Imagine you’re a data scientist or data analyst working for an airline. The marketing team noticed that there is a lot of feedback posted on X. The airline’s reputation is at stake as customer satisfaction is very important. They consult you to analyze the sentiment of posts to understand what’s going wrong and how to fix it.
But here is the issue. The data they provided is raw, and messy and has emojis, typos, hashtags, and mentions. Data professionals can not use raw data to get productive results as the saying goes “garbage in, garbage out”. Before analyzing what passengers think, data needed to be clean. The process of changing raw data into a clean, usable format for analysis is known as Data Wrangling.
Let’s learn about how to perform Data Wrangling with Python with WeCloudData!
What is Data Wrangling?
Data wrangling refers to the steps and processes taken to transform raw data into usable formats for further data analysis. It can include combining or separating data sources, removing or filling in missing/outliers data, transforming the structure of the dataset, and other strategies used to ensure the data is of high quality and safeguard the integrity of the data analysis. Why? Because garbage in, garbage out – having clean and useable data is the foundation of valid and reliable data analysis.
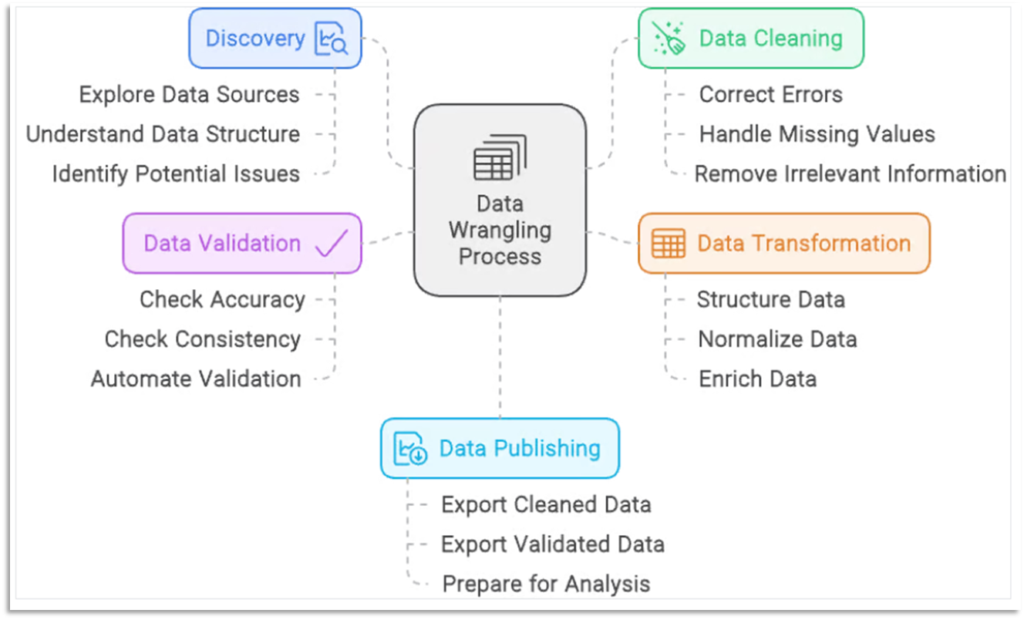
Data Wrangling Steps and Techniques
The data world is expanding rapidly, it is essential to use the right data to organize and use for analysis. Clean, well-presented data serves as the foundation for all subsequent steps in the data workflow. The lifecycle of data wrangling follows these simple steps.
Data Discovery: The basic and most important part of the data wrangling process involves data understanding (data source, structure, and potential issues). Before moving towards data cleaning, a data scientist must know about the data they are dealing with.
Data Cleaning: In this phase irrelevant information is removed, the issue of missing values is resolved, and any other errors are eliminated. This ensures data accuracy and reliability.
Data Transformation: Data transformation modifies data to support the need for analysis. It includes data aggregation from multiple sources, data normalization, and converting data types.
Data Validation: Validation of data means data is in the correct format, clean, and can be used for further analysis.
Data Publishing: Making cleaned and verified data available for additional use and analysis is the last step in data wrangling.
Step-by-Step Guide to Data Wrangling with Python
To perform data wrangling we use open source data from Kaggle named Twitter US Airline Sentiment Dataset. We will be conducting data wrangling with Python throughout the tutorial. Python is one of the most popular tools for data wrangling due to its simplicity, versatility, and extensive libraries like Pandas, NumPy, and Matplotlib.
WeCloudData offers a well-structured course on Data Wrangling with Python, check it out here. At the end of this course, you will be able to work with essential libraries like Pandas and NumPy, manipulate DataFrames, and use powerful built-in functions to analyze and transform data.
Step 1: Setting Up Your Environment
Before starting the data wrangling we need to import the important libraries. These libraries will help with data manipulation, visualization, and text processing. We may need more libraries when we move further to the project but for now we are good.

Step 2: Loading the Dataset
The first step in data wrangling with Python is to load the dataset into a Pandas data frame. We’ll use the Pandas library to read the CSV file as our dataset is stored in a CSV file.

Step 3: Exploring the Dataset
Now we will explore the dataset before we move to data cleaning because before cleaning the data, it’s important to understand its structure and identify any issues. The purpose of exploring data is to help look at data before making any assumptions. It can help identify obvious errors, as well as better understand data patterns, detect outliers, and find interesting relations among the variables.
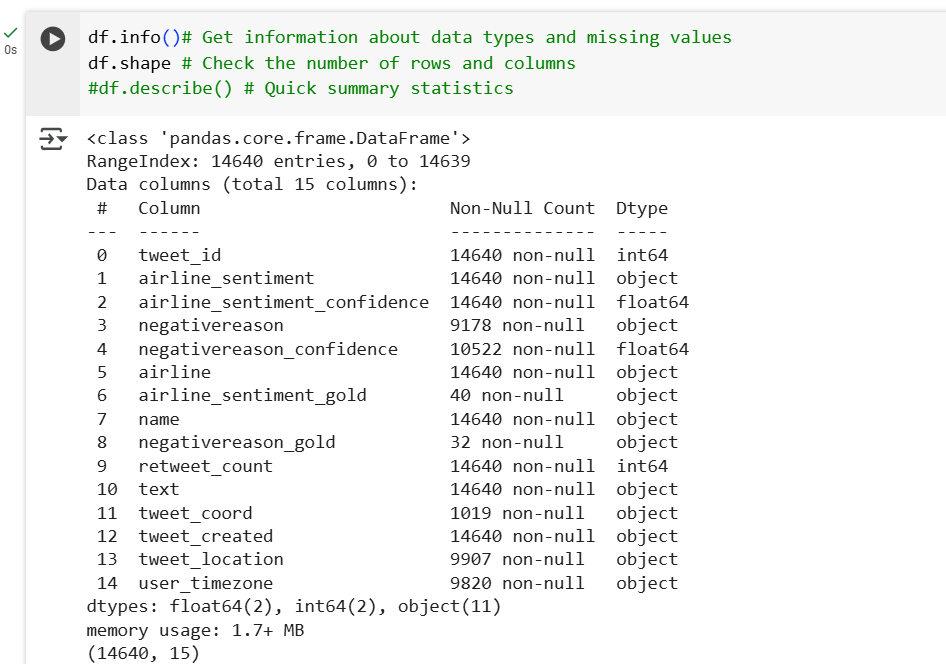
Step 4: Cleaning the Data
Handling Missing Values
During data cleaning, rows with missing values are dropped or replaced. Our focus is on the “text‘ column so we will drop the row which has missing values.

Remove Special Characters and Hashtags
Raw data is often messy, and cleaning it is a key part of data wrangling. Let’s clean the ‘text’ column, which contains the post’s content. The ‘text’ column has special characters like( !, #,^,( ), hashtags, URLs, and mentions. All of these need to be removed.

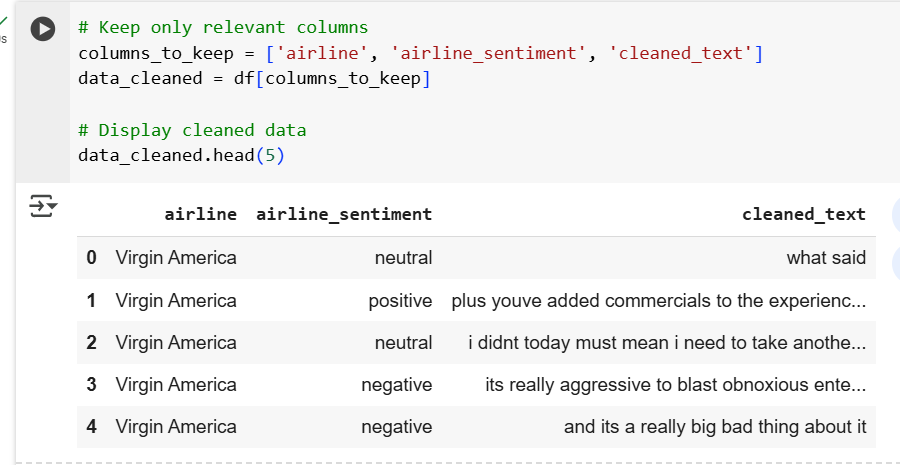
Removing Unnecessary Columns
As you can see using (df.head()), not all the columns contribute to the dataset, so we can remove the unnecessary columns and use only the ones that we need for analysis.
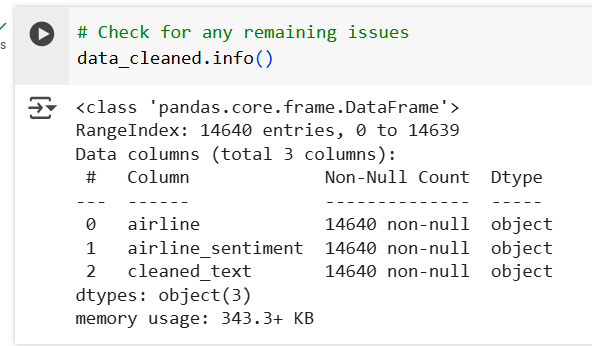
Step 5: Validating the Cleaned Data
After data cleaning, it’s important to validate the dataset to ensure it’s ready for further analysis.
Congratulations! You’ve just completed your first mini data wrangling project using Python. We’ve loaded, explored, and cleaned real-world X data, making it ready for sentiment analysis or further exploration. In our next blog, we’ll dive deeper into text-specific data wrangling techniques to prepare this data for advanced analysis.
Get Started with WeCloudData
If you’re interested in mastering more advanced data wrangling techniques, get your data wrangling certification with WeCloudData Data Wrangling Course with Python. Whether you’re looking to enhance your Python course in Toronto, or preparing for SQL, this course offers practical, hands-on experience that aligns with real-world data challenges.
Additional Resources:
- Python Language Course for beginners and advanced users.
- Data Visualization with Tableau and PowerBI to complement your wrangling skills.
Stay tuned for the next part of our series where we learn text data wrangling techniques!
