Welcome back to our Data Wrangling with Python series! In the first blog of the data wrangling series, we introduced the basics of data wrangling using Python. We work on handling missing values, removing special characters, and dropping unnecessary columns to prepare our dataset for further analysis. Now, the next step is to deeply explore textual data wrangling, an important step when working with text-based datasets.
In this blog, we’ll focus on preprocessing textual data, which involves transforming raw text into a clean, structured format suitable for textual data analysis like sentiment analysis in this case. By the end of this blog, you’ll learn essential textual data-wrangling techniques in Python and how to apply them to real-world datasets. Follow this link (link to the first blog) to read the first blog in the data wrangling series if you haven’t read it yet.
Let’s get started with WeCloudData!
Why Textual Data Wrangling is Important?
Unstructured data is mostly present in the form of textual data which is messy in nature. Users’ feedback data whether from the X or any other social platform contain abbreviations, emojis, slang, and special characters, making them challenging to analyze. Cleaning and formatting this raw text for use in machine learning, topic modeling, sentiment analysis, and other applications is known as textual data wrangling.
According to Gartner, 80 to 90% of the world’s data today is unstructured and growing at an annual rate of 61%. So learning how to preprocess and perform data wrangling on unstructured data is an important skill for data professionals.
Step-by-Step Guide to Textual Data Wrangling
Step 1: Recap of the first blog in the Data Wrangling Blog series
In the first blog, we performed the following steps:
- Handling Missing Values: We checked for missing values in the dataset and dropped rows where text was missing.
- Removing Special Characters: We cleaned the ‘text’ column by removing special characters, hashtags, and mentions.
- Dropping Unnecessary Columns: We removed the unnecessary columns and used only the ones that we needed for analysis.
You can read the previous blog to get an idea but here is a snippet of code for all these steps we performed.

Now, let’s move on to preprocessing the cleaned textual data.
Step 2: Analyzing and Managing Text Length
Short or lengthy sentences can introduce noise into real-world datasets. Lengthy posts may contain too much irrelevant information, and short ones may not contain any useful information. So we need to analyze the length distribution of our data before deciding on a threshold value. Here is the snippet of the code to find the length distribution of posts.

Setting Minimum Length Threshold
To determine a minimum length threshold, we analyze the histogram of tweet lengths. The distribution of the histogram is skewed to the right, spiking around 140 characters. However, there are also a significant number of very short tweets. Refer to the histogram below.
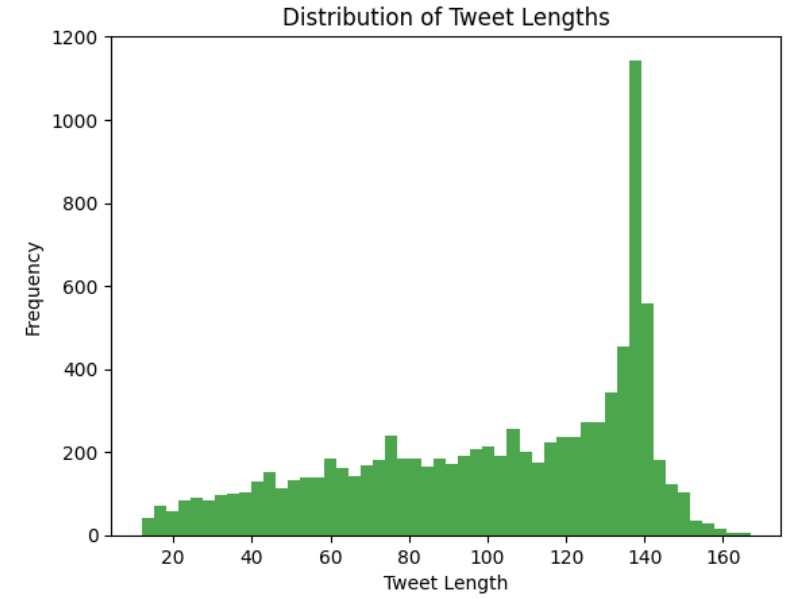
While keeping enough information for analysis, we must exclude short tweets that might not include any valuable information. Based on the histogram, a reasonable threshold is 10 characters, ensuring that we exclude tweets that are likely just symbols, single words, or noise.

Step 3: Tokenization
Tokenization is about splitting text into tokens or individual words. This is a crucial step in text preprocessing because it divides the text into manageable tokens for analysis. For tokenization, we will import the required libraries.

This will split each post into a list of words, making it easier to analyze.
Step 4: Stopwords Removal
Common words that don’t provide much meaning to the text, like “the,” “is,” and “and,” are known as stopwords. Eliminating them helps in noise reduction and concentration on the key phrases.

Step 5: Stemming and Lemmatization
Stemming and lemmatization are methods used in textual data wrangling to reduce words to their base or root form. This helps standardize words with similar meanings and reduce redundancy.
Stemming
Stemming is one of several text normalization techniques that convert raw text data into a readable format for natural language processing tasks.

Lemmatization
The process of reducing the different forms of a word to one single form, for example, reducing “builds”, “building”, or “built” to the lemma “build”: Lemmatization is the process of grouping inflected forms as a single base form.
Step 6: Saving the Preprocessed Data
We are at the end of the textual data data-wrangling with Python. Now this data is ready for further analysis. One last thing we have to do is to save it so that data analyst or data scientist can use it for sentimental analysis.

Why Textual Data Wrangling is Important
Textual data wrangling is an important step in a text analysis project. By cleaning and preprocessing text data, you can:
- Improve the accuracy of the analysis.
- Reduce noise and focus on meaningful words.
- Prepare data for machine learning models
Congratulations! You’ve just completed your first data-wrangling project using Python. We’ve learned basic and advanced data wrangling using X data. We transfer raw textual data into a format that can be used for sentiment analysis or further exploration. Stay tuned for our next blogs on sentiment analysis and data visualization. Happy Learning with WeCloudData!
Get Started with WeCloudData
If you’re interested in mastering more advanced data wrangling techniques, check out the WeCloudData Data Wrangling Python course and get your data wrangling certification today. Whether you’re looking to enhance your Python skills or preparing for SQL, this course offers practical, hands-on experience that aligns with real-world data challenges.
Additional Resources:
- Python for beginners and advanced users.
- Data Visualization with Tableau and PowerBI to complement your wrangling skills.
Stay tuned for the next part of our series where we learn text data wrangling techniques!
