
Days before embarking on a recent trip, I received an email from American Express stating “Based on recent transactions, it appears that you may be traveling soon. We use industry-leading fraud detection capabilities and do not need to be notified of travel plans in advance to recognize when our Card Members are traveling.” [1]. Keep this thought while we get back to it.
Financial institutions are under constant threat from various types of sophisticated fraud, including identity theft, credit card fraud, and cyber attacks. The repercussions of these fraudulent activities are not just financial. They also erode customer trust, damage the bank’s reputation, and present legal challenges.
The traditional methods of fraud detection, which often rely on rule-based systems, have proved to be inadequate in the face of cleverly orchestrated frauds that can easily bypass these rules.
Moreover, the sheer volume of transactions and the complexity of financial operations make manual
monitoring an impractical, if not impossible, task. Phishing attacks, identity theft, and complex cybercrimes are evolving, making it harder for banks to keep up using conventional fraud detection methods.
This is where data science and machine learning come into play. The introductory paragraph highlights two key aspects. Firstly, it illustrates the practical application of machine learning in detecting abnormal transactions by financial institutions. Secondly, it underlines the broader challenges faced by the banking industry in combating sophisticated fraudulent activities. This dual focus not only provides context to the importance of fraud detection in banking using machine learning but also sets the stage for further discussion on the complexities and necessities of fraud detection technologies in the financial sector.
The banking industry is increasingly turning towards machine learning technologies for several compelling reasons. For example, American Express has long been at the forefront of transaction monitoring and fraud detection. In 1988—at a time when merchants had to call American Express for large credit authorizations over the phone—an American Express employee had to make a quick judgment call to determine if payment could be authorized.
American Express leveraged expert systems, a then-cutting-edge technology that used conditional statements and data from up to 13 databases, to determine if a purchase was in line with the customer’s transaction history [2]. Three decades later, financial institutions around the world continue to combat credit card fraud, collectively spending $27.7 billion on card fraud costs in 2017. In 2021, worldwide payment card fraud losses exceeded $32 billion, indicating a growing trend in such financial crimes [3]. Credit card fraud in the United States alone is projected to be $12.5 billion by 2025 [4].
With the advancement of artificial intelligence (AI), machine learning and data mining have been utilized to detect fraudulent activities in the financial sector [5,6] . Classification methods have been the most popular method for detecting financial fraudulent transactions. In this scenario, the first stage of model training uses a dataset with class labels and features. The trained model is then used to classify test samples in the next step [7,8,9].
In simpler terms, class labels are like the answers in the back of a textbook used by a student (the algorithm) to learn. They provide a clear guide on what the correct output for each input data point should be during the training process. This enables the model to make accurate predictions or classifications when it encounters new data that it has not seen before.
An analogy to help understand features in machine learning could be comparing them to ingredients in a recipe. Imagine you’re trying to teach someone how to cook various dishes. Each dish (like each data point in machine learning) is defined by a specific set of ingredients (features or columns). For example, to make a particular dish, such as a cake, you need defined amounts of flour, sugar, eggs, and butter. Each of these ingredients represents the features that make up the “feature vector” of the cake.
With this background in mind, let’s roll up our sleeves and take a look at some code snippets to see fraud detection in banking using machine learning. The intent of this blog article is not to dive deep into the intricacies of machine learning, but rather to give readers a taste of its fascinating world for fraud detection in banking using machine learning and spark enough curiosity to begin your own journey in data science and machine learning.
The code snippets in this article are sourced from a Kaggle notebook by Fares Sayah, titled “Credit Card Fraud ANNs versus XGBoost”. Kaggle is a platform that provides a community for data scientists and machine learning practitioners to explore, analyze, and share quality data sets and build machine learning models. It offers a collaborative environment where users can participate in competitions, access a broad range of datasets, and gain insights from other professionals in the field.
With this background in mind, let’s roll up our sleeves and take a look at some code snippets to see fraud detection in banking using machine learning techniques.
Continuing from our previous discussion on Kaggle, the code snippet shown here sets up the basic tools for data analysis and visualization. It imports popular Python libraries like pandas and numpy for data handling, and matplotlib and seaborn for creating visualizations.

The code snippet below loads a dataset named ‘creditcard.csv’ from a specified path on Kaggle into a pandas DataFrame, a structure used for data manipulation in Python.

The data.head() function is used to display the first few rows of this dataset, providing a quick glimpse into the types of data available, such as transaction details, which are crucial for identifying potential fraud patterns. This step is a fundamental part of the data exploration process in machine learning and data science projects.
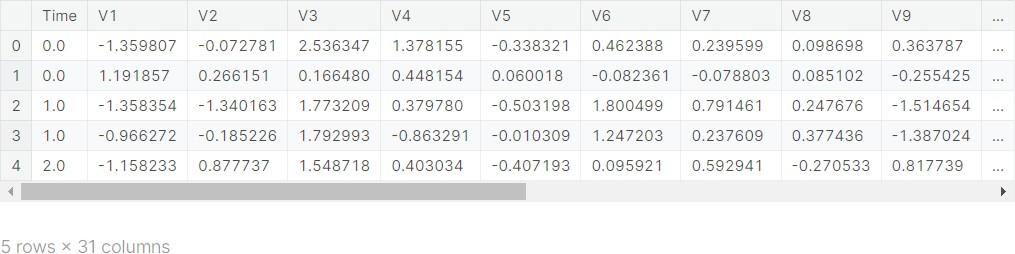
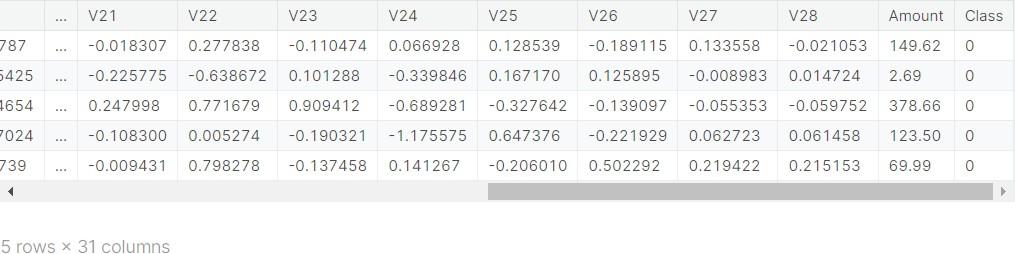
Now, let’s unravel the ‘features’ or the columns of the dataset:
Time Stamp: The ‘Time’ column is not your regular clock time. Instead, it represents the seconds elapsed between each transaction and the first transaction in the dataset. Think of it as a stopwatch counting up from the start of the data collection.
Mysterious V’s: The columns labeled from ‘V1’ to ‘V28’ have been transformed for confidentiality. While their true identities are hidden, they play a crucial role in understanding the patterns in transactions.
Transaction Amount: The ‘Amount’ column is straightforward – it’s the amount of money involved in the transaction. This could range from small purchases to significant expenditures.
Classifying Fraud: Finally, the ‘Class’ column is the key to our detective story. It tells us whether a transaction is fraudulent (‘1’) or not (‘0’). This is what the machine learning model is trying to predict.
Let us explore the data even further with metadata. This step will provide us with more insights into the data’s structure and characteristics, enhancing our understanding of the dataset’s nuances.
Metadata

What is metadata though? Metadata is an overview of the data itself. It’s the data about the data.
The code snippet below provides a high-level overview of the structure of the dataset. It shows the names of the columns, the type of data each column holds (like numbers, text, etc.), and the number of non-missing entries in each column and so forth.
After running this code, you’ll see a concise summary, giving us insights into the types of data we are working with and preparing us for deeper analysis. For example, the output might start with something like this:
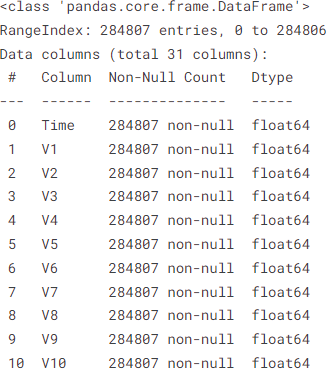
While the output above only shows the details up to row 10 of the .info() output. It’s important to note that the summary continues beyond this point. Here’s what the entire output includes:
<class ‘pandas.core.frame.DataFrame’>: This indicates that we store our data in a DataFrame, which organizes data into a table.
RangeIndex: 284807 entries, 0 to 284806: This tells us that there are 284,807 rows (or entries) in the dataset. The index (or row labels) range from 0 to 284,806.
Data columns (total 31 columns): Here, we learn that our dataset has a total of 31 columns.
Column Details:
#: This is just a column number for reference.
Column: This is the name of the column. In our example, the first column is ‘Time’.
Non-Null Count: This indicates the number of non-missing values. For ‘Time’, all 284,807 entries are non-null, meaning there are no missing values in this column.
Dtype: This stands for data type. The data type of the ‘Time’ column is ‘float64’, which means it contains floating-point numbers.
As the summary progresses, it provides similar details for each of the 31 columns, including names like ‘V1’, ‘V2’, … up to ‘V28’, ‘Amount’, and ‘Class’. Each column’s non-null count and data type are provided, offering a comprehensive overview of the dataset’s structure and health.
Remember, while you don’t see the entire output, the summary provided by .info() is exhaustive, covering each column’s essential details. This high-level view is invaluable as it prepares us for the next steps in our data analysis journey, ensuring we have a solid understanding of the dataset’s composition.

To delve even deeper into our dataset, we use another powerful pandas function: data.describe(). This command gives us a statistical summary of all numerical columns in our dataset. Before running this, we set an option with pd.set_option(“display.float”, “{:.2f}”.format) to format the output. Format the floating-point numbers so that they are displayed with just two decimal places for easier reading.
Here’s what data.describe() does:
Count: Shows the number of non-missing entries in each column. Mean: Provides the average value for each column.
Std (Standard Deviation): Indicates the amount of variation or dispersion in each column. Min: The smallest value in each column.
25% (First Quartile): The value below which 25% of the data falls. 50% (Median): The middle value of the dataset.
75% (Third Quartile): The value below which 75% of the data falls. Max: The largest value in each column.
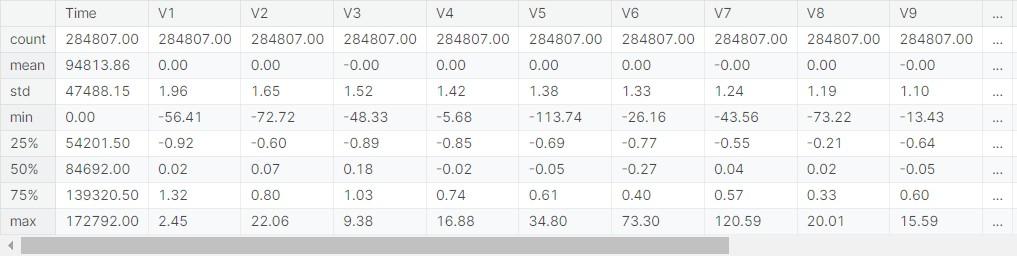
This summary is incredibly useful for getting a sense of the scale and distribution of our numerical data. For example, in the context of our credit card fraud dataset, it helps us understand typical transaction amounts, how varied these amounts are, and if there are any extreme values that could indicate outliers or unusual activity.
The code below creates a bar chart that illustrates the frequency of normal and fraudulent
transactions in the dataset. The ‘Normal’ and ‘Fraud’ labels are assigned to the two distinct classes of transactions (namely 0 and 1), and the chart is titled “Transaction Class Distribution.” The resulting visualization makes it easy to compare the number of transactions in each class at a glance, highlighting any imbalances between normal and fraudulent activity.

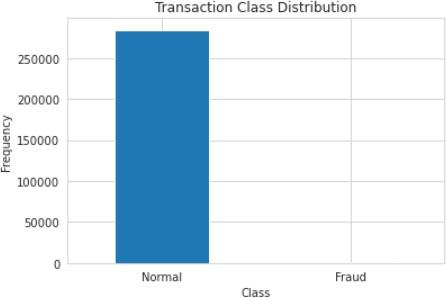
From the image, we can observe the following:
There’s a single bar labeled “Normal” that has a very high frequency, indicating a large number of normal transactions.
The bar labeled “Fraud” is not visible, which suggests that the number of fraudulent transactions is much smaller in comparison to normal transactions.
This chart visually communicates the significant imbalance between the two classes of transactions. Such imbalance typically occurs in fraud detection datasets, where fraudulent activities are relatively rare compared to normal ones. This is a crucial insight because it highlights the challenges in modeling such data — the model needs to be sensitive enough to detect the rare event of fraud without being overwhelmed by the vast number of normal transactions.
If you have come this far, kudos to you! Stick with me, I promise this is going to be worthwhile!
Feature Engineering


One of the most important pre-work to model training is the process of feature engineering. Feature engineering involves taking the raw data and refining it into more useful inputs for your model. This can significantly improve its predictive power. Here are some steps that might be taken in feature engineering for the credit card fraud detection dataset:
Handling Imbalanced Data: Fraudulent transactions are often much less common than legitimate ones. To address this imbalance, techniques like SMOTE can generate synthetic examples of the minority class (in this case fraudulent credit card transactions), helping the model to learn more about these rarer fraudulent cases.
Feature Creation: Develop new features (or columns) that may highlight patterns indicative of fraud, such as aggregating transactions over specific timeframes to detect unusual bursts of activity.
Feature Selection: This involves choosing a subset of the available features that are most informative or important for the model’s performance. It’s a crucial step in feature engineering as it helps improve model training speed, and potentially enhance model generalization by removing irrelevant or redundant features.
Normalization/Standardization: By adjusting the scale of all columns to a common measure,
we ensure no single feature dominates the prediction process due to its size.
Having refined our dataset through feature engineering, we now enter a crucial phase: Training the Model. This step is pivotal in the journey of machine learning model development, where the pre- processed data, with its new features, will be used to teach the model to discern between normal and fraudulent transactions effectively. With this groundwork in place, let’s delve into the model training process.
Training the Model for Fraud Detection
This is where the fun stuff happens – the machine learning part. Here the machine “learns” to distinguish between fraudulent and non-fraudulent transactions. Here, we will split the dataset into separate groups for training, validation, and testing. This step ensures that the model is trained on one set of data and validated and tested on different, unseen data, which is essential for evaluating its performance accurately. Additionally, the data is standardized, which means adjusting the range of values for each feature to a standard scale, a vital step for many machine learning models. The code also computes weights for fraudulent and non-fraudulent transactions, addressing the earlier mentioned data imbalance and helping the model to better understand and learn from these patterns.
The code snippet below forms the groundwork for the next steps in model training and fraud detection in banking using machine learning. While the code itself is not complete, but it gives a glimpse of the code that builds & trains the model.

As explained in the introduction, the aim of this article is not to provide an exhaustive tutorial on machine learning, but rather to highlight its application in fraud detection and give a bird’s eyeview. With this scope in mind, we now transition to the Model Interpretation phase. This involves understanding how well our model performs in distinguishing between fraudulent and legitimate transactions.
Model Interpretation

Model interpretation in the context of machine learning refers to the process of understanding the decisions or predictions made by a machine learning model. This involves analyzing how the model uses its input features (‘features’ refer to the input variables or columns in a dataset that are utilized to train a machine learning model) to make predictions and determining the significance and impact of each feature on the model’s outcome.
When discussing model interpretation in the context of machine learning, it’s relevant to mention performance metrics such as accuracy, confusion matrix, and F1 score. These metrics provide valuable insights into how well the model is performing in distinguishing between fraudulent and legitimate transactions. Here’s a brief explanation of each:
Accuracy: Accuracy is a commonly used metric that measures the overall correctness of the model’s predictions. You can calculate it through the ratio of correct predictions to the total number of predictions. While accuracy is important, it may not be the best metric to assess model performance. Especially in cases of imbalanced datasets where one class (e.g., fraudulent transactions) is much less common than the other.
Confusion Matrix: A confusion matrix is a table that provides a detailed breakdown of a model’s
performance by showing the number of true positives, true negatives, false positives, and false negatives. It is particularly useful in understanding how the model is making errors. You can use this to calculate other metrics like precision, recall, and F1 score.
F1 Score: The F1 score is a metric that combines precision and recall into a single value.
Precision measures the accuracy of positive predictions, while recall (or sensitivity) measures the ability of the model to identify positive instances. The F1 score is the harmonic mean of precision and recall and is useful when you want to balance both false positives and false negatives.
Including these metrics on model interpretation can help provide a comprehensive evaluation of the model’s performance and how it’s making decisions. Additionally, there are techniques like feature importance analysis, SHAP (SHapley Additive exPlanations), and LIME (Local Interpretable Model-
agnostic Explanations) to delve deeper into understanding the significance and impact of each feature on the model’s predictions.
Model interpretation is crucial for validating the model’s reliability, ensuring that it makes decisions for the right reasons, and it is especially important in fields like fraud detection in banking using machine learning where understanding the rationale behind a prediction is as important as the prediction itself. This process helps in making the model’s decision-making transparent and comprehensible, which is vital for trust and actionable insights in real-world applications.
You might be asking, why is model interpretation so crucial? Model interpretation’s importance lies in its necessity for compliance, accountability and transperancy. For instance, during external audits, explaining why a model declined a loan application is crucial in the banking industry. It is not only about compliance, but also about ensuring fairness and avoiding biases in decision-making.
For a data scientist or machine learning engineer, accurate model interpretation is fundamental because it validates the model’s integrity. Understanding the model’s decision process enables professionals to refine the model, enhancing its accuracy and reliability, which is essential for maintaining trust in automated decision-making systems.
Key Takeaways
The banking industry faces significant challenges due to sophisticated fraudulent activities, such as credit card fraud, identity theft and cyberattacks. This article highlighted how traditional, rule- based fraud detection methods are often insufficient against these evolving threats. Fraud detection in banking using machine learning, as demonstrated through the code snippets, emerges as a pivotal tool in combating fraud. It offers advanced detection capabilities, adapting to new fraud patterns and processing large volumes of transactions efficiently. The article aimed not to delve into technical details but to showcase fraud detection in banking using machine learning, with a hope to inspire readers to explore the fields of data science and machine learning further.
Next Steps
Technology-related roles are the fastest growing jobs in percentage terms, including Big Data Specialists, Fintech Engineers, AI & Machine Learning Specialists and Software Developers [8]. This insight from the World Economic Forum’s 2025 report highlights the growing demand in these fields. To position yourself advantageously in the job market, consider WeCloudData’s bootcamps. If you want to become a machine learning engineer and don’t know where to start, consider joining WeCloudData’s AI and Machine Learning bootcamp. Earn your Machine learning Certificate today! With real client projects, 1-on-1 mentorship, and hands-on experience in our immersive programs, it’s an opportunity to develop expertise in AI and machine learning. Align your skills with the current and future needs of the job market. Set yourself up for success in a dynamic and rewarding career; take action now!
References
- American Express <AmericanExpress@welcome.aexp.com>, “Helpful Information for Your Upcoming Trip,” email message to Andrew Harris, April 10, 2018.
- Dorothy Leonard-Barton and John Sviokla. March 1988. “Putting Expert Systems to Work”.
Harvard Business Review. https://hbr.org/1988/03/putting-expert-systems-to-work.
- The Nilson Report. (2022, December 22). “Payment Card Fraud Losses Reach $32.34 Billion.” GlobeNewswire. Retrieved from globenewswire.com.
- Merchant Cost Consulting (2024). “Credit Card Fraud Statistics.” Retrieved from www.merchantcostconsulting.com.
- Chaquet-ulldemolins, J.; Moral-rubio, S.; Muñoz-romero, S. On the Black-Box Challenge for Fraud Detection Using Machine Learning (II): Nonlinear Analysis through Interpretable Autoencoders. Appl. Sci. 2022, 12, 3856.
- Da’U, A.; Salim, N. Recommendation system based on deep learning methods: A systematic review and new directions. Artif. Intell. Rev. 2019, 53, 2709–2748.
- Hilal, W.; Gadsden, S.A.; Yawney, J. Financial Fraud: A Review of Anomaly Detection Techniques and Recent Advances. Expert Syst. Appl. 2021, 193, 116429.
- Ashtiani, M.N.; Raahemi, B. Intelligent Fraud Detection in Financial Statements Using Machine Learning and Data Mining: A Systematic Literature Review. IEEE Access 2021, 10, 72504–72525.
- Ngai, E.W.T.; Hu, Y.; Wong, Y.H.; Chen, Y.; Sun, X. The application of data mining techniques in financial fraud detection: A classification framework and an academic review of literature. Decis. Support Syst. 2011, 50, 559–569.
- World Economic Forum (2025). “Future of Jobs Report 2025.” Retrieved from https://reports.weforum.org/docs/WEF_Future_of_Jobs_Report_2025.pdf.
