The world is becoming increasingly dependent on data, about 2.5 quintillion bytes of data are generated every day. Data is shaping our decisions, from personalized shopping experiences to checking weather forecasts before leaving home. All of these data science applications have a life cycle to follow. The data science lifecycle of a project outlines the key stages involved in executing a data science project from start to finish. Understanding this life cycle helps you plan, execute, and deliver successful Data science projects.
In this blog, we will understand the key stages of the data science life cycle, challenges, and real-world applications at each step. Let’s learn together with WeCloudData!
Understanding the Life Cycle of Data Science Project
The data science project life cycle provides a structured approach for data scientists to develop data-driven solutions that address specific business problems. It starts with understanding the business problem, and gathering data, followed by cleaning raw data and performing exploratory data analysis. After EDA machine learning models are selected and trained and after performing model evaluation the project is deployed in the real environment.
Elaborating With an Example
Do you remember your eCommerce platform experience when viewing products you see multiple related product details as well. The related product details appear with headlines like “frequently bought together” or “customers who bought this item also bought this…” This is the data science application that Amazon and other companies use to find product associations and cross-sell to new and existing customers.
Now let’s talk about the data science lifecycle this project follows. The first steps in the data science lifecycle for eCommerce recommendations are defining business problems (cross-selling) followed by data collection (clicks, purchases). Patterns (such as “laptops + mice”) are found by analyzing cleaned data (data cleaning, EDA), and product associations like “Frequently Bought Together” are produced via methods like collaborative filtering (ML Modeling). Real-time deployment of these models is followed by performance monitoring (model deployment and monitoring). Through individualized recommendations, this end-to-end data lifecycle transforms raw data into actionable insights that increase sales.
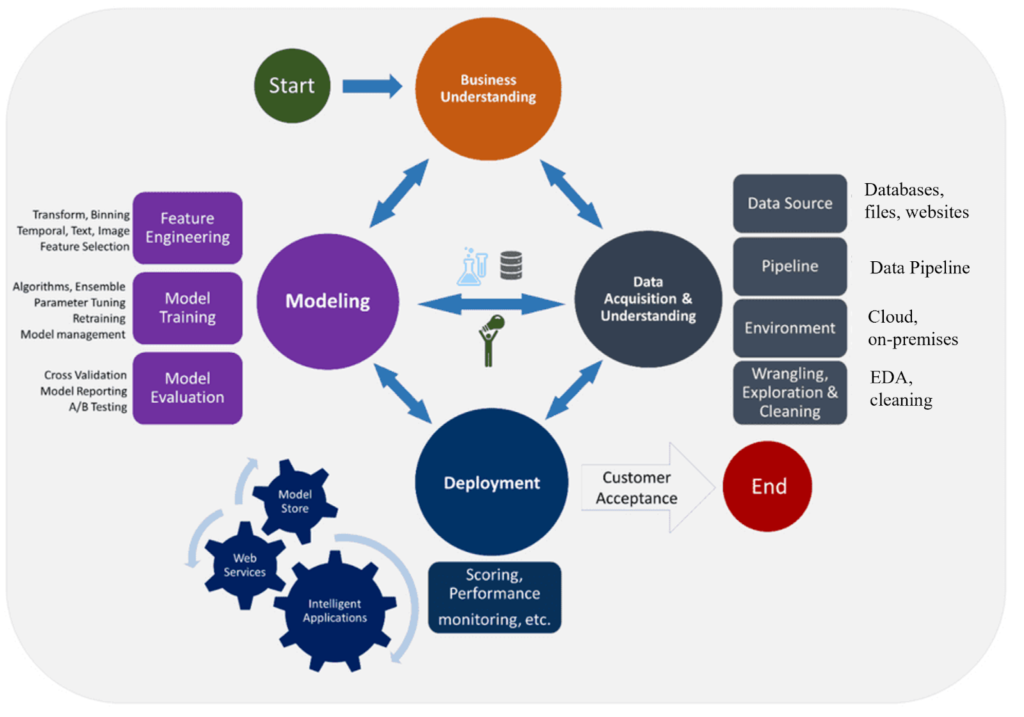
Stages of Data Science Life Cycle
A data scientist works on the entire data pipeline with the primary focus on extracting meaningful insights from the data. The 7 steps in the data science lifecycle, each stage is explained briefly below with relevant data science life cycle examples.
Business Problem Understanding
Before start working on any project the first thing that must be crystal clear is the problem you’re trying to solve. It’s very important to define the problem clearly and concisely. Understanding the business objectives and context ensures that data science efforts align with real-world needs and provide actionable solutions to the target problem. Some key questions that needed to be answered in this stage are:
- What is the problem statement?
- What are the business goals?
- What are the limitations?
Example
Take the example of an e-commerce company that has significant cart abandonment rates. Building a predictive model to detect clients who are likely to abandon their carts and recommend personalized solutions could be the data scientist’s goal in this scenario.
Data Collection
The next step after understanding and defining the problem is to collect the data. The quality of insights we get from the data depends upon the quality of the data itself. So it’s very important to ensure that the data is accurate, complete, and relevant to the problem being solved. Common data sources include websites, spreadsheets, databases, wearable devices, and smart sensors.
Example
For the e-commerce scenario, the data science team will collect data on customer demographics, past purchases, clickstream data, transaction history, and product information.
Data Cleaning and Preprocessing
Raw data is often messy, containing errors, missing values, or duplicates. Cleaning and preprocessing ensure the data is accurate and suitable for further use. Data transformation is also done in this stage which is transforming data into a desirable format suitable for the analysis. Python and SQL are the main tools used for data cleaning, manipulation, and transformation.
Example
In an e-commerce scenario data scientists may need to remove duplicate transaction records or fill in missing purchase history for some users.
Exploratory Data Analysis (EDA)
Now we have the clean data. The next step is to understand data features and properties, detect data patterns, and form a hypothesis before building a model. This step is known as Exploratory Data Analysis. EDA uses multiple techniques like univariate and bivariate analysis, descriptive statistics (Mean, median, mode), feature engineering, and correlation analysis.
Example
Performing customer segmentation based on purchase behavior. Or using regression analysis to identify the factors that influence customer purchase decisions.
Model Building and Evaluation
In the model building and evaluation stage, we build machine learning, deep learning, or computer vision models to solve the defined problem and evaluate the model performance. Data scientists develop models that can predict future outcomes using the insights gained from the data analysis at the EDA stage. Models’ performance is evaluated using some evaluation matrices like accuracy, precision, recall, and F1-score.
Example
For predicting cart abandonment from an e-commerce scenario, data scientists might use Logistic Regression or Random Forest models.
Deployment and Monitoring
Model deployment is the last stage in the life cycle of a data science project. In this stage predictive model is deployed into production so that it can be used to make predictions in the real environment. The deployment process involves integrating the model into the existing process and systems to ensure that it can be used effectively.
Example
E-commerce companies can deploy a real-time recommendation system suggesting discounts to users likely to abandon their carts and monitor them for any irregularities.
Get Started with WeCloudData
If you are looking for a Data Science training program: look at our Data Science Course to start your Data Scientist Journey today! Make an impact in the Data Scientist Job Market!
WeCloudData provides hands-on learning experiences, making complex Data Science concepts such as data science lifecycle easy to understand. Whether you’re looking for:
- Self-paced Courses to learn at your convenience.
- Public training sessions with expert instructors.
- Portfolio support to build projects that stand out.
- Career services to help you land your dream job.
WeCloudData equips you with everything you need to unlock new career opportunities in this exciting field.
