
Introduction
Consider this: In 1950, the life expectancy at birth for a Canadian male was estimated at 66.4 years, while for a Canadian female, it was at 70.9 years [1]. As of 2024, the life expectancy at birth for Canadian males is approximately 78.8 years, and for Canadian females, it is around 84.1 years. [2, 3]. It’s important to note that life expectancy in Canada (and worldwide) has increased significantly over the decades, largely due to advancements in medicine, healthcare, and technology.
Machine learning, a pivotal aspect of modern technology, has been instrumental in this progress, especially in the early detection of diseases such as heart disease detection. In recent years, predictive analytic models, also commonly known as machine learning models, have played a pivotal role in the medical profession because of the increasing volume of healthcare data from a wide range of disparate and incompatible data sources [4]. By analyzing vast amounts of medical data and identifying subtle patterns that may indicate the onset of conditions, machine learning algorithms enhance the accuracy and timeliness of diagnoses. This early detection capability is critical in treating diseases effectively, thereby contributing to increased life expectancy. Furthermore, machine learning’s continuous evolution promises to revolutionize personalized healthcare, making prevention and treatment more effective than ever before.
In their research paper, Choi, S. J., Lee, and colleagues explored the efficacy of machine learning models in early disease detection. They developed a model that combines deep learning and machine learning techniques, achieving high-performance metrics in diagnosing various diseases. This study highlights the potential of machine learning in medical diagnostics, particularly in identifying conditions like hepatitis (liver disease) and myocardial infarction (heart attack) early on, thus showcasing machine learning’s growing role in enhancing healthcare outcomes [5].
In addition to the previous sources, a study by Muhammad et al. (2020) in “Scientific Reports” provides further insight into the role of machine learning in early heart disease detection. This study investigates various machine learning classification algorithms and applies feature selection algorithms to enhance diagnostic accuracy. The study utilized several performance metrics to assess the effectiveness of their model. Their research also demonstrates the potential of machine learning in accurately diagnosing heart disease, emphasizing its growing importance in healthcare advancements and early disease detection [6].
Another source from the Journal of Electrical Systems and Information Technology explored various machine learning techniques used in healthcare, such as supervised learning models including linear regression, logistic regression, and decision trees. The study deduced that these models are instrumental in accurate disease diagnosis and in developing personalized treatment plans, which are essential for improving patient outcomes and potentially saving lives [7].
Please note that the aim of this article is not to delve into the complexities of machine learning, but rather to illustrate its practical utility in everyday life. We aim to offer a glimpse into the practical applications of machine learning, sparking an interest that may encourage you to explore the field of data science and machine learning further. For the scope of this article, we will focus primarily on the detection of heart disease as an approach to early disease identification.
Now, let’s take a look at some code snippets to see machine learning in action for heart disease detection.
The code snippets in this article are sourced from a Kaggle notebook by Farzad Nekouei, titled “Heart Disease Prediction”. Kaggle is a platform that provides a community for data scientists and machine learning practitioners to explore, analyze, and share quality data sets and build machine learning models. It offers a collaborative environment where users can participate in competitions, access a broad range of datasets, and gain insights from other professionals in the field.
Continuing from our previous discussion on Kaggle, this code snippet below sets up the foundation for a machine learning project focused on detecting heart disease. It includes importing essential libraries, preparing data, building predictive models using various algorithms, and evaluating their performance.
The code below loads a dataset named ‘heart.csv’ from a specified path on Kaggle into a Pandas DataFrame, which is a structure used for data manipulation in Python.

The .head() function is used to display the first five rows of this dataset.

Heart disease dataset overview – top five rows:
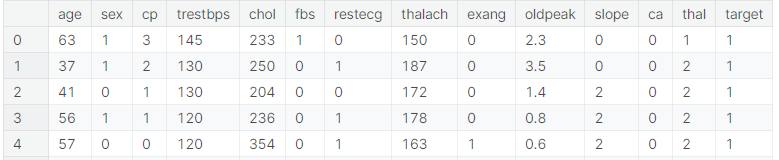
The dataset contains various medical attributes related to heart health. Here is an explanation of each column which is also referred to as attributes or features:
- age: The age of the individual in years.
- sex: The sex of the individual, where 1 represents male and 0 represents female.
- cp (chest pain type): Type of chest pain experienced. Values range from 0 to 3, where each number indicates a different type of chest pain.
- trestbps (resting blood pressure): The resting blood pressure of the individual in mmHg (millimeters of mercury) upon admission to the hospital.
- chol (serum cholesterol): The individual’s serum cholesterol level in mg/dl (milligrams per deciliter).
- fbs (fasting blood sugar): Indicates if the fasting blood sugar level is greater than 120 mg/dl. 1 means true; 0 means false.
- restecg (resting electrocardiographic results): The results of the resting electrocardiogram, categorized into values 0, 1, and 2.
- thalach (maximum heart rate achieved): The maximum heart rate achieved by the individual during a stress test.
- exang (exercise induced angina): Indicates if the individual experienced angina (chest pain) during exercise. 1 means yes; 0 means no.
- oldpeak (ST depression induced by exercise relative to rest): The ST depression value (measured in mm) on an electrocardiogram during peak exercise compared to rest.
- slope (the slope of the peak exercise ST segment): An electrocardiogram measure during exercise, with values typically ranging from 0 to 2.
- ca (number of major vessels colored by fluoroscopy): The number of major blood vessels colored by fluoroscopy, with values ranging from 0 to 4.
- thal (Thalassemia): A blood disorder, with values typically ranging from 1 to 3.
- target: Indicates whether the individual has heart disease or not. 1 indicates the presence of heart disease, while 0 indicates no heart disease.
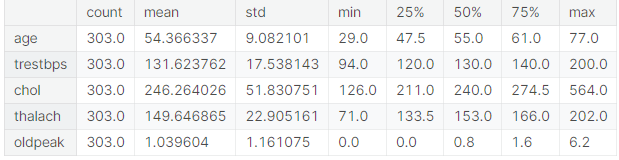
Examining summary statistics is beneficial because it provides a quick overview of key characteristics of the numerical data. The code below generates summary statistics for the numerical variables within the
dataset and transposes the result to display it in a more readable format.
These statistics include measures like mean (average), standard deviation (a measure of data spread), minimum, maximum, and quartiles. They help data analysts and scientists understand the central tendency, variability, and distribution of the data, which is crucial for making informed decisions about data preprocessing, feature selection, and modeling. Summary statistics also aid in identifying potential outliers or unusual patterns in the data.

Here’s what data.describe() does:
- Count: Shows the number of non-missing entries in each column.
- Mean: Provides the average value for each column.
- Std (Standard Deviation): Indicates the amount of variation or dispersion in each column.
- Min: The smallest value in each column.
- 25% (First Quartile): The value below which 25% of the data falls.
- 50% (Median): The middle value of the dataset.
- 75% (Third Quartile): The value below which 75% of the data falls.
- Max: The largest value in each column.
Let us explore the data even further with metadata. This step will provide us with more insights into the data’s structure and characteristics, enhancing our understanding of the dataset’s nuances.
Metadata

Metadata is an overview of the data itself. It’s the data about the data. Metadata provides a high-level summary about the characteristics of the dataset. It includes details such as the column names, the types of data contained in each column (numerical, textual, etc.), and the count of non-null entries in each column, among other aspects. The code snippet below is typically utilized to retrieve the metadata of a dataset.

Upon executing the code, a succinct summary is displayed, offering valuable insights into the various data types present and the memory usage in the dataset. This information is crucial for deeper analytical efforts. The output generated might begin as follows:
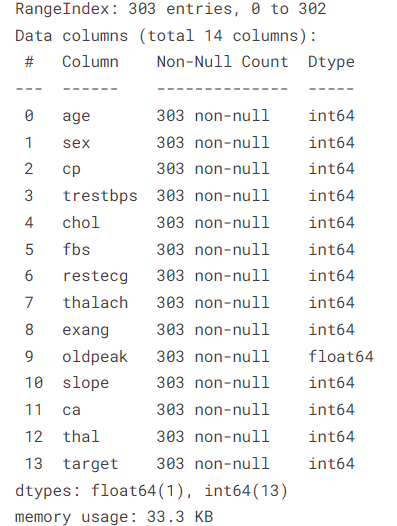
- Range Index: The dataset is indexed from 0 to 302, providing a unique identifier for each row.
- Columns: There are a total of 14 columns, each representing a different attribute related to heart health.
- Column Details: Each column’s non-null count is 303, indicating there are no missing values in any of the columns.
- Data Types: The dataset primarily consists of integer values (int64), with one column (‘oldpeak’) having floating-point values (float64).
- Memory Usage: The dataset consumes approximately 33.3 KB of memory.
This summary provides a quick overview of the dataset’s structure, size, and the types of data it contains, which is useful for preliminary data analysis and serves as a foundation for subsequent model building.
One of the key responsibilities of a data scientist or a machine learning practitioner is communicating findings to the stakeholders. So a part and parcel of the job is to create visualizations to communicate insights derived from the analysis of the data.
To illustrate this point, let’s take a look into specific visualizations, which highlight key health indicators and their association with heart disease.



- Cholesterol (chol): The top row of charts in the image relates to cholesterol levels among individuals with and without heart disease (target variable). The bar chart shows the count of individuals in each category, and the density plot displays the distribution of cholesterol levels, indicating how cholesterol varies for individuals with (1) and without (0) heart disease.
- Maximum Heart Rate (thalach): The middle row corresponds to the ‘thalach’ variable, which is the maximum heart rate achieved during exercise. Similar to the cholesterol charts, these visualizations compare the number of individuals with different heart disease statuses and illustrate the distribution of maximum heart rates among them.
- ST Depression (oldpeak): The bottom row chart pertains to ‘oldpeak’, which is the ST depression induced by exercise relative to rest. These charts show the prevalence of different ST depression levels in the heart disease and non-heart disease groups and the overall distribution of ‘oldpeak’ values.
Each bar chart included the number of cases for each category, providing a straightforward comparison between the groups. The density plots, shaded in red tones, offer insights into the probability density of the continuous variables for both groups, highlighting any significant differences or similarities in the distributions related to heart disease presence.
In summary, these visualizations are crucial for understanding how certain health indicators like cholesterol levels, maximum heart rate, and ST depression are distributed among individuals with and without heart disease. Such analysis is essential for identifying risk factors and understanding the characteristics of heart disease presence within a population.
So far, we have explored how data visualization helps in understanding some key insights in relation to heart disease. Building on these insights, we now turn our attention to the process of feature engineering, where we refine and transform data to further enhance model performance.
Feature Engineering
In the context of medical data analytics like heart disease prediction, one of the most important pre-work to model training is the process of feature engineering. Feature engineering involves transforming raw data into a refined format that is more conducive to analysis by machine learning models, thereby enhancing their ability to make accurate predictions.
Within the specialized field of predicting heart disease, the process of feature engineering typically encompasses several key steps. These include extracting meaningful attributes from patient data, handling missing values judiciously, encoding categorical variables, and normalizing or scaling numerical variables.
Additionally, it might involve generating new features through techniques such as aggregation or decomposition, and selecting the most relevant features (or columns) that contribute to the predictive accuracy of the model. By meticulously processing and preparing the dataset through these feature engineering techniques, we can significantly boost the model’s capacity to identify patterns and risk factors associated with heart disease, leading to more reliable and effective predictions.
Let’s explore some key aspects of feature engineering in heart disease prediction:
- Data Extraction and Refinement: Identifying and extracting meaningful patient data attributes and handling missing values carefully to maintain data integrity.
- Feature Transformation: Encoding categorical variables into a format suitable for machine learning models and normalizing or scaling numerical variables to ensure uniformity in data representation. This process involves adjusting the scale of all columns to a common measure,to ensure no single feature dominates the prediction process due to its size.
- Feature Creation and Selection: Creating new features through aggregation or decomposition and selectively including the most relevant features that enhance the model’s predictive accuracy.
- Optimization for Predictive Accuracy: The overall process aims to fine-tune and maximize the model’s ability to detect key patterns and risk factors for heart disease, thereby improving prediction reliability and effectiveness.
Having explored feature engineering, we now turn our attention to a crucial phase: Training the Model. This stage is critical in the journey of developing a machine learning model for medical purposes, where the pre-processed data, enriched with new features, will be utilized to train the model to accurately differentiate between healthy patterns and indicators of heart disease. With this essential groundwork established, let’s proceed to explore the intricacies of the model training process.
Training the Model
In this phase, the machine “learns” to differentiate between indicators of heart disease and normal health markers. The dataset is divided into separate groups for training and testing. This division is crucial as it ensures that the model is trained on one subset of data and tested on different, unseen data, which is vital for accurately assessing its performance. Additionally, the data undergoes standardization, meaning the range of values for each feature is adjusted to a standard scale, an important step for many machine learning models.
As previously mentioned, this article is not a comprehensive guide on machine learning; instead, its focus is on illustrating the application of machine learning in the context of heart disease detection.
The code snippets below lay the foundation for the subsequent stages in model training and heart disease analysis. While this code is not complete, it offers an insight into the programming involved in constructing and training the model for heart disease prediction.





Moving forward, we’ll delve into the Model Interpretation phase. Here, we talk about how our model helps identify heart disease. We won’t get into complex technicalities, but we’ll focus on why it’s important for the model to be both accurate and trustworthy. It’s about understanding that our model doesn’t just give us numbers or data; it helps us make sense of those numbers in the real world. In simpler terms, it’s not just about whether the model works, but about how it works and why we can rely on its decisions. This understanding is crucial for us to trust the model and to use it effectively in medical scenarios.
Model Interpretation

Model Interpretation in the realm of heart disease detection using machine learning involves how models process various data inputs like patient histories and test results to distinguish between healthy and at-risk individuals. This understanding is vital for transparency, building trust, and ensuring the model’s recommendations are based on sound medical evidence.
The importance of Model Interpretation extends to enhancing healthcare outcomes. By interpreting models accurately, healthcare providers can make more informed decisions, thus improving patient care. However, interpreting these “black box” models can be challenging, as it requires simplifying complex algorithms without losing essential details.
Incorporating key performance metrics like True Positives, True Negatives, False Positives, and False Negatives is crucial. Allow me to clarify these terms with specific reference to heart disease detection:
- True Positives (TP): Correct predictions of heart disease.
- True Negatives (TN): Correct identifications of no heart disease.
- False Positives (FP): Incorrectly identifying healthy individuals as having heart disease, leading to unnecessary stress and testing.
- False Negatives (FN): Failing to detect heart disease in affected patients, potentially delaying crucial treatment.
These metrics are pivotal in evaluating a model’s performance, especially in a sensitive field like heart disease detection. For instance, a high number of False Negatives could be life-threatening, whereas a high number of False Positives could lead to over-testing and increased patient anxiety.
True Positives are crucial because they directly measure the ability of a classifier to correctly identify positive cases, which, in the context of heart disease, means correctly identifying patients with the disease. This metric is not only an index of the model’s ability to classify positive cases but also forms the basis for other important metrics like recall, precision, and the F1 score (explanations of recall, precision, and the F1 score will follow in the upcoming section) [8]. These are used in evaluating and optimizing model performance, especially in terms of its sensitivity to detecting the condition accurately.
Similarly, True Negatives are significant as they reflect the model’s ability to correctly identify cases where the disease is not present. This helps in reducing unnecessary stress and medical interventions for patients wrongly identified as at-risk.
In the process of model evaluation, the balance between True Positives and True Negatives is crucial. Overemphasis on maximizing True Positives might lead to increased False Positives (incorrectly identifying healthy individuals as having the disease), which can have negative consequences. Therefore, it’s essential to consider both these metrics in conjunction, along with other metrics like False Positives and False Negatives, to achieve a comprehensive evaluation of the model’s performance.
Additionally, the selection of an appropriate classification threshold in the model can significantly influence the number of True Positives and True Negatives. This threshold determines how the model classifies a case as positive or negative based on the predicted probability, and adjusting it can optimize the balance between True Positives and False Positives.
In summary, aiming for high numbers of True Positives and True Negatives is an integral part of model evaluation, especially in fields like heart disease detection, where the stakes of accurate diagnosis are high. The balance and optimization of these metrics ensure that the model is not only effective but also reliable and safe for clinical use.
We touched upon model evaluation very briefly earlier. Model evaluation is another crucial aspect, which involves assessing the effectiveness of a machine learning model using various metrics. Some of the metrics that are commonly used are: accuracy, precision, recall and F1 score.
Accuracy measures the overall correctness of the model, while precision looks at the proportion of positive identifications that were actually correct. Recall, or sensitivity, assesses how well the model identifies true positives among the actual cases. The F1 score provides a balance between precision and recall, offering a more holistic view of the model’s performance.
The confusion matrix is a useful tool in this context, providing a visual representation of the performance of an algorithm, showing the correct and incorrect predictions compared to the actual realities. It lays out True Positives, True Negatives, False Positives, and False Negatives in a matrix format, allowing for a clear understanding of the model’s performance and areas where it may need improvement.
In conclusion, model Interpretation and evaluation, encompassing understanding of metrics like precision, accuracy, recall, the F1 score, and the use of tools like the confusion matrix, are integral in the deployment of machine learning models in heart disease detection. These processes ensure the models are not only powerful but also reliable, transparent, and effective in real-world medical applications. They bridge the gap between advanced technology and practical medical application, crucial for improving patient care and in early heart disease treatment outcomes and beyond.
- Key Takeaways
- The article began with the role of machine learning in revolutionizing healthcare, and traced the impact of technological advancement on the substantial increase in life expectancies worldwide. Central to this progress are machine learning algorithms that proficiently analyze extensive medical data, enabling more accurate and timely disease diagnoses. Highlighting key studies by Choi, S. J., Lee, and colleagues, as well as Muhammad et al. , the article showcases the effectiveness of machine learning models in identifying early indicators of conditions like hepatitis (liver disease) and myocardial infarction (heart attack). These examples serve to illustrate the potential of machine learning in enhancing healthcare outcomes. Beyond just an overview, the article provides practical insights into machine learning applications in healthcare, using some code snippets from Kaggle. The article aimed not to delve into technical details but to showcase machine learning’s role in enhancing the quality of our lives, with a hope to inspire readers to explore the fields of data science and machine learning further.
Next Steps
- AI and Machine Learning Specialists top the list of fast-growing jobs, followed by Sustainability Specialists and Business Intelligence Analysts [9]. This insight from the World Economic Forum’s 2023 report highlights the growing demand in these fields. To position yourself advantageously in the job market, consider WeCloudData’s bootcamps. With real client projects, one-on-one mentorship and hands-on experience in our immersive programs, it’s an opportunity to develop expertise in AI and machine learning, aligning your skills with the current and future needs of the job market. Set yourself up for success in a dynamic and rewarding career, take action now!
Read More
https://weclouddata.com/blog/
References
[1] Statistics Canada, “Life expectancy, 1920–1922 to 2009–2011,” on Statistics Canada website, accessed January 26, 2024, https://www150.statcan.gc.ca.
[2] Canada Protection Plan, “What is the Life Expectancy In Canada?” accessed January 26, 2024, https://www.cpp.ca/what-is-the-life-expectancy-in-canada/.
[3] Countrymeters, “Canada population (2024) live,” accessed January 26, 2024, https://countrymeters.info/en/Canada.
[4] Journal of Electrical Systems and Information Technology (2023). Healthcare predictive analytics using machine learning and deep learning techniques: a survey. Retrieved from https://jesit.springeropen.com/articles/10.1186/s43067-023-00108-y
[5] Choi, S. J., Lee, J., Kang, J. Y., Park, J. H., & Lee, K. Y. (2021). Development of machine learning model for diagnostic disease prediction based on laboratory tests. Scientific Reports, 11(1), 1-14. Nature Publishing Group.
[6] Muhammad, Y., Tahir, M., Hayat, M., & Chong, K. T. (2020). Early and accurate detection and diagnosis of heart disease using intelligent computational model. Scientific Reports, 10(1), Article number: 19747. Nature Publishing Group.
[7] Journal of Electrical Systems and Information Technology (2023). Healthcare predictive analytics using machine learning and deep learning techniques: a survey. Retrieved from https://jesit.springeropen.com/articles/10.1186/s43067-023-00108-y
[8] Sharp Sight. (n.d.). True Positive, Explained. Sharp Sight Labs. Retrieved January 29, 2024, from https://www.sharpsightlabs.com/blog/true-positive/
[9] World Economic Forum (2023). “Future of Jobs Report 2023.” Retrieved from www.weforum.org/publications/the-future-of-jobs-report-2023.
