Building strong models or innovative solutions is only half the battle in today’s data-driven world; the other half is effectively kubernetes deployment, scaling, and maintaining these applications. Whether you’re a data scientist moving your machine learning model from notebook to production, an AI engineer making sure models handle thousands of real-time queries, or a DevOps specialist streamlining complex application workflows, infrastructure issues will likely arise. That’s where Kubernetes comes in.
This blog will explain Kubernetes, how it works, and why it matters to your role. We’ll highlight practical use cases and how WeCloudData supports teams and individuals through hands-on training, one-on-one consultations, and end-to-end project guidance.
Understanding Kubernetes: What It Is and How It Works
Kubernetes, also known as K8s, is an open-source system for automating containerized applications’ deployment, scaling, and management, so you don’t have to manage infrastructure manually.
To understand Kubernetes, understanding the concept of containers is very important. Containers are basically lightweight, portable, and self-sufficient environments that include everything needed to run an application, like code, runtime, system tools, and libraries.
Docker is the most widely used platform to create and run these containers. Although Docker makes it easier to develop and execute containers, managing several containers across hundreds or thousands of machines becomes complicated over time, particularly in production. That’s where Kubernetes enters the picture. K8s helps manage those containers at scale across clusters of machines with minimal downtime and maximum efficiency, acting as a conductor of a container orchestra.
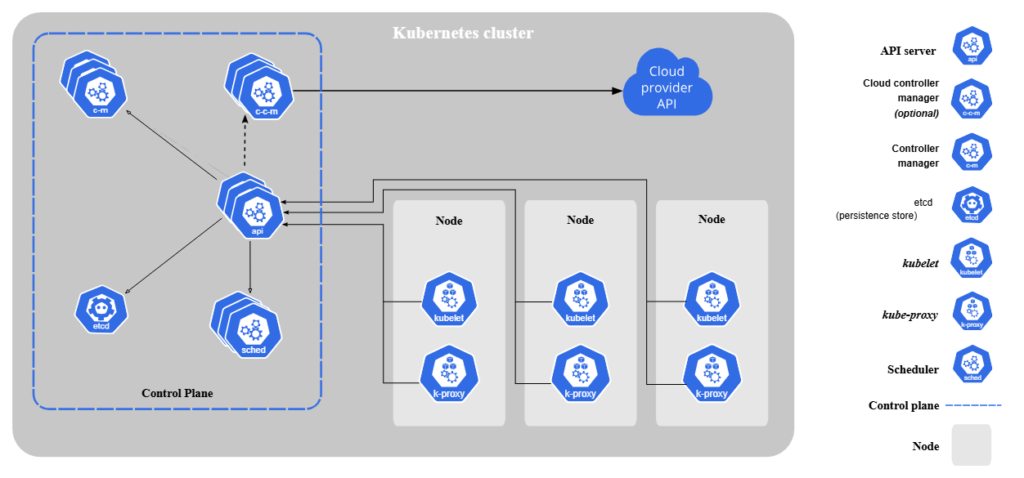
Kubernetes Architecture (Core Components)
Kubernetes is are very powerful technology. Understanding kubernetes architecture is key to understanding its power. Here are the core components explained briefly.
1. Cluster
A collection of real or virtual machines running containerized apps is called a Kubernetes cluster. Every cluster has one or more worker nodes and at least one control plane.
2. Node
A node is a single machine in the cluster. It can be a physical server or a Virtual Machine. A node is responsible for running pods. Every node has the Docker, kubelet, and kube-proxy services required to run the containers.
3. Pod
In Kubernetes, the pod is the smallest deployable unit. A pod can include one or more containers sharing the same network, storage, and characteristics. Think of it as a wrapper around your application.
4. Control Plane
The control plane is the brain of Kubernetes, managing the overall structure of the cluster. It is responsible for health monitoring, app schedules, scaling, scheduling workloads, and responding to failures. Its components include:
- Kube-scheduler: Assigns pods to nodes.
- Kube-controller-manager: Manages node states, replication, etc.
- kube-apiserver: Handles API requests.
- etcd: Stores cluster data.
5. Kubelet & Kube Proxy
Every node has a kubelet that communicates with the control plane and a kube-proxy that manages external traffic and pod networking.
Why Kubernetes Matters Today
In the era of edge computing, hybrid cloud, and microservices architecture, Kubernetes has emerged as a standard for declarative, automated, and scalable infrastructure management. The infrastructure of well-known businesses like Google, Spotify, Shopify, and Airbnb depends on Kubernetes.
Regardless of your field, DevOps, AI, or data science, Kubernetes is more than just a deployment tool. K8s enables experimentation, quick prototyping, reproducibility, and robust production-level infrastructure.
Kubernetes in Action: Real-World Use Case
In addition to its technical design, Kubernetes’s capacity to revolutionize workflows across industries and roles makes it more interesting. The kubernetes deployment makes everything easier, faster, and more intelligent, whether developing recommendation engines, maintaining data lakes, or implementing APIs that service millions of users. Let’s learn how various IT experts use Kubernetes in their day-to-day work.
Data Scientists: More Focus on Science, Less on Setup
Kubernetes allows data scientists to build, train, and deploy machine learning models at scale. Data professionals use millions of records to train a neural network. With Kubernetes, data professionals don’t need to worry about the ML model collapsing overnight or if their Python environment contradicts itself. With Kubernates;
- Model reproducibility is easier through standardized container environments.
- Batch jobs for data preprocessing can be efficiently scheduled. Popular tools like Kubeflow run seamlessly on Kubernetes, enabling full machine learning workflows within a unified infrastructure from training to deployment.
AI Engineers: Scaling Inference Like a Pro
An AI engineer built a killer model, now the next step? Hosting it on a single server isn’t scalable, and AI systems are resource-hungry and often need GPUs. Kubernetes helps by:
- Utilizing node selectors and tolerations to allocate GPU-enabled nodes effectively.
- Using rolling updates to manage model kubernetes deployment and versioning, while scaling them automatically.
- High availability and cost-effectiveness are ensured by autoscaling based on inference load.
Use case: An AI research centre uses a Kubernetes cluster with auto-scaling and GPU scheduling to deploy several language model versions for clients in various locations.
DevOps: The Backbone of Automation
Kubernetes is at the heart of modern DevOps. It provides:
- CI/CD integration through tools like ArgoCD and Jenkins X.
- Roll back faulty deployments instantly.
- Monitor everything with dashboards and alerts without leaving your cloud environment.
Kubernetes Use case: A data consulting company integrates Prometheus monitoring and real-time logging with Kubernetes to host over thirty microservices for their analytics dashboard.
Big Data & Analytics
For big Data engineers running Spark or Hadoop. Kubernetes ;
- Guarantees scalable, dispersed, and safe data pipelines for hybrid or multi-cloud environments.
- Host distributed training frameworks like Ray or Dask.
- Provide secure, shared Jupyter notebooks for collaborative data exploration.
- Replace static clusters with dynamic, on-demand Spark jobs.
Getting Started with Kubernetes – and How WeCloudData Helps
Kubernetes adoption may seem intimidating, particularly for people switching from single-container or traditional infrastructure settings. But with the right guidance and resources, it’s manageable.
Starting with Kubernetes: Tools and Resources
- For beginners, Kubernetes.io provides a comprehensive tutorial and downloadable materials.
- Kind (Kubernetes in Docker) is ideal for experimentation because it enables you to start up a local Kubernetes cluster quickly.
- Cloud-native platforms like GCP (Google Kubernetes Engine), Azure AKS, and AWS EKS offer managed Kubernetes solutions, which simplify setup and maintenance.
Where WeCloudData Comes In!
At WeCloudData, we understand that learning Kubernetes is just the beginning. Our consulting and training services are designed for:
- Data Scientists & AI Engineers: Deploy ML models with Kubeflow or TensorFlow Serving.
- DevOps Professionals: Build robust CI/CD pipelines using Kubernetes-native tools.
- Enterprise Clients: Our expert team offers 1-on-1 consultations, infrastructure audits, and custom deployment strategies for production-grade Kubernetes clusters.
Whether you’re a startup exploring microservices or an enterprise migrating to the cloud, WeCloudData provides real-world project support that bridges the gap between learning and doing.
Learn with WeCloudData: Upskill Your Team in Cloud & Data Technologies
Looking to empower your team with the latest in cloud computing, data engineering, and AI technologies? WeCloudData’s Corporate Training programs are tailored to meet the needs of forward-thinking companies. With hands-on, expert-led instruction, our courses are designed to bridge the skills gap and help your organization thrive in today’s data-driven economy.
Upskill with WeCloudData: Become a Cloud Engineer & Analytics Leader
Our Cloud Engineer Track delivers a comprehensive, hands-on approach to cloud engineering, equipping you with the skills to design, deploy, and manage secure, scalable, multi-cloud environments. The courses included in the cloud computing learning track include;
