On a lazy Sunday afternoon, in search of some entertainment, I turned to Netflix. Logging into my account, I was greeted by a carefully curated world of entertainment tailored just for me. You’ve likely experienced this phenomenon too. But how does this happen? This isn’t mere coincidence or magic; it’s the result of sophisticated machine learning algorithms working behind the scenes. They analyze your past selections, viewing habits, and even how often you pause or skip. This personalized experience is a testament to the impact of machine learning in entertainment industry, especially in refining movie recommendations.
Consider Netflix, a familiar household name, and its revolutionary use of machine learning to redefine entertainment. Netflix uses machine learning to analyze your viewing, rating, and browsing habits for personalized recommendations. This data-driven approach allows Netflix to curate a unique viewing experience for each user, suggesting content that aligns closely with their tastes. The system is sophisticated, continually learning and evolving based on user feedback and interactions, ensuring that recommendations become increasingly accurate and relevant over time. Personalization drives Netflix’s success by boosting user satisfaction and engagement through seamless, enjoyable content discovery. [1].
In “Netflix Recommendations: Beyond the 5 Stars (Part 2),” Xavier Amatriain and Justin Basilico from Netflix’s Personalization Science and Engineering team delve deeper into the components of Netflix’s personalization technology. They discuss the evolution of the recommendation system beyond the $1M Netflix Prize, emphasizing the shift from merely predicting movie ratings to a more nuanced approach to personalization [2]. The $1M Netflix Prize was a publicly open contest aimed at improving the accuracy of Netflix’s recommendation engine through the prediction of film ratings by users.
At the heart of Netflix’s recommender system is the ranking function, which sorts items in order of expected enjoyment. This function moves beyond simple metrics like item popularity to incorporate a wide variety of information, balancing both popularity and predicted ratings to achieve a personalized ranking. This linear combination of popularity and predicted rating, represented as
Netflix’s approach to data and models is equally sophisticated. With several billion item ratings and millions of new ratings and stream plays each day, along with rich item metadata and social data, Netflix has a vast array of data sources at its disposal. This abundance of data, combined with a variety of machine learning methods enables Netflix to continually refine and enhance its recommendation algorithms.
The company’s culture of Consumer (Data) Science and the iterative process of A/B testing play a crucial role in this continuous improvement. By starting with a hypothesis and designing tests to measure engagement and retention, Netflix allows data to guide its innovations, ensuring that its service remains responsive to user preferences and behavior.
This integrated approach to personalization, leveraging both the breadth of available data and the depth of machine learning techniques, underscores Netflix’s commitment to enhancing user satisfaction and engagement. By making content discovery seamless and enjoyable, Netflix not only redefines the entertainment landscape but also demonstrates the power of machine learning in creating personalized experiences that resonate with its users.
In a McKinsey article, Tey Bannerman discusses how generative AI enables the creation of content and advertising that is individually tailored, enhancing customer engagement and experience. This technology allows for a significant shift from generic to personalized interactions, mirroring Netflix’s approach but on a wider scale across various industries. However, Bannerman also cautions about the importance of ethical considerations and the responsible use of consumer data to avoid invasive personalization practices [3]. This perspective underscores the importance of balancing innovation with consumer privacy and trust, a principle that is central to Netflix’s strategy and increasingly relevant across all sectors leveraging machine learning entertainment personalization.
Drawing from the latest research and developments in machine learning, it’s clear that the future of entertainment personalization is on the cusp of even more significant advancements. Innovations in AI algorithms and their application in analyzing viewer data can lead to more nuanced and dynamic content recommendations [4]. These advancements promise to make content discovery even more personalized, aligning closely with individual preferences and viewing habits.
Please note that the aim of this article is to showcase the practical utility of machine learning in enriching our everyday lives, rather than to explore its technical complexities. We aim to illuminate the fascinating applications of machine learning, hoping to spark an interest that encourages further exploration into data science and machine learning. This article will delve into how machine learning techniques are revolutionizing the entertainment industry, with a particular focus on customizing movie recommendations, thereby transforming how we discover and enjoy content.
That being said, let’s take a look at some code snippets to see machine learning for movie recommendations in action.
The code snippets in this article are sourced from a Kaggle notebook by Ibtesam Ahmed, titled “Getting Started with a Movie Recommendation System”. Kaggle is a platform that provides a community for data scientists and machine learning practitioners to explore, analyze, and share quality data sets and build machine learning models. It offers a collaborative environment where users can participate in competitions, access a broad range of datasets, and gain insights from other professionals in the field.
Continuing from our previous discussion on Kaggle, this code snippet below sets up the foundation for a machine learning project focused on customizing movie recommendations. It includes importing essential libraries, such as numpy and pandas for data manipulation. This setup is crucial for exploring, cleaning, and understanding data before applying any machine learning models, making it a foundational step in any data science project.

The code below loads a datasets named ‘tmbd_5000_credits.csv’ and ‘tmbd_5000_movies.csv’ from a specified path on Kaggle into a Pandas DataFrame, which is a structure used for data manipulation in Python.

The .head() function is used to display the first five rows of this dataset.

Movies dataset overview – top five rows:

The two datasets contain the following features (also referred to as attributes or column names)
First Dataset (credits dataset):
- movie_id: A unique identifier for each movie.
- cast: The name of lead and supporting actors.
- crew: The names of the Director, Editor, Composer, Writer, etc.
Second Dataset (movies dataset):
- budget: The budget in which the movie was made.
- genre: The genre of the movie, e.g., Action, Comedy, Thriller, etc.
- homepage: A link to the homepage of the movie.
- id: The movie_id as in the first dataset.
- keywords: Keywords or tags related to the movie.
- original_language: The language in which the movie was made.
- original_title: The title of the movie before translation or adaptation.
- overview: A brief description of the movie.
- popularity: A numeric quantity specifying the movie’s popularity.
- production_companies: The production house of the movie.
- production_countries: The country in which it was produced.
- release_date: The date on which it was released.
- revenue: The worldwide revenue generated by the movie.
- runtime: The running time of the movie in minutes.
- status: “Released” or “Rumored”.
- tagline: The movie’s tagline.
- title: The title of the movie.
- vote_average: Average rating of the movie.
- vote_count: The number of votes the movie received.
This description provides a foundational understanding of how the recommendation system is structured and the types of data it utilizes to make predictions.
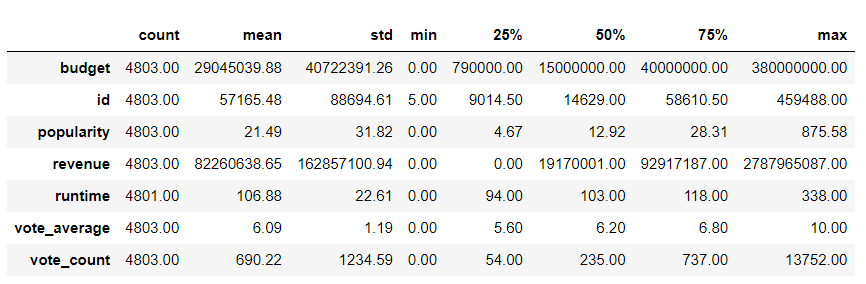
Examining summary statistics is beneficial because it provides a quick overview of key characteristics of the numerical data. The code below generates summary statistics for the numerical variables within the
dataset and transposes the result to display it in a more readable format.
These statistics include measures like mean (average), standard deviation (a measure of data spread), minimum, maximum, and quartiles. They help data analysts and scientists understand the central tendency, variability, and distribution of the data. This is crucial for making informed decisions about data preprocessing, feature selection, and modeling. Summary statistics also aid in identifying potential outliers or unusual patterns in the data.

Here’s what the .describe() method does:
- Count: Shows the number of non-missing entries in each column.
- Mean: Provides the average value for each column.
- Std (Standard Deviation): Indicates the amount of variation or dispersion in each column.
- Min: The smallest value in each column.
- 25% (First Quartile): The value below which 25% of the data falls.
- 50% (Median): The middle value of the dataset.
- 75% (Third Quartile): The value below which 75% of the data falls.
- Max: The largest value in each column.
Overview of dataset characteristics with the .describe() method:
Having showcased the value of summary statistics via the .describe() method for understanding the core trends and variations in our data, we now broaden our view by delving into metadata. This approach will further deepen our insight into the data’s framework and attributes (column names or features), enriching our comprehension of the dataset’s intricacies.
Metadata

Metadata provides an overview of the dataset itself; it’s the data about the data. It provides a high-level summary about the characteristics of the dataset. It includes details such as the column names, the types of data contained in each column (numerical, textual, etc.), and the count of non-null entries in each column, among other aspects. The code snippet below is typically utilized to retrieve the metadata of a dataset.

Upon executing the code, a succinct summary is displayed, offering valuable insights into the various data types present and the memory usage in the dataset. This information is crucial for deeper analytical efforts. The output generated might begin as follows:

- Range Index: The dataset is indexed from 0 to 4802, providing a unique identifier for each row.
- Columns: There are a total of 20 columns, each representing a different feature or attribute related to movies.
- Column Details: Each column’s non-null count varies, with some columns having fewer non-null counts than others.
- Data Types: The dataset primarily consists of integer (int64) and floating-point (float64) values, with columns having object (string) data types.
- Memory Usage: The dataset consumes approximately 751 KB of memory.
This summary provides a quick overview of the dataset’s structure, size, and the types of data. It contains, which is useful for preliminary data analysis and serves as a foundation for subsequent model building.
One of the primary responsibilities of a data scientist or machine learning practitioner involves communicating findings to stakeholders. Therefore, an integral part of their role is to create visualizations that convey insights derived from data analysis. This ensures that the information is accessible and understandable.
To illustrate this point, let’s take a look into a couple of visualizations.
Distribution of Budgets Visualization: The histogram below shows the range and frequency of movie budgets within the dataset. Most movies have budgets under 100 million dollars, with a peak in frequency for movies with lower budgets. This indicates that while high-budget films exist, they are less common than films produced with modest financial resources.

Top Genres Visualization: The bar chart below displays the most common genres among the movies in the dataset. Drama, Comedy, and Thriller genres are among the top, suggesting that these genres are particularly popular for movie production. This visualization highlights the genres that filmmakers most frequently explore, likely reflecting audience preferences and market trends.

Visualizations make the information easier to understand and assist in decision-making. Building on these insights, we now turn our attention to the process of feature engineering, where we refine and transform data to further enhance model performance.
Feature Engineering

In the realm of data analytics for movie recommendations, a crucial preliminary step before training machine learning models is feature engineering. This process entails transforming the raw dataset into a format that’s more amenable to analysis by machine learning algorithms, enhancing their capability to forecast outcomes such as user preferences for movies.
For the movie recommendation dataset, feature engineering typically includes several essential actions. These are the extraction of significant attributes from movie metadata, meticulous handling of any missing values to preserve data quality, encoding of categorical variables like genres and director names, and standardizing or scaling of numerical variables such as budget and runtime. As mentioned earlier in the introduction section, the terms “attributes”, “column names” and “features” are often used interchangeably in the context of machine learning.
Furthermore, it may involve creating new features through methods like combining related attributes or breaking down existing ones into more detailed components, as well as pinpointing the most impactful features that drive the accuracy of the model’s predictions. By rigorously refining and curating the dataset with these feature engineering techniques, we can substantially enhance the model’s insight into user preferences and the factors influencing movie recommendations, leading to more precise and actionable predictions.
Let’s delve into some key elements of feature engineering for predicting movie recommendations:
- Data Extraction and Refinement: Sifting through movie data to isolate meaningful attributes and carefully managing any incomplete records to ensure the robustness of the dataset.
- Feature Transformation: Transforming categorical data into a numerical format that’s interpretable by machine learning models and adjusting numerical variables to a standard scale to prevent any one feature from disproportionately influencing the prediction due to its magnitude.
- Feature Creation and Selection: Generating new features by aggregating similar data points or decomposing complex attributes into simpler ones, and choosing the most pertinent features that bolster the predictive precision of the model.
- Optimization for Predictive Accuracy: The overarching goal is to fine-tune the dataset. Augmenting the model’s proficiency in recognizing patterns and determinants that affect movie recommendations, thereby refining the reliability and utility of its predictions.
After exploring feature engineering, the next pivotal step is Model Training. In this phase, we use the processed data, now enriched with engineered features, to instruct the machine learning model on distinguishing between the nuances of user preferences for movies. With this foundational work in place, we are ready to advance to the topic of training the model.
Training the Model

In this phase, the machine “learns” to distinguish between user preferences and behaviors that indicate a likelihood of enjoying a particular movie and those that do not. The dataset is segmented into training and testing groups. A critical step to ensure the model is honed on a specific subset of data while its performance is evaluated on another set of unseen data. This division is fundamental for an accurate assessment of how well the model can predict movie recommendations.
As emphasized earlier, this article does not aim to serve as an exhaustive tutorial on machine learning. Rather, its purpose is to showcase how machine learning techniques can be applied to analyze and predict movie preferences.
These code snippets lay the foundation for training a movie recommendation model. The code offers a glimpse into programming needed to build and train a model for movie recommendation systems.






Moving forward, we’ll explore the Model Interpretation phase, focusing on how our model predicts movie recommendations. Here, the emphasis isn’t on the complexity of the model but on its accuracy and reliability. It’s crucial to understand that the model does more than just churn out predictions. It provides insights into user preferences and viewing patterns, translating raw data into actionable intelligence. In simpler terms, the goal is to assess if the model is effective but also understand the mechanics behind its predictions & the reasons we can trust its guidance. This comprehension is key to confidently relying on the model for strategic decision-making processes in content recommendation and personalization.
Model Interpretation

In the context of predicting movie entertainment recommendations using machine learning, model interpretation delves into understanding how algorithms analyze user interaction data such as viewing history, ratings, and genre preferences to differentiate between movies a user is likely to enjoy and those they might not. This phase is crucial for ensuring that the insights provided by the model are accurate, meaningful, explainable, and actionable. It fosters a level of transparency that builds trust with stakeholders. It is a critical component of ethical machine learning practices. Explainability can still be helpful, even when regulators or customers aren’t asking for it [5, 6]. Explainability is not merely a regulatory checkbox but a critical component of ethical machine learning practices. It contributes to more trustworthy and reliable systems.
Interpreting these “black box” models can be challenging, as it requires simplifying complex algorithms without losing essential details. It extends beyond mere prediction accuracy. It involves unraveling the factors that influence user preferences and identifying patterns that might not be immediately apparent. For example, understanding how a user’s past interactions with similar genres or directors impact their likelihood of enjoying a new movie can offer valuable insights for tailoring content recommendations and optimizing the viewing experience.
Evaluating model performance involves analyzing key metrics to assess the effectiveness of the recommendation system. Model evaluation plays a pivotal role in this process, offering a quantitative measure of the model’s predictive capabilities:
- Mean Absolute Error (MAE): Measures the average magnitude of the errors in a set of predictions. It provides an indication of how close the recommendations are to the actual ratings.
- Root Mean Squared Error (RMSE): Measures the square root of the average of the squared differences between predicted and actual ratings, giving a higher weight to larger errors.
- Coverage: Measures the percentage of the item catalog that the recommendation system is able to recommend, indicating the system’s ability to recommend a wide variety of items.
- Diversity: Measures how different the recommended items are from each other. It ensures that the system provides a broad range of recommendations and avoids filter bubbles.
- Novelty: Measures the degree of newness or surprise of the recommended items to the user, enhancing user discovery and satisfaction.
- Serendipity: Measures the pleasant surprise of recommendations. It captures the delight factor of recommendations by assessing how unexpected yet liked the recommended items are.
These metrics, alongside advanced interpretability and explainability techniques such as feature importance rankings and partial dependence plots, aid in demystifying the model’s decision-making process. They allow content providers to refine recommendation strategies, personalize user experiences, and optimize content discovery effectively.
In conclusion, the integration of model interpretation into the analytics process for movie recommendations is essential. It transforms predictive modeling from a mere computational task into a strategic asset that aids decision-making. By employing a holistic approach that combines actionable insights with rigorous performance metrics, content providers can align their strategies with data-driven intelligence. This integration can help improve viewer engagement, optimizing content curation, and driving significant value in the competitive entertainment industry.
Key Takeaways
This article explores the transformative role of machine learning in the entertainment industry. Particularly in customizing movie recommendations on platforms like Netflix. By delving into the mechanisms behind personalized content curation, it highlights how machine learning algorithms analyze user data, such as viewing habits and ratings, to tailor movie suggestions. The discussion extends to feature engineering, model training, and interpretation, providing a glimpse into technical processes that enhance recommendation accuracy. Insights from industry leaders and practical code examples illustrate the practical application of these techniques. Ultimately, the article underscores the significance of machine learning in creating personalized viewing experiences. It encourages readers to further explore the intersection of data science in entertainment.
Next Steps
- Technology-related roles are the fastest growing jobs in percentage terms, including Big Data Specialists, AI and Machine Learning Specialists and Software Developers [7]. This insight from the World Economic Forum’s 2025 report highlights the growing demand in these fields. To position yourself advantageously in the job market, consider WeCloudData’s bootcamps. If you are interested in learning and becoming a machine learning engineer, do check Weclouddata’s AI and Machine Learning bootcamp. Earn your Machine learning Certificate today! With real client projects, one-on-one mentorship, and hands-on experience in our immersive programs, it’s an opportunity to develop expertise in AI and machine learning. Aligning your skills with the current and future needs of the job market. Set yourself up for success in a dynamic and rewarding career; take action now!
Read More
https://weclouddata.com/blog/
References
[1] Netflix Tech Blog. (n.d.). Netflix Recommendations: Beyond the 5 Stars (Part 1). Netflix Technology Blog. Retrieved from https://netflixtechblog.com/netflix-recommendations-beyond-the-5-stars-part-1-55838468f429.
[2] Netflix Tech Blog. (n.d.). Netflix Recommendations: Beyond the 5 Stars (Part 2). Netflix Technology Blog. Retrieved from https://netflixtechblog.com/netflix-recommendations-beyond-the-5-stars-part-2-d9b96aa399f5.
[3] McKinsey & Company (November 15, 2023). How generative AI can drive the personalization of products and services. McKinsey & Company. Retrieved from https://www.mckinsey.com/featured-insights/lifting-europes-ambition/videos-and-podcasts/how-generative-ai-can-drive-the-personalization-of-products-and-services.
[4] Rezaei, M. R. Amazon Product Recommender System. Department of Biomedical Engineering, University of Toronto (2021).
[5] Molnar, C. (2020). Interpretable Machine Learning. Retrieved from https://christophm.github.io/interpretable-ml-book/.
[6] Doshi-Velez, F., & Kim, B. (2017). Towards A Rigorous Science of Interpretable Machine Learning. arXiv:1702.08608. Retrieved from https://arxiv.org/abs/1702.08608.
[7] World Economic Forum (2025). “Future of Jobs Report 2025.” Retrieved from https://reports.weforum.org/docs/WEF_Future_of_Jobs_Report_2025.pdf.
