The blog is posted by WeCloudData’s Big Data course student Udayan Maurya.
This Live Twitter Sentiment Analyzer helps track present sentiment for a given track word.

In this document, I will describe the work flow I followed to develop this SaaS app.
Contents
- Data Pipeline Map
- Data Collection
- Preparing Data for Data Analysis
- Training the Machine Learning Model
- Developing the Dashboard
Tools/Software Used
- AWS: EC2, Kinesis Firehose, and S3
- Entire App is developed on Python!
- Python Libraries:
- Data Extraction/Munging: Tweepy, Nltk, Boto
- Data Cleaning: Numpy, Pandas
- Model Development: Nltk, sklearn,
- Dashboard Development: Panel, Bokeh
1. Data Pipeline Map
Following is the scheme for development and deployment of sentiment analysis app:
Data Collection:
- Data was streamed using Twitter API from 23-Dec-2019 to 06-Jan-2020.
- Real-time data was pushed and assembled in AWS-Kinesis messaging queue.
- Every 15 minutes data was delivered using AWS-Firehose to store in AWS-S3.

Model Development:
- Data was read from data store AWS-S3 using a subclass of NLTK CorpusReader.
- Data was ingested in chunks tokenized, lemmatized, and vectorized.
- Various models were trained to find the best predictive model.
- Model visualization are developed using Bokeh and Panel.
Model Execution:
- Dashboard has been deployed with trained model on AWS-EC2 instance for real-time sentiment analysis.
- The App uses tweepy to read real-time tweets and makes sentiment predictions using the model.
2. Data Collection
Twitter allows access to programmatically read tweets using API for various languages. We are using “tweepy” (python) to read data from Twitter. Data from 23-Dec-2019 to 06-Dec-2020 (~ 36 million Tweets) was collected.

Corpus Scheme:

Data has been stored in AWS-S3 in the directory structure as shown in figure.
twitter-|sentiment|-|Year| -> |Month| -> |Date| -> |Tab delimited files|
Methodology for Sentiment segregation: Twitter allows data stream to be filtered using track words. Emojis are an excellent way to determine emotion from a text. Therefore, emojis have been used as track words to filter for negative sentiment and positive sentiment tweets. This helps in producing noisy signal for true underlying sentiment. Additionally, training on large amount of data helps in clarifying the signal and develop a good general predictive model. The methodology is inspired by the following work: https://cs.stanford.edu/people/alecmgo/papers/TwitterDistantSupervision09.pdf
Following emojis/smileys are used to filer tweets for sentiment segregated data:

Additionally, tweets have been filtered to include English language tweets only.
3. Preparing Data for Analysis
NLTK — CorpusReader class has been extended to read the data as pandas DataFrame in chunks. CorpusReader helps in navigating and reading appropriate files by matching regular expressions in complex directory structures.

Following code read each file from positive and negative file lists and yields chunks of DataFrames containing both emotions (Positive: 1, Negative: 0)

Raw tweets are transformed to numerical vector form as follows:
Tokenization/Vectorization
- “@” Twitter handles are removed
- Stop words (a, an, the, to, etc.) are removed
- URLs in tweets have been removed
- Emoji and smileys used to filter and get data are removed
- Tokens are further lemmatized using NLTK WordNetLemmatizer
- Tokens are vectorized using sklearn TFIDF/Count vectorizer
4. Training the Machine Learning Model
Naive Bayes, and Support Vector Machine models are trained. The data was split into 67% training and 33% testing data. Following four combinations of models were tried:
- TFIDF Vectorizer with MultinomialNB
- TFIDF Vectorizer with SVM for Classification
- Count Vectorizer with MultinomialNB
- Count Vectorizer with SVM for Classification
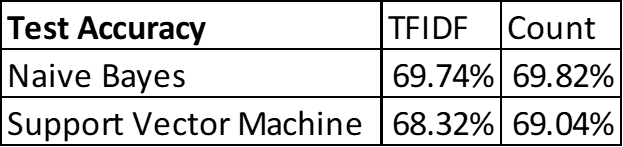
Test accuracy of all the models was fairly comparable. For final model for execution phase we selected “TFIDF Vectorizer with MultinomialNB”. We opted for MultinomialNB because it has faster execution time.
In final execution Neutral class has been artificially created. Given that response in training data is only for positive and negative sentiment, the prediction classes have been defined as follows:
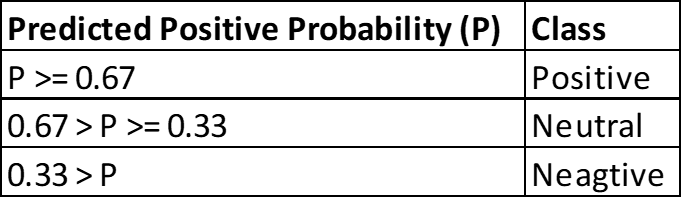
5. Developing the Dashboard
Bokeh and Panel libraries have been used to develop plots and represent the dashboard.
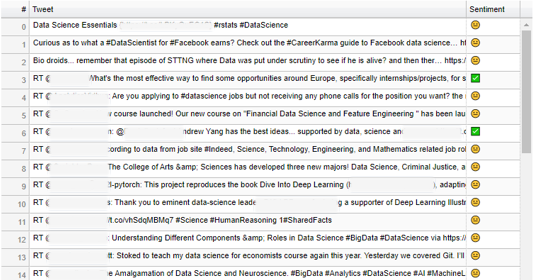
Bokeh DataTable class is used for populating the live tweets and sentiments:
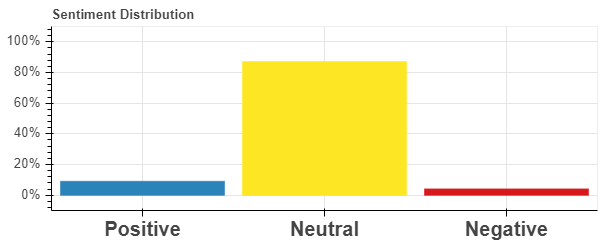
Bokeh Vbar plot is used to plot sentiment distribution:
Console objects are Plane TextInput and Button Classes
All the Dashboard elements are assembled using panel Row and Column classes. Finally, the panel code is served on an AWS-EC2 instance:
To find out more about the courses our students have taken to complete these projects and what you can learn from WeCloudData, view the learning path. To read more posts from Udayan, check out his Medium posts here.
