Data Scientist
How to Become a Data Scientist in 202X Hi, my name is Shaohua. I’m the CEO and co-founder at WeCloudData. Many of you are reading this article because you’re either interested in learning more about data science or have made a decision to switch career to the data science field. Read on, this career guide […]
Data Science Bootcamp
Data Science Bootcamp
Data Science Bootcamp
Data Science Bootcamp
Consulting Case Study: E-commerce Customer Segmentation

Background Our client is a company manufacturing consumer electronic products like mobile devices, printers, computer monitors and so on, who is leading the electronic goods merchant wholesalers industry for many years. Their advanced data analytics team connected to WeCloudData for the machine learning solution on predicting their top merchandize sales and marketing strategies on their […]
Consulting Case Study: Topic Modelling on Technician Notes

Client Info Our client is one of Canada’s largest construction vehicle suppliers. They employ thousands of skilled technicians across multiple provinces to support their clients and are known for their excellent customer service and quality of work. The technicians handle repair and maintenance services for their client’s purchased vehicles. For each job that a technician […]
Consulting Case Study: E-commerce Customer Segmentation
Background Our client is a company manufacturing consumer electronic products like mobile devices, printers, computer monitors and so on, who is leading the electronic goods merchant wholesalers industry for many years. Their advanced data analytics team connected to WeCloudData for the machine learning solution on predicting their top merchandize sales and marketing strategies on their […]
Consulting Case Study: Lookalike Models for Audience Expansion

Background Our client is one of the largest news publishers in North America. With their print and digital formats reach millions of readers every week, they lead the national discussion by engaging audiences through its prestigious coverage of news, politics, business, investing and lifestyle topics, across multiple platforms. The WeCloudData team worked with the client’s […]
Consulting Case Study: Integrated AI Content Search

Executive Summary WeCloudData is one of the fastest growing Data & AI training companies in the world. Since 2016, WeCloudData has trained and helped thousands of students and clients level up their data skills and mature their data organizations. As organizations continue to undergo digital transformations all over the world, enterprises are experiencing pains that […]
Consulting Case Study: Recommender Systems
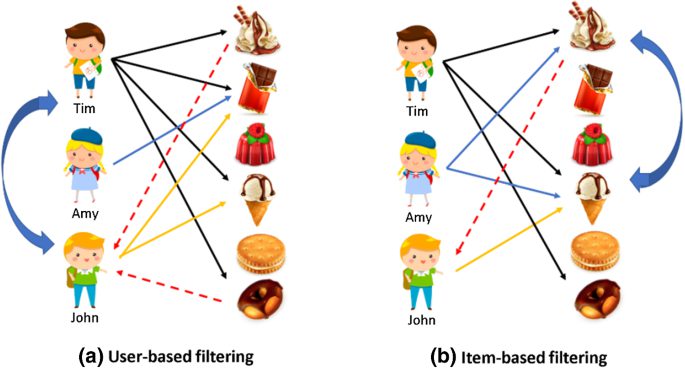
Client Info Our client is one of Canada’s most well-established and decorated news outlets. They have been the recipient of numerous journalism awards and have a reach of millions of readers for their print and digital content across all news categories. In the early to mid 2010s, our client began to shift its focus towards […]
Consulting Case Study: Job Market Analysis

Executive Summary WeCloudData is one of the fastest growing Data & AI training companies in the world. Since 2016, WeCloudData has trained and helped thousands of students and clients level up their data skills and mature their data organizations. Understanding the job market is a central business need for many organizations and for all HR […]
Faculty Story: From Management Consulting to Data Science Practice Lead

Breaking into the Consulting Industry My interest in management consulting began in the latter half of my undergraduate life sciences degree. It was a career path that promised a few intriguing aspects all-in-one – a collaborative environment, challenging projects which were at the heart of a business, and a fulfilling career as a result of […]
SQL Fundamentals

Views on Data Science Education from a Project Manager

This blog post was written by BeamData’s Project Manager and WeCloudData’s Assistant Instructor, Shan Gao. My Philosophy of Teaching I come from an Engineering background. During the years of research and industrial project experiences, I benefited a lot from data analytics which could efficiently tackle daily business challenges. What we teach in WeCloudData goes past […]
Data Science Tips & Teaching Methodology from an Instructor

This blog post was written by WeCloudData’s Data Science Instructor, Vinny Nguyen. Hi! I’m Vinny and I’m a data science instructor here at WeCloudData. I’d like to tell you a little about my journey through data science, some tips I’ve learned along the way, and how that influences our teaching methodology here at WeCloudData. Transitioning […]
4 Reasons to Choose WeCloudData

This blog post was written by WeCloudData’s Data Science Instructor, Tianshu Luan. “To get the best result, students and faculty should work together to find the correct method of learning.” About Me I am a career switcher to the data scientist role. I graduated with a Bachelor of Education degree and was teaching Mathematics and […]
How WeCloudData Supports Students in their Learning Journey

This blog post was written by WeCloudData’s Assistant Instructor and Program Manager, Sonia Chhay. Hi, my name is Sonia and I am a Data Science (DS) Assistant Instructor (for the full-time program) and Program Manager at WeCloudData. During my undergrad at UofT, I majored in Statistics & Cognitive Science and was a teaching assistant (TA) […]
Big Data for Data Science

Machine Learning
