If you’re new to data science, you’ve probably heard of Scikit-learn before. And if you haven’t used it yet, you will because it’s one of Python’s most popular and reliable machine learning libraries.
At WeCloudData, we train aspiring data scientists, analysts, and engineers to use tools that deliver real-world value. Scikit-learn is often the first machine learning package we recommend, not just because it is user-friendly, but also because it is powerful enough to serve real-world use cases in startups, companies, and research labs.
In this blog post, we’ll discuss what makes Scikit-learn so important, how to start using it, what challenges it solves, and how you can master it with hands-on examples. Let’s get started.
What is Scikit-learn?
Scikit-learn, often referred to as sklearn, is a free and open-source machine learning library. It is built on top of other important Python Libraries like Matplotlib, SciPy, and NumPy, providing a comprehensive set of tools and algorithms for various machine learning tasks like regression and classification.
Why is it called Scikit-learn?
The name “Scikit” stands for “SciPy Toolkit.” Scikit-learn was initially developed as an extension to the SciPy ecosystem, specifically focused on machine learning. That’s why it’s formally called “scikit-learn” but imported as sklearn in Python code.
Why Scikit-learn Is So Widely Used
Scikit-learn is extremely popular. There are several reasons Scikit-learn has become a go-to tool for data scientists and engineers:
- Clean and consistent API
- Extensive documentation and active community
- It supports all major machine learning algorithms
- It integrates smoothly with Pandas, NumPy, and Matplotlib
- It offers a clean, intuitive API for rapid development
- It’s perfect for prototyping and learning core ML concepts
- It’s easy to install with pip install scikit-learn
How Many Models Are in Scikit-learn
Scikit-learn is a simple and efficient tool for predictive data analysis and is accessible to everybody and reusable in various contexts. It supports dozens of models for every major supervised and unsupervised learning technique. Model Scikit-learn offers include;
- Linear and logistic regression
- Decision trees and random forests
- K-nearest neighbors
- Support Vector Machines
- PCA and other dimensionality reducers
- K-Means and DBSCAN clustering
How to Start with Scikit-learn?
Getting started with Scikit-learn is easy. Just install the package using pip install scikit learn:

Once installed, you can start working with real datasets and models within minutes.
Breast Cancer Classification Using Scikit-Learn
In this section, we’ll walk through a realistic classification example using the scikit-learn library. We’ll use the Breast Cancer dataset, a built-in dataset in scikit-learn, and apply a Logistic Regression model to predict whether a tumor is malignant or benign based on various features.
The Dataset
We load a labeled dataset with measurements from digital images of breast masses using the load_breast_cancer() function from sklearn. Datasets. Every data point has attributes such as:
- Average radius
- The texture
- The perimeter
- Region
These labels indicate whether the tumor is benign (non-cancerous) or malignant (cancerous).
Step-by-Step Implementation
1. Import Libraries
The first step is to import the necessary libraries of scikit learn python library.

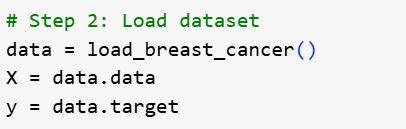
2. Load the Data
The second step is to load the dataset with the features and target labels.
3. Split the Data
We split the data into training (70%) and testing (30%) sets to evaluate how well the model performs on unseen data.

4. Train a Model
We initialize a built-in scikit learn linear regression: Logistic Regression model and train it using .fit().

5. Make Predictions
After training, we use .predict() to generate predictions for the test set.

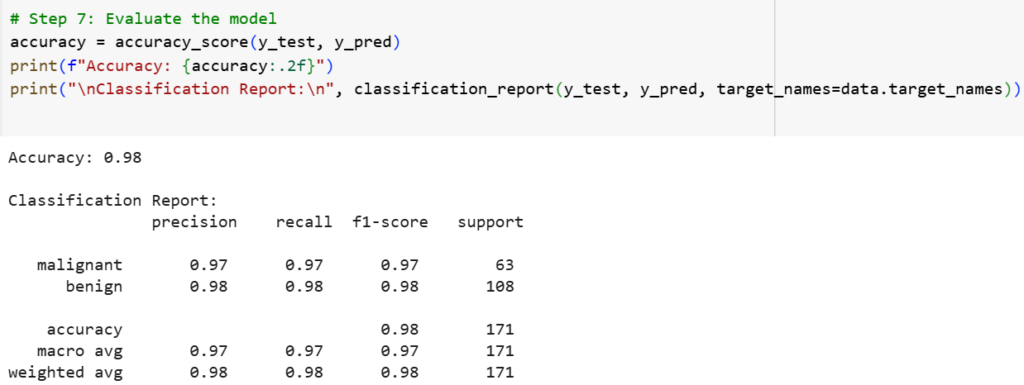
6. Evaluate the Model
We calculate the accuracy and display a classification report for detailed metrics.
Behind the Scenes of Scikit-Learn Development
With just a few lines of code, scikit-learn lets you:
- Data Preparation: Easily manages the loading and splitting of datasets with integrated tools.
- Model API: Fit() and predict() are the standard interfaces used by all models.
- Evaluation Tools: Accuracy_score and classification_report are built-in functions that make evaluating the model easier.
- Modular Design: With minor code modifications, you can replace Logistic Regression with any alternative model, such as RandomForestClassifier.
This example is just the tip of the iceberg. From here, you can explore different models, apply pipelines, and cross-validation, all using scikit-learn.
Here is another simple example for you to try.

Why WeCloudData + Scikit-learn = Success
At WeCloudData, we believe that education should be practical, career-focused, and accessible to everyone, whether you’re an aspiring data scientist, a software developer transitioning into AI/ML, or a business team looking to upskill.
From day one, our learners work with real data, build models using libraries like scikit-learn, and gain hands-on experience solving real-world problems. We don’t just teach syntax, we teach you how to think like a data scientist.
What WeCloudData Offers
- Career-Focused Bootcamps: Learn Python, Data Science, Data Engineering, Machine Learning, and AI via our learning tracks.
- WeCloudData’s Corporate Training programs are designed to meet the needs of forward-thinking companies. With hands-on, expert-led instruction, our courses are designed to bridge the skills gap and help your organization thrive in today’s data-driven economy.
- Live public training sessions led by industry experts
- Career workshops to prepare you for the job market
- Dedicated career services
- Portfolio support to help showcase your skills to potential employers.
- Enterprise Clients: Our expert team offers 1-on-1 consultations.
Join WeCloudData to kickstart your learning journey and unlock new career opportunities in Artificial Intelligence.
