At WeCloudData, we empower learners to bridge the gap between theory and real-world data science skills. In this blog, we’ll explore how to build a book recommendation system using python, a practical application of machine learning that not only enhances your coding proficiency but also strengthens your data science portfolio. This blog is designed for learners of all levels, interested in mastering applied recommender systems with Python.
WeCloudData offers Python courses from beginner to advanced level. Check these courses by following this link.
Recommendation Systems
Recommendation systems are the backbone of my application, like Netflix, Amazon, and Spotify. It becomes a cornerstone of digital personalization, whether it’s suggesting which products to buy on Amazon, what book to read next, or what movie to watch on Netflix.
By learning how to build a book recommendation system using Python, you can gain hands-on experience with:
- Real-world datasets
- Data cleaning and transformation
- Similarity metrics and ranking logic
- Practical machine learning & AI concepts
With platforms like WeCloudData offering personalized mentoring and industry-focused capstone projects, you can build your intelligent systems while receiving expert feedback.

Understanding Recommendation Algorithms
Before we dive into the mechanics of building a book recommendation system using python. There are two foundational approaches that power recommender systems; Collaborative Filtering and Content-Based Filtering, let’s explore the difference between these approaches.
Collaborative filtering
Collaborative filtering is an information retrieval method that recommends items to users based on how other users with similar preferences and behavior have interacted with that item. It is further categorized into two parts;
- User-based filtering: Recommend items based on what similar users liked.
- Item-based filtering: Suggest products that are comparable to the user’s preferences.
Data about user-item interactions (such as ratings or purchases) is needed for this strategy. It works well with large amount of user behavior data.
Content-Based Filtering
Content-based filtering is an information retrieval method that uses item features to select and return items relevant to a user’s query. For books that include genre, author, publication year, or even NLP on book descriptions. Content-based filtering is great when user data is sparse or for addressing the cold-start problem like new users or items.
Hybrid Filtering
Modern solutions incorporate both approaches in recommendation systems. For example, Netflix uses collaborative filtering to suggest series, which are then reordered according to your preferred genres or viewing habits.
Although collaborative filtering is the main focus of this blog because it is straightforward and efficient, you could easily expand it to incorporate content features from the book metadata.
Dataset Overview: Book-Crossing
We’re using the Book-Crossing Dataset for this tutorial of building a book recommendation system using python. This is a popular open-source dataset available on Kaggle and contains:
- Books.csv: Over 270,000 books with metadata such as title, author, year, and publisher.
- Users.csv: User demographics like location and age.
- Ratings.csv: Over a million user-book interactions through explicit ratings.
Now let’s get started!
Step 1: Data Cleaning & Preparation
Data cleaning and preparation is a fundamental step before moving to data modeling. This is an important step that all data scientists must master and something we emphasize heavily in our Python course for beginners and intermediates.

These are standard Python libraries used in data science so we imported them to use in our project:
- pandas for handling tabular data (like Excel sheets).
- numpy for numerical operations.
- matplotlib and seaborn for creating visualizations.

We read three separate CSV files from the Book-Crossing dataset. The sep=’;’ tells Python to treat semicolons as the separator. encoding=’latin-1′ ensures special characters like accented letters are properly read. on_bad_lines=’skip’ helps avoid errors from broken or malformed rows.
Original column names can contain typos, clear, consistent column names improve readability, so we renamed the coulmns.

Next step is handling missing or invalid data ,so these line of code handle missing and invalid data issues. While recomending books some user gave a 0 rating meaning “I haven’t rated it.” we only need positive ratings, which show genuine preferences. This is important for building an effective collaborative filtering model.
Why Data Cleaning Matters
As the saying goes “Garbage in, garbage out. Machine learning models are only as good as the data you feed them.” so , data wrangling is a key skill because it’s foundational to every real-world data science project.
Step 2: Exploratory Data Analysis (EDA)
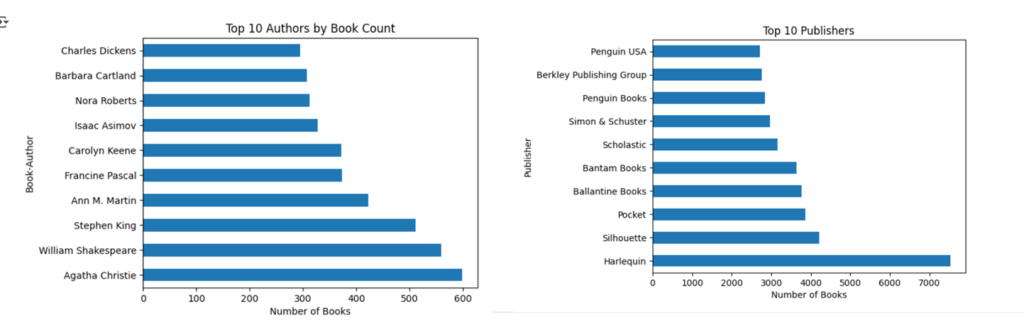
EDA help us understand data better. In this case we count how many books each author has in the dataset and which publishers dominate the book market.
value_counts() helps us rank them.

Here is the visualization of trends we want to know.A horizontal bar chart (barh) is an intuitive way to visualize the most prolific authors.
Step 3: Creating a Popularity-Based Book Ranking Using Weighted Ratings
Merge Ratings and Books
In building a book recommendation using python, we combine ratings with books DataFrames using the ISBN column to get book titles alongside ratings because it is necessary to analyze books by name rather than just ISBN. This step combines user ratings with book metadata like title and author.
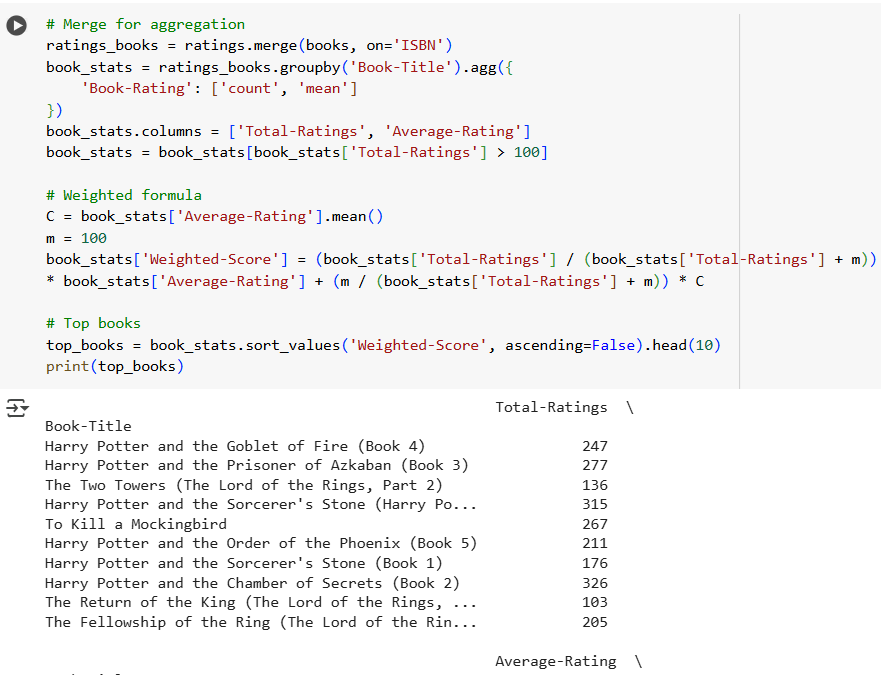
Aggregate Ratings per Book and Filter Books with Sufficient Ratings
Next we ‘groupby’ book title to calculate Total-Ratings and Average-Rating to evaluate which books are popular and well-liked. A threshold of 100 ratings is applied to filter out books that don’t have enough user feedback.
Calculate Weighted Rating
The weighted rating system used by IMDb served as the basis for this method. It strikes a balance between:
- The average rating of a book (if it has several ratings), and
- The global average rating (if it has fewer ratings).
This keeps obscure books with a few 5-star reviews from receiving too much attention.
Explanation of term used in formula:
- C: The average rating for every book (a “baseline”).
- m: The bare minimum of ratings to be taken into account.
The ultimate weighted score is a balance between quality and popularity for our book recommendation system using python.

Below is the whole code for reference;
Step 4: Building a Content-Based Book Recommendation System using Python with Cosine Similarity
It’s time to customize our suggestions now that we’ve used weighted ratings to determine which books are the most popular. We’ll do this by comparing books to each other based on user rating patterns; a method called item-based collaborative filtering as explained above.
This method suggests books similar to a chosen book based on how readers have rated them, rather than making direct predictions based on the user’s preferences. Content-driven websites like Goodreads, Amazon, and Spotify frequently use this approach.
Here’s a step-by-step breakdown of how this content-based similarity model works in our book recommendation system using python:

We filter active user and popular book by keeping books that have at least 50 ratings, ensuring they’re well-known and users who have rated 200 or more books, indicating they’re active and provide rich preference signals. Next created a pivot table.

Uses cosine similarity to measure how similar each book is to others based on user rating vectors and stores similarity scores in a DataFrame (sim_df) for fast lookup.
The recommendation function checks if the input book exists in the index and returns the top 5 similar books based on cosine similarity.
At the end, we provided you with an example to try by yourself to get books similar to “The Da Vinci Code” based on reader behavior.
Want to Build More Real-World Projects?
By now you have created your first successful python project: a book recommendation system using python. Want to create more practical projects? At WeCloudData, our students don’t just learn, they build. Whether you’re a beginner or ready for advanced machine learning and AI, our Python training, Data Science Bootcamp, and project mentorship will help you turn your skills into a job-ready portfolio.
What WeCloudData Offers
- WeCloudData’s Corporate Training programs are designed to meet the needs of forward-thinking companies. With hands-on, expert-led instruction, our courses are designed to bridge the skills gap and help your organization thrive in today’s data-driven economy.
- Live public training sessions led by industry experts
- Career workshops to prepare you for the job market
- Dedicated career services
- Portfolio support to help showcase your skills to potential employers.
- Enterprise Clients: Our expert team offers 1-on-1 consultations.
Join WeCloudData to kickstart your learning journey and unlock new career opportunities in Artificial Intelligence.
