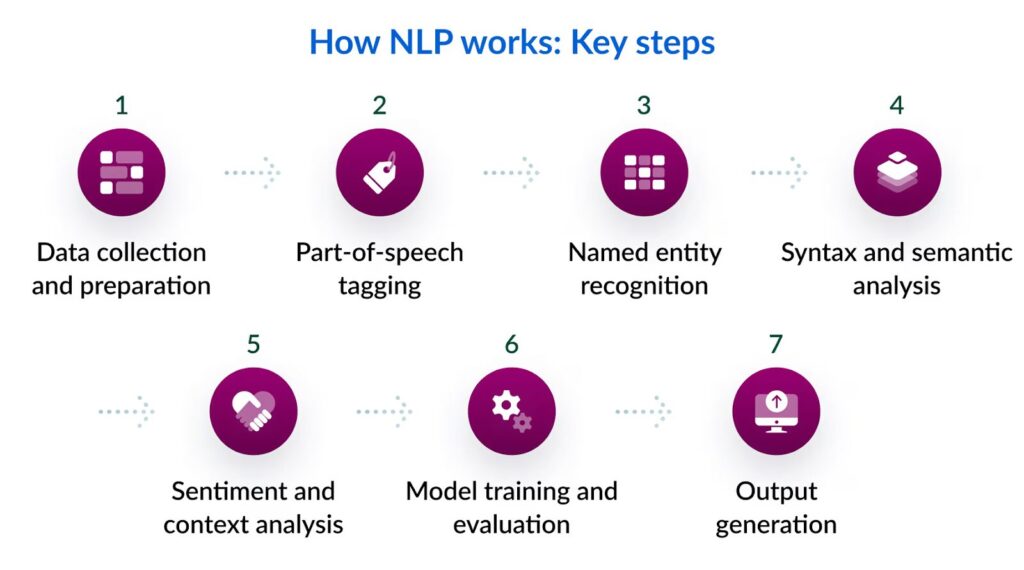
Data Collection and Preprocessing
Step 1: Data Collection
Data is the backbone of any NLP project. Therefore, for the successful creation of resume screening software, we need to ensure the data is clean, labeled, of good quality and representative of all categories.
good quality and rich data.
Task: To collect resumes in various formats (PDF, Word, etc.) along with their corresponding job descriptions.
Tools: Use web scraping, APIs, or internal databases to collect data.
Raw text data is messy. Preprocessing is essential to make it usable.
Step 2: Data Preprocessing
Raw data is messy so you cannot use it directly. Clearly, it needs to be cleaned and preprocessed to make it useful. Here are the key step that will be followed in data preprocessing step.
- Text Extraction: Convert resumes from PDF or Word formats into plain text.
- Tokenization: Break text into words or sentences.
- Lowercasing: Convert all text to lowercase for consistency.
- Removing Stopwords: Eliminate common words like “the” or “and.”
- Lemmatization: Reduce words to their base forms (e.g., “managed” to “manage”).
The outcome is clean, structured data ready for analysis. Here is an example of data preprocessing.
Example raw resume text:
“Experienced Data Scientist with 5+ years of expertise in Python, SQL, and Machine Learning.”
After preprocessing:
“experience data scientist years expertise python SQL machine learning”
Part-of-Speech (POS) Tagging
Part-of-speech (POS) tagging is a natural language processing technique that involves assigning specific grammatical categories or labels (such as nouns, verbs, adjectives, adverbs, pronouns, etc.) to individual words within a sentence. In this scenario, POS helps recognize skills, job titles, and experience.
Example:
“Python programming is essential for a Data Scientist role.”
POS tagging → Python (Noun), programming (Verb), essential (Adjective), Data Scientist (Noun)
This stage assists in filtering out irrelevant terms and focusing on relevant resume information.
Named Entity Recognition (NER)
Named entity recognition (NER) is a natural language processing method that extracts information from text. NER involves detecting and categorizing important information in text known as named entities. Particularly in this scenario, important entity extraction includes job titles, skills, company names, and locations. NER helps categorize resumes based on required qualifications
Example:
“Worked at Microsoft as a Principle Software Engineer with experience in NLP.”
Identified Entities:
- Company: Microsoft
- Job Title: Principle Software Engineer
- Skill: NLP
Using NER, we can match resumes with job descriptions more effectively.
Syntax and Semantic Analysis
The syntax is the grammatical structure of the text, whereas semantics is the meaning being conveyed. Syntax and semantic analysis is a technique in NLP that analyzes sentence structure to understand meaning and relationships. In this scenario, the analysis helps interpret context (e.g., distinguishing “Python developer” from “worked with Python”)
Example:
“Python is used in data science.”
Semantic understanding: Python (programming language)
“I worked at Python Technologies.”
Semantic understanding: Python (company name)
Sentiment and Context Analysis
Sentiment and context analysis in Natural Language Processing are the techniques utilized to understand the emotional tone and meaning of text. In the given scenario the analysis helps to understand the candidate’s tone, confidence, and experience level and rank candidates based on assertiveness, leadership tone, and keywords.
Example:
“Led a team of 10 engineers to develop an AI system.”
Strong leadership signal → Higher rank
“Worked on some AI projects.”
Weak confidence signal → Lower rank
By performing sentiment and context analysis better candidate selection is ensured.
Model Training and Evaluation
The model training process involves selecting the appropriate model for training. There are multiple choices for NLP models, including rule-based, statistical, and deep-learning models. Some common techniques include TF-IDF, Word2Vec, and BERT. Each model selection depends on the specific task and the complexity of the data.
Additionally, to evaluate the performance of the model performance metrics like accuracy, precision, recall, and F1-score will be used.
Output Generation
Once the model performs well, it’s time to deploy and integrate it with the company’s applicant tracking system (ATS) to automatically screen incoming resumes. At this stage the final ranked list of candidates is being made from the resumes. Recruiters will receive shortlisted resumes based on relevance. The resume screening tool provides explanations for rankings (e.g. why a candidate is a good fit).
How Can WeCloudData Help With NLP
WeCloudData is offering a specialized Natural Language Processing (NLP) course that covers foundational concepts, deep learning techniques, and hands-on projects with real-world datasets. Especially, this course is ideal for professionals aiming to build careers in AI and NLP. Enroll and create and build your own NLP Projects.
Python is the backbone of modern Natural Language Processing due to its extensive libraries and frameworks. Whether it’s training large language models, performing text preprocessing, or deploying NLP applications, Python remains the go-to language for developers and researchers.
At WeCloudData, we understand the significance of Python in AI and data science, which is why we offer comprehensive Python courses alongside our NLP program. After all, these courses are for beginners and professionals build strong programming foundations for AI and machine learning applications.
What WeCloudData Offers?
WeCloudData not only offers short courses but also provides a comprehensive range of resources to support your learning journey. In addition, these include live public training sessions led by industry experts, career workshops to prepare you for the job market, dedicated career services, and portfolio support to help showcase your skills to potential employers.
Join WeCloudData to kickstart your learning journey and unlock new career opportunities in the era of AI.
