The blog is posted by WeCloudData’s Big Data course student Udayan Maurya.
Spark’s native ML library though powerful generally lack in features. Python’s libraries usually provide more options to tinker with model parameters, resulting in better tuned models. However, Python is bound on single compute machine and one contiguous block of memory, which makes it infeasible to be used for training on large scale distributed data-set.
Pandas — UDF (Get best of both worlds)
Pyspark performs computation through following data-flow:
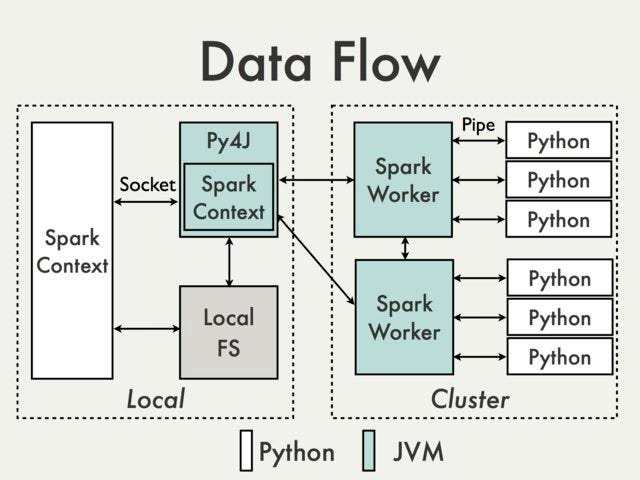
We trigger our spark-context program on Master(“Local” in image here) node. The Spark program is executed on JVMs. Whenever during execution of code Spark encounters Python functions JVMs starts Python processes on working clusters and Python takes on the assigned task. Necessary data required for computation is pickled to Python and results are pickled back to JVM. Below is schematic data-flow for Pandas UDFs.

Pandas-UDF have similar data-flow. Additionally, to make the process more performance efficient “Arrow” (Apache Arrow is a cross-language development platform for in-memory data.) is used. Arrow allows data transfer from JVMs to Python processes in vectorized form, resulting in better performance in Python processes.
There is ample of reference material available for data munging, data manipulation, grouped data aggregation and model prediction/execution using Pandas UDFs. This tutorial serves the purpose of providing a guide to perform “Embarrassingly Parallel Model Training” using Pandas UDF.
Requirements
- Spark cluster (Databricks free community edition can be used)
- Python Libraries: Numpy, Pandas, Scikit-Learn, and Joblib
*I have used Databricks environment for this tutorial
1. Create Directory to store required files
To operate on Databricks File System we use dbutils commands. Create a temporary folder in your DBFS.

This creates a “temporary” directory in “dbfs:/FileStore”
2. Import required Libraries

3. Create dummy data for training
We created two data-sets df1 and df2 to train models in parallel.
- df1: Y = 2.5 X + random noise
- df2: Y = 3.0 X + random noise
We are saving the data-sets in temporary folder from step 1 in zipped format. Zipped files are read in Saprk in one single partition. We are using this feature to keep different data-sets in separate partition, so we can train individual models on each of them.


4. Read files as Spark DataFrame


As files are in zipped format we get one partition for each file. Resulting in total two partitions of SparkDF, instead of default 8. This facilitates in keeping all the data in one worker node and one contiguous memory. Therefore, Machine Learning model can easily be trained using Python libraries on each partition to produce individual models.
5. Pandas UDF function for Model Training

The UDF function here trains Scikit-Learn model Spark Data-frame partitions and pickle individual models to “file:/databricks/driver”. Unfortunately, we cannot pickle directly to “FileStore” in Databricks environment. But, can later move the model files to “FileStore”!
6. Train the models
Create “sparkDF2” which call “train_lm_pandas_udf” on “sparkDF”, created in step 4.

To initiate model training we need to trigger action on sparkDF2. Make sure the action used to trigger touches all partitions otherwise training will only happen for partitions touched.
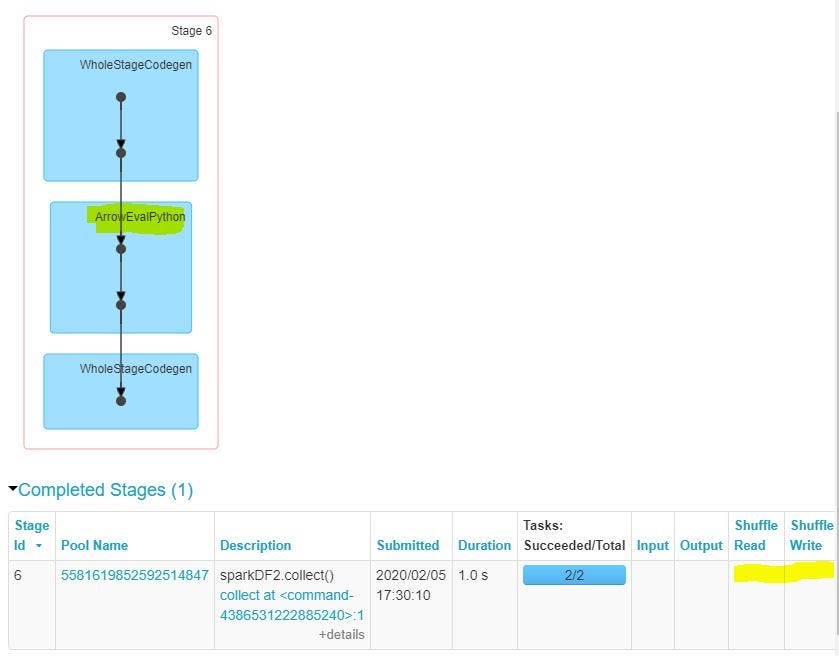
As evident form Job DAG, the columns are navigated to Python using Arrow, to complete the model training. Additionally, we can see that there is no Shuffle Write/Read due to Embarrassingly parallel nature of the job.
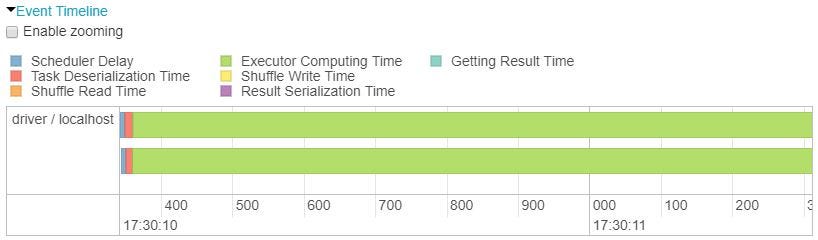
Above displays event timeline for stages of execution of spark job. Parallel execution reduces the time to train by 1/2! (which can be improved by improving on size of your cluster and training more models).
7. Testing the models
As we have trained models on dummy data, we have good idea of what model coefficients should be. So we can simply load model files and see if model coefficients make sense.



Evident from results above. Model coefficient for df1 is 2.55, which is close to our equation for df1: Y = 2.5 X + random noise. And for df2 it is 2.93 consistent with df2: Y = 3.0 X + random noise.
Full notebook and code and be downloaded from:
edishu/SparkUDFTrain
Spark is one of the most popular tool to perform map-reduce tasks efficiently on large scale distributed data-sets…
github.com
Review one use case of parallel model training here:
