Top Essential Python Libraries for Data Science in 2025
June 11, 2025
Python’s ease of use, adaptability, and constantly expanding toolkit have made it the foundation of modern data research. In 2025, this programming language continues to dominate the market due to its multiple essential libraries, which cover everything from data manipulation to machine learning, system operations, and web communication.
Using the right Python libraries can help save time, make code easier to read, and produce more insightful results, whether analyzing big datasets, creating predictive models, or developing AI-powered apps.
Let’s explore the most important Python libraries for data science in 2025 with WeCloudData, covering both well-known frameworks and powerful tools from the Python standard library. Additionally, you will learn how Python’s OS module and requests library facilitate system-level tasks, automation, and API integrations.
Why Libraries Matter in Python Data Science
Python’s extensive and developed library ecosystem is largely responsible for its widespread use. The Python standard library provides built-in support for string manipulation, math, file I/O, and OS-level tasks. In addition, third-party modules expand Python’s functionality in specific fields like data visualization, deep learning, and statistics. These libraries are productivity powerhouses that facilitate effective workflows for data scientists, engineers, and analysts.
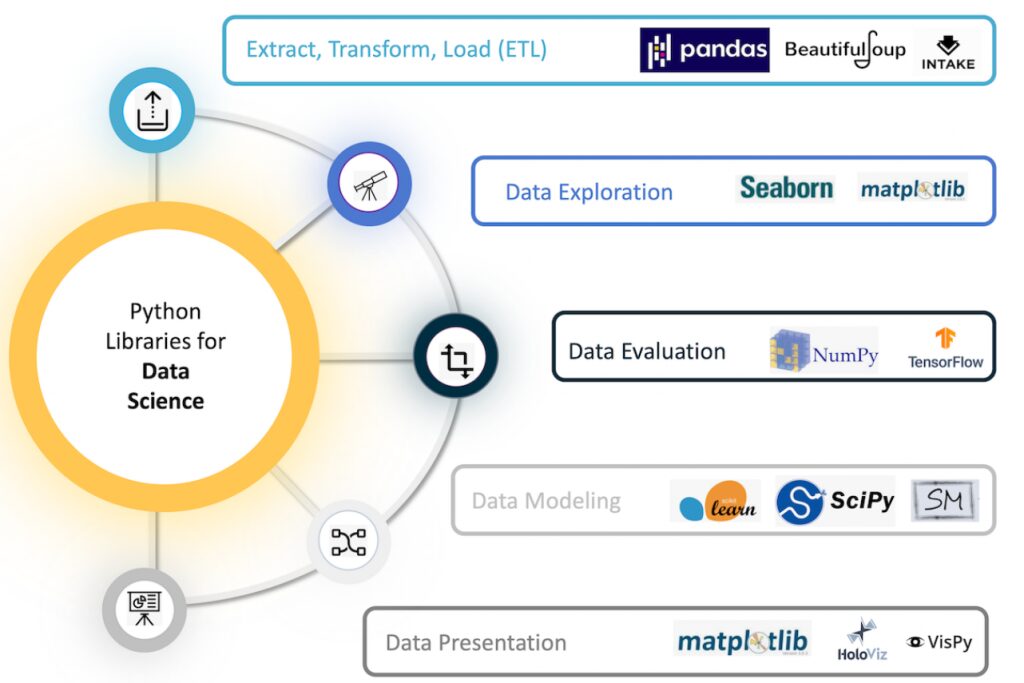
Core Data Science Libraries in Python
Let’s start exploring the data science Python libraries every data practitioner should know in 2025.
NumPy – Foundation of Numerical Computing
NumPy is a fundamental Python library for working with arrays, linear algebra, and high-performance numerical computations. It is frequently a requirement for other libraries such as Pandas, SciPy, and Scikit-learn, and is widely used in scientific computing.
Key Features:
n-dimensional Arrays
Vectorization and broadcasting
Quick mathematical calculations
NumPy Goal: Fundamental data manipulation and numerical analysis.
Pandas – Data Manipulation
Pandas is the go-to library for working with structured data in Python. It makes data acquisition, cleaning, transformation, and exploratory analysis easier with its robust DataFrame object.
Key Feature:
Simple I/O in CSV, Excel, and databases
Aggregation and grouping
Time series analysis
Pandas Goal: Effective tabular data manipulation for analysis or machine learning preprocessing.
Matplotlib & Seaborn – Data Visualization
Matplotlib is a comprehensive 2D plotting library for creating static, animated, and interactive visualizations in Python. Seaborn is built on top of Matplotlib and provides a high-level interface for drawing attractive and informative statistical graphics.
Matplotlib provides low-level control over plots and visuals.
Seaborn abstracts common visualization patterns.
Matplotlib & Seaborn Goal: Visualizing trends, distributions, and statistical insights.
Scikit-learn – Machine Learning
One of the most important Python libraries for machine learning is still Scikit-learn. It provides APIs for modeling pipelines, cross-validation, and supports traditional machine learning techniques.
Scikit-learn offers these algorithms.
Logistic and linear regression
Naïve Bayes, SVMs, and decision trees
dimensionality reduction and clustering
Scikit-learn Goal: Building machine learning models on tabular datasets.
SciPy – Scientific and Technical Computing
SciPy complements NumPy by adding modules for optimization, statistics, signal processing, linear algebra, and more. It’s invaluable for researchers and engineers working with scientific data. The algorithms and data structures provided by SciPy are broadly applicable across domains.
SciPy Goal: Higher-level scientific computing.
Deep Learning and Advanced Machine Learning Libraries
As AI models become more complex, Python’s machine learning ecosystem continues to grow. Here are the essential libraries for deep learning and advanced ML in 2025.
TensorFlow
TensorFlow is a high-performance framework for creating neural networks and scalable machine learning systems. It makes it easy to create ML models that can run in any environment and supports training on CPUs, GPUs, and TPUs, and integrates with tools like Keras.
TensorFlow Goal: Building deep learning models, especially for production deployment.
PyTorch
PyTorch is a fully featured framework for building deep learning models, which is a type of machine learning that’s commonly used in applications like image recognition and language processing. Written in Python, it’s relatively easy for most machine learning developers to learn and use.
PyTorch Goal: Fast prototyping and experimentation with AI models.
Statsmodels – Classical Statistical Modeling
Statsmodels is a Python module that provides classes and functions for the estimation of many different statistical models, as well as for conducting statistical tests and statistical data exploration. It supports specifying models using R-style formulas and pandas DataFrames.
Statsmodels Goal: Classical statistics and model interpretability.
Python Requests Library
Data scientists often need to fetch data from online APIs or connect with web services. The requests module is the most widely used HTTP library in Python. It abstracts complex HTTP operations into a simple and intuitive syntax.
Request Library Goal: Communicate with REST APIs or fetch web resources.
OS Library in Python
The os library in Python allows users to navigate directories, manage environment variables, and interact with the file system.
Python Standard Library – Hidden Gems
Apart from OS and Requests, the Python standard library contains dozens of useful modules:
datetime: Work with date and time
json: Serialize and deserialize JSON
re: Regular expressions for text parsing
math: Mathematical functions
Goal: Common tasks without third-party installations.
Real-World Use Casesof Python
Finance: Credit scoring, fraud detection, and stock analysis are done with Statsmodels, Pandas, and Scikit-learn.
Healthcare: Medical imaging and disease prediction are powered by TensorFlow and PyTorch.
Marketing: Scikit-learn powers recommendation engines, while Seaborn and Matplotlib are used to show consumer trends.
Choosing the Right Library
There is no one-size-fits-all solution when it comes to Python’s libraries. Your domain, data volume, team experience, and ultimate objectives all influence the tool you choose. Python standard libraries, along with Pandas, NumPy, Scikit-learn, and requests, are indispensable across almost every data science project in 2025.
Build Your Career with Python + WeCloudData.
In 2025, Python continues to lead the data science world because of its accessibility and the power of its libraries. From foundational tools like NumPy and Pandas to deep learning giants like PyTorch and TensorFlow, these are the Python essential libraries you need to know to thrive.
At WeCloudData, we teach not just the syntax but the purpose behind each of these essential libraries for Python. Whether you’re a beginner learning Python basics or a professional looking to specialize in data engineering or machine learning, our curriculum is built to grow with you.
Why Learn Python at WeCloudData?
Learn from industry professionals with real project experience
Access real datasets from financial, retail, and tech industries
Start your learning journey today with our courses and bootcamp, and grow into advanced topics like AI engineering and data pipelines, all under one roof.
SPEAK TO OUR ADVISOR
Join our programs and advance your career in Data Engineering