The blog is posted by WeCloudData’s Bid Data course student Udayan Maurya.
Customer reviews are invaluable information to understand the gap in your product market fit. If you sell your products on e-platforms: Amazon, Ebay, Appstore, Playstore, Youtube, etc. then you are in luck. You have direct access to your customers mind. However, to leverage customer’s input in your product development you need more than just “Star-Ratings”. Star-Ratings are useful to gauge at a high level how your product is being received in the market, but it does not provide any actionable insights into what you should do to improve your product offerings.
Reading review texts is defiantly a better option to extract customer insights, you get to understand about what features are helping customers solve their problems and what features are causing problems to customers. Additionally, customers often mention their expectation in reviews. However, reading reviews manually causes following problems:
- Reviews are voluminous, for popular products reviews can range form few thousands to millions, making it infeasible for a human reader to completely read them.
- Human readers have difficulty in organizing information in unbiased fashion. Humans may get caught up with impression from a single review, which may not be representative, or most resourceful to act on.
- Human emotion and language biases can also hampers in extraction of actionable insights from reviews.
Enter AI
So what if we can use AI for customer review analysis? AI for customer review analysis can be used by using nlp. Natural language processing equips us with tools, which can help us read and understand customer reviews. We can develop insights on our product features. Know what features of our product are working, what features need improvement and what are customer expectations from our product.
In following sections I will provide NLP Topic Analysis I have applied to research Amazon Customer Reviews data. The analysis helps in identifying customer pain points with the products.
Contents
- Preparing Data for Data Analysis
- Training the Machine Learning Model
- Developing the Dashboard
- Analysis of Results
- Further Scope
Tools/Software Used
- AWS: EC2, and S3
- Databricks Platform for developing ML model
- Python Libraries:
- NLP: Gensim, Spacy
- Numerical Packages: Numpy, Pandas, PySpark
- Model Development: Spark (Pandas UDF), Gensim (LDA Model)
- Dashboard Development: Panel, Bokeh
1. Preparing Data for Data Analysis
Data used is the study is publically available data provided by Amazon:
Amazon Customer Reviews Dataset
Amazon Customer Reviews (a.k.a. Product Reviews) is one of Amazon’s iconic products. In a period of over two decades…
s3.amazonaws.com
For analysis Amazon S3 bucket (original location of data) has been mounted on Databricks instance. Following is schematic flow of entire process:
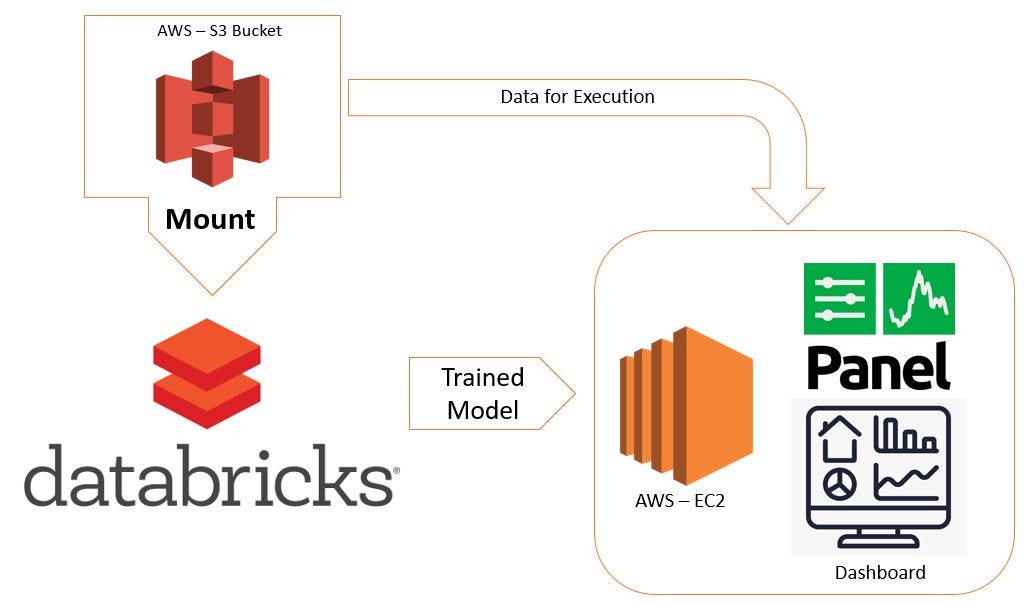
Amazon Review data-set is massive collection of 130+ million customer reviews, which ranges from year 1995–2015. The data-set contains “.tzv.gz”(Zipped tab separated) files. There are 46 files with english reviews (total size ~32GB). Each file comprise of reviews for different product segment. Due to non-trivial size of input data Spark on Databricks Platform has been used to train Machine Learning mode. Data-set has following variables:
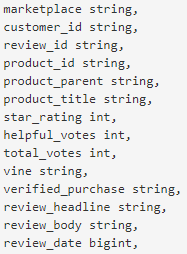
In our AI for customer review Analysis we have performed Topic Modeling on “review_body”.
Following steps are taken to paperer the data:
- Using Regular Expressions Email addresses, and URLs are removed.
- Documents are tokenized using Gensim’s “simple_preprocess”
- Documents are lemmatized using Spacy “en_core_web_lg” dictionary
2. Training the Machine Learning Model
LDA models are very popular for the task of Topic modeling. Spark MLlib comes packaged with LDA models. Additionally, we have Gensim’s LdaMallet models, which are very good at finding useful topics in text corpus. Upon training on a smaller sample of data. Gensim model produced much more comprehensive results compared to Spark’s LDA model.
Technical bottleneck with Gensim is that it runs on single cluster machine and cannot be trained on partitioned. Due to non-trivial size to be consumed. Utilizing Spark cluster capabilities provides huge performance benefits, in terms of parallel training, and reducing overall training time.
To get best of both worlds Gemsim LDA models are trained on Spark cluster in embarrassingly parallel fashion. Please review my other blog-post on technical details of Training Embarrassingly Parallel Models on Spark using Pandas UDF. As our objective in this use case is to obtain one model for each product segment, embarrassingly parallel on single partitions of Spark RDDs help us run model training in parallel for each product segment significantly reducing the total training time.
To determine number of topics to be use we have used Coherence Score to compare LDA models.
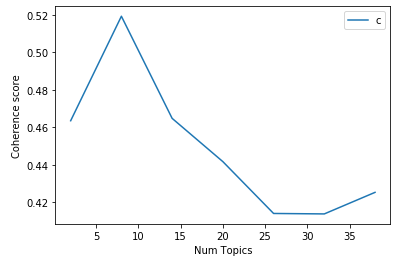
The Coherence score is a numerical way to compare Topic models. The higher the score the better the model is. In above case model with 8-topics performs the best.
3. Developing the Dashboard
We deployed the best models for the Health-Personal-Care, Luggage, Apparel, and Electronics segments on an AWS-EC2 instance. We developed the model dashboard using the Bokeh and Panel libraries. From each segment, we selected one product—Yoga mat, Bag, Coat, and Micro-SD card—for analysis.
4. Analysis of Results
Below is an image of Application in action:

- App allows us to select from various products from drop-down menu.
- Select star-ratings you want to see topics for. You can select multiple ratings at any time. This allows us to see topics for lowest rated reviews and can help product developers to improve products.
- Indicator of all ratings selected for analysis.
- Read the most discussed topics for the ratings you have selected. This part is more art then science, and requires business acumen. From topic words we can guess what is bother our customers. Fore example here in 1-star reviews on can reasonable say that customers are not happy with Yogamat being “Teared”, “Wear” in short time. Or there is “Stretching”, “Slipping”, “Sliding” of material. Therefore, as a product developer we can focus on reviewing material quality of out product we can test/improve martial manufacturing or supplier to mitigate this most pressing issue for the product.
- The Topic Distribution histogram shows how many reviews correspond to each topic, with each review mapped to only its most representative topic.
- Displays how may of total reviews qualify for the rating selection.
- Well this is the most seen one, this is the review distribution by ratings.
5. Further Scope
We can develop the model to include bi-gram and tri-gram tokens to discover more characteristic topics. Additionally, we can remove more common (trivial) words from each segment of the corpus to make useful, meaning-carrying words more prominent.
The Model/Methodology is very transferable to other kinds of reviews. For example reviews on Appstore, Playstore, YouTube, etc.
To find out more about the courses our students have taken to complete these projects and what you can learn from WeCloudData, view the learning path. To read more posts from Udayan, check out her Medium posts here.
