
As I log in to check my email, the thought of seeing spam emails sitting in my inbox annoys me. Chances are, you do as well. Spam is not only annoying but may also potentially contain harmful content. Additionally, spam consumes computers, servers, and network resources, causing harmful bottlenecks, effecting compute memory and speed of digital devices. Classical methods like blocking the source to prevent the spam are not effective [1]. These approaches fail to adapt to the evolving tactics of spammers, leading to a continuous influx of unwanted emails. The reported accuracy of these methods indicates that there is significant room for improvement, highlighting the need for more sophisticated solutions to reduce the global spam problem effectively and this introduces a better idea to overview email spam detection using machine learning [2].
However, the advent of machine learning has brought about a paradigm shift in how we manage email spam. Picture a system that learns from your behavior, analyzes the content of emails, and accurately predicts which messages are important and which are just noise. Email spam detection using machine learning is possible through machine learning techniques, through their ability to process and learn from large datasets, offer a much more effective solution for distinguishing between spam and legitimate emails.
As in various fields, deep learning techniques have proven to have superior performance compared to other machine learning algorithms in this area [3]. Deep learning algorithms, with their advanced pattern recognition capabilities, can analyze the intricacies of email content more accurately than ever before. This has led to significant improvements in spam detection, ensuring that users receive only relevant and valuable information in their inboxes. Deep learning is a type of machine learning that mimics the way humans learn and make decisions. Imagine your brain as a huge network of neurons that work together to help you understand and respond to the world around you. Deep learning uses a similar approach but in a computerized form.
In simple terms, deep learning creates a “brain” for computers made up of layers of neurons, called artificial neurons, which are actually tiny, simple processing units. These layers are stacked on top of each other to form what’s called a neural network. Here’s how it works: you give the computer a lot of data, like pictures, text, or sounds. The first layer of the neural network looks at the basic features of this data, like edges in a picture. The next layer combines these features to recognize more complex shapes or patterns, like a nose or an eye in the case of images. As the data moves through the layers, the network learns to understand increasingly complex things.
By the time the data reaches the final layer, the deep learning system has learned to recognize complex objects, sentences, or sounds, not just simple features. This is how it can tell the difference between, say, a cat and a dog in photos, or spam and non-spam emails. In summary, deep learning is like teaching a computer to learn and make decisions by feeding it a lot of information and letting it process and understand this information through layers, similar to how our brains work.
Please note that the aim of this article is to showcase the practical utility of machine learning in enriching our everyday lives, rather than to explore its technical complexities. We aim to highlight the fascinating applications of machine learning, especially email spam detection using machine learning with an objective of sparking interest that encourages further exploration into data science and machine learning. If you are looking for learning about Machine Learning in more detail and learning how to become a certified machine learning engineer, do check our AI and Machine Learning bootcamp!
That being said, let’s take a look at some code snippets to see machine learning in action for email spam detection.
Some of the code snippets in this article are sourced from a Kaggle notebook by Faisal Qureshi, titled “Email Spam Detection 98% Accuracy”. Kaggle is a platform that provides a community for data scientists and machine learning practitioners to explore, analyze, and share quality data sets and build machine learning models. It offers a collaborative environment where users can participate in competitions, access a broad range of datasets, and gain insights from other professionals in the field.
Continuing from our previous discussion on Kaggle, the code snippets below set up the foundation for a machine learning project focused on spam detection. It includes importing essential libraries, such as numpy and pandas for data manipulation, matplotlib and seaborn for data visualization. This setup is crucial for exploring, cleaning, and understanding data before applying any machine learning models, making it a foundational step in any data science project.

The code below loads datasets from a specified path on Kaggle into a Pandas DataFrame, which is a structure used for data manipulation in Python.

The .head() function is used to display the first five rows of this dataset as shown in the code snippet below.
Top five rows overview:
The original dataset contains the following features (also referred to as attributes or column names):
- CATEGORY: Indicates whether the message is ‘spam’ or ‘ham’ (non-spam).
- MESSAGE: The text content of the message.
This dataset provides information about the classification of text messages and their content.
Examining summary statistics is beneficial because it provides a quick overview of key characteristics of numerical data. However, since there are no numerical variables in this dataset and we only have categorical data, we will skip this part. This approach allows us to focus on analyses more suited to the nature of our data, such as frequency distribution and mode analysis for the categorical variables.
Now, we will broaden our view by delving into the metadata of our dataset. By examining the metadata, we aim to gain a deeper understanding of the data’s framework and attributes, such as the column names or features. This exploration will not only enrich our comprehension of the dataset’s intricacies but also help us identify how these attributes interact and contribute to the overall data structure, thereby enhancing our analytical approach and facilitating more informed decision-making.
Metadata

Metadata provides an overview of the dataset itself; it’s the data about the data. Metadata provides a high-level summary about the characteristics of the dataset. It includes details such as the column names, the types of data contained in each column (numerical, textual, etc.), and the count of non-null entries in each column, among other aspects. The code snippet below is typically utilized to retrieve the metadata of a dataset.

Upon executing the code, a succinct summary is displayed, offering valuable insights into the various data types present and the memory usage in the dataset. This information is crucial for deeper analytical efforts. The output generated might begin as follows:
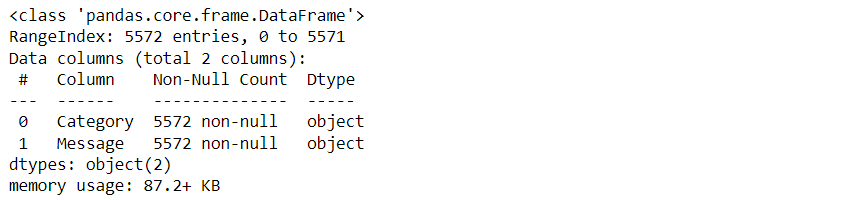
- Range Index: The dataset is indexed from 0 to 5571, providing a unique identifier for each row.
- Columns: There are a total of 2 columns, each representing a different feature or attribute of the messages.
- Column Details: Each column’s non-null count is 5572, indicating no missing values in the dataset.
- Data Types: The dataset consists of object data types (text data) for both columns.
- Memory Usage: The dataset consumes approximately 87.2 KB of memory.
One of the primary responsibilities of a data scientist or machine learning practitioner involves communicating findings to stakeholders. Therefore, an integral part of their role is to create visualizations that convey insights derived from data analysis, ensuring that the information is accessible and understandable.
To illustrate this point, let’s take a look into a couple of visualizations:
Word Cloud Visualization: The image below displays a word cloud created from the “spam.csv” dataset, highlighting the most frequently occurring words in a visually engaging format. The size of each word within the cloud represents its frequency or prominence in the dataset, with larger fonts indicating words that appear more often. This type of visualization helps to quickly identify key themes and terms that are commonly used in the communication, such as “call”, “now”, “just” among others. The variety of sizes and the different colors emphasize the diversity of the text content, offering an intuitive understanding of the data’s textual patterns.

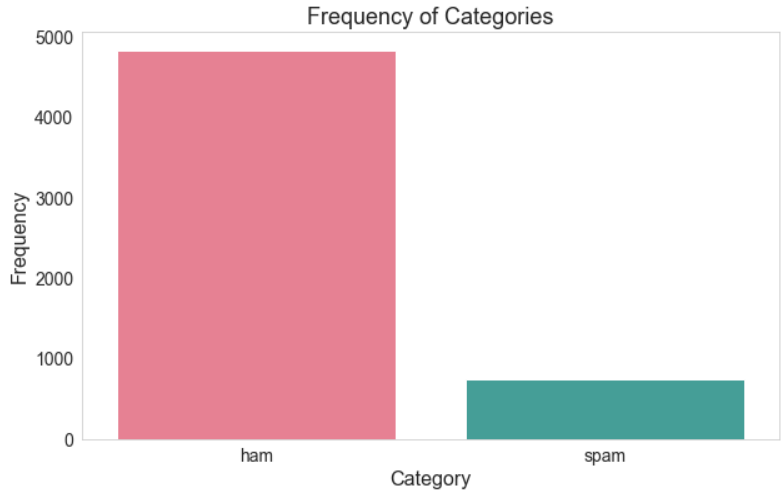
Frequency of Categories: The bar chart below illustrates the comparison between two categories – ‘ham’ and ‘spam’. Each bar represents the count of messages classified under each category. The ‘ham’ category, shown in pink, has a significantly higher frequency, dominating the chart with a value that appears to surpass 4000. On the other hand, the ‘spam’ category, displayed in teal, has a much lower count, under 1000, indicating that it occurs less frequently in the dataset. This visualization effectively demonstrates the disparity between the two categories, highlighting that ‘ham’ messages are far more common than ‘spam’ messages within this collection. The difference in color not only distinguishes the categories clearly but also emphasizes the stark contrast in their occurrences.
Given the clarity that visualizations provide in demystifying complex data, our focus shifts to the realm of feature engineering. In this phase, we refine and transform data to further enhance model performance.
Feature Engineering
In the realm of data analytics for spam detection, a vital preliminary step before training machine learning models is feature engineering. This process involves transforming the raw dataset, comprising messages labeled as ‘spam’ or ‘ham,’ into a structured format that is more suitable for analysis by machine learning algorithms. This enhancement is essential to improve the models’ ability to deliver more accurate predictions regarding the classification of messages, thereby enabling them to identify spam more effectively. Good feature engineering is a foundation for learning algorithms, transforming raw data into informative features that simplify the forecasting task and yield better results [4].
In feature engineering for datasets similar to our collection of messages, several actions are typically considered. These include the extraction of relevant attributes from the data, such as key terms or phrases commonly found in spam, and the careful handling of any missing values to preserve the dataset’s integrity. Additionally, the encoding of categorical variables (like the ‘spam’ or ‘ham’ labels) and the transformation of text into numerical values through techniques like tokenization and vectorization are standard practices. Although the dataset in its raw form may not have undergone these specific transformations, they are essential steps in the process of rendering the data more amenable to generating accurate machine learning predictions.
Moreover, feature engineering may entail the creation of new features via methods like the consolidation of related attributes or the breakdown of complex text data into simpler components. For example, breaking down messages into counts of words or the frequency of specific characters could be insightful. You might ask how can machine learning improve the accuracy of email spam filters? Identifying the most impactful features that contribute to the model’s predictive accuracy is also a crucial part of this process. By thoroughly refining and enhancing the dataset with these strategies, we can bolster the model’s capability to detect patterns, thus refining the accuracy of spam detection outcomes. Choosing the most relevant features can also reduce the complexity of the model and improve its performance.
Let’s explore some integral elements of feature engineering for spam detection:
- Data Extraction and Refinement: The first step in feature engineering for our dataset involves isolating key characteristics that are pivotal for distinguishing spam messages. This might include extracting word counts, the presence of specific keywords, or the frequency of capital letters.
- Feature Transformation: Transforming text data into a numerical format interpretable by machine learning models through vectorization and encoding categorical labels to facilitate model training.
- Feature Creation and Selection: Developing new features by parsing and analyzing the text data to extract meaningful patterns or by simplifying complex textual information into more accessible data points. This might also include the selection of the most significant features that can enhance the precision of the model’s predictions.
- Optimization for Predictive Accuracy: The overarching objective is to refine the dataset to augment the model’s proficiency in recognizing the hallmarks of spam, thus enhancing the reliability of its classifications.
Having delved into the feature engineering aspect, the subsequent phase is Model Training. In this phase, we utilize the processed dataset, now enriched with well-crafted features, to train the machine learning model on the nuances of spam indicators. With this foundational work in place, we are now ready to advance to the topic of training the model.
Training the Model
After the dataset has been shaped and refined through feature engineering, we progress to the Model Training stage. In this critical phase, the machine undertakes the task of learning to distinguish between various factors that could influence the categorization of messages as ‘spam’ or ‘ham.’ The dataset, now composed of features such as word frequency, message length, and other text-derived attributes, is partitioned into training and testing sets. This division is fundamental to ensure that the model hones its predictive power on a particular subset of data, while an independent dataset is used to evaluate its efficacy.
As emphasized earlier, this article does not aim to serve as an exhaustive tutorial on machine learning. Rather, its purpose is to showcase how machine learning techniques can be adeptly employed in our day to day life such as email spam filtering using machine learning.
The following code snippets are designed to lay the groundwork for the various steps involved in training a model for spam detection. While the details may not constitute a complete machine learning program, they provide a glimpse into the type of approach required to build and train a model tailored for textual data.





Moving forward, we’ll explore the Model Interpretation phase, focusing specifically on how our model predicts spam emails. Here, the emphasis isn’t on the complexity of the model but on its accuracy and reliability in identifying spam. It’s crucial to understand that the model does more than just churn out predictions; it provides insights into email patterns and trends, translating raw data into actionable intelligence. In simpler terms, the goal is not only to assess if the model is effective at detecting spam but also to understand the mechanics behind its predictions and the reasons we can trust its guidance. This comprehension is key to confidently relying on the model for strategic decision-making processes.
Model Interpretation
In the context of email spam detection using machine learning, model interpretation focuses on understanding how algorithms analyze email data, such as sender reputation, keyword frequency, and message metadata, to optimize email spam filtering and security measures. This phase is crucial for ensuring that the insights provided by the model are accurate, meaningful, explainable, and actionable. Explainability is valuable even when it’s not explicitly demanded by regulators or customers, as it fosters a level of transparency that builds trust with stakeholders [5]. Emphasizing explainability is a critical component of ethical machine learning practices, underscoring its importance in the development and deployment of predictive models.
Interpreting these “black box” models can be challenging, requiring the simplification of complex algorithms without losing essential details. It extends beyond mere prediction accuracy; it involves understanding the factors influencing spam trends and identifying patterns that might not be immediately apparent. For example, understanding how changes in email sending patterns or the use of specific keywords affect spam detection can offer valuable insights for improving filtering algorithms and optimizing security protocols.
Evaluating model performance in spam detection involves analyzing key metrics to assess the effectiveness of the spam filtering system. Model evaluation plays a pivotal role, offering a quantitative measure of the model’s predictive capabilities in spam detection.
- Accuracy: Measures the percentage of correct predictions, including both spam and legitimate emails, providing an indication of the overall effectiveness of the spam filtering model.
- Precision and Recall: Precision measures the percentage of emails correctly identified as spam out of all emails marked as spam, while recall measures the percentage of actual spam emails correctly identified, highlighting the model’s ability to minimize false positives and false negatives.
These metrics can help determine the model’s efficiency in real-world email filtering and its adaptability to evolving spam tactics.
Key Takeaways
This article explores the critical role of email spam detection using machine learning, illuminating its transformative effect on email management. By analyzing email data, keyword frequency, and message metadata, it demonstrates how machine learning algorithms refine the accuracy of spam identification. The discussion encompasses the processes of feature engineering, model training, and interpretation, offering an in-depth look at the technical methods that elevate predictive performance. Through practical code examples, the article illustrates the application of these techniques in improving spam filtering and email security. Ultimately, the article emphasizes the profound impact of email spam detection using machine learning, encouraging readers to delve deeper into the intersection of data science and cybersecurity, with a specific focus on spam detection.
Next Steps
- Technology-related roles are the fastest growing jobs in percentage terms, including Big Data Specialists, Fintech Engineers, AI and Machine Learning Specialists and Software and Application Developers[6]. This insight from the World Economic Forum’s Future of Job’s 2025 report highlights the growing demand in these fields. To position yourself advantageously in the job market, consider WeCloudData’s bootcamps. If you are interested in learning and becoming a machine learning engineer and do not know where to start, do check Weclouddata’s AI and Machine Learning bootcamp and earn your Machine learning Certificate today! With real client projects, one-on-one mentorship, and hands-on experience in our immersive programs, it’s an opportunity to develop expertise in AI and machine learning, aligning your skills with the current and future needs of the job market. Set yourself up for success in a dynamic and rewarding career; take action now!
References
[1] Jazzar, M., Yousef, R. F., & Eleyan, D. (2021). Evaluation of Machine Learning Techniques for Email Spam Classification. International Journal of Education and Management Engineering (IJEME), 11(4), 35-42. DOI: 10.5815/ijeme.2021.04.04.
[2] I. Idris, A. Selamat, and S. Omatu, Hybrid email spam detection model with negative selection algorithm and differential evolution, Engineering Applications of Artificial Intelligence, vol. 28, pp. 97–110, Feb. 2014, doi: 10.1016/J.ENGAPPAI.2013.12.001.
[3] S. O. Olatunji, “Improved email spam detection model based on support vector machines,” Neural Computing and Applications, vol. 31, no. 3, pp. 691–699, Mar. 2019, doi: 10.1007/S00521-017-3100-Y/TABLES/4. [Online]. Retrieved from: https://link.springer.com/article/10.1007/s00521-017-3100-y.
[4] Rawat, T., & Khemchandani, V. (2019). Feature Engineering (FE) Tools and Techniques for Better Classification Performance. International Journal of Innovations in Engineering and Technology, 8(2). DOI: 10.21172/ijiet.82.024.
[5] Molnar, C. (2020). Interpretable Machine Learning. Retrieved from https://christophm.github.io/interpretable-ml-book/.
[6] World Economic Forum (2025). “Future of Jobs Report 2025.” Retrieved from https://reports.weforum.org/docs/WEF_Future_of_Jobs_Report_2025.pdf.
