Retrieval-augmented generation (RAG) is an AI cutting-edge approach that combines the power of traditional retrieval-based techniques with the capabilities of a generative large language model (LLM) to enhance the accuracy and relevance of AI-generated content. Instead of depending entirely on pre-trained knowledge, RAG incorporates external knowledge sources, such as documents or databases, to enhance the accuracy and contextual relevance of AI-generated responses.
This blog introduces Retrieval Augmented Generation RAG, its features, applications, and why it’s a game changer for knowledge-intensive NLP. Let’s get started with WeCloudData!
How does Retrieval-Augmented Generation work?
To improve generative AI outputs, RAGs possess some key features including;
Data Retrieval
Data retrieval ensures that the AI has access to up-to-date and accurate data, which is especially important for domains like medicine, law, or customer support. It follows the following sub-process;
Query Formulation: The user’s input (question or prompt) gets converted to a search query. This usually utilizes techniques such as keyword extraction or semantic analysis to determine the user’s intent.
External Data Sources: RAG systems can access various external data sources, such as:
- Vector databases store data in numerical representations (vectors), allowing for more efficient similarity searches.
- Knowledge graphs show information as interconnected entities and relationships.
- Traditional databases include relational or NoSQL databases.
- Websites and document repositories.
Retrieval Mechanism: Search queries obtain relevant information from selected data sources.
The mechanism for retrieving relevant information from the selected data sources is based on the search query. Typical retrieval techniques include:
- Keyword-based search, which matches keywords in the query to terms in the data.
- Semantic search, which understands the meaning of the query and retrieves data with similar semantic content.
- Hybrid search, which combines keyword and semantic search for increased accuracy.
- Ranking and filtering techniques are used to rank the retrieved information according to relevance to the query.
Data Pre-Processing
Once data is retrieved, the relevant information undergoes pre-processing. Preprocessing includes tokenization, stemming, and removal of stop words, Chunking/Segmentation, and embedding generation.
Grounded Generation
Context Augmentation: The initial user query is coupled with the pre-processed information that was retrieved, in the form of text fragments or embeddings. Then the LLM prompt is updated with the retrieved context.
Prompt Engineering: Through thoughtfully well-crafted prompts guides the LLM on how to use the retrieved information.
LLM Inference: The augmented prompt is given to the pre-trained LLM, enhancing the LLM’s context, and providing it with a more comprehensive understanding of the topic. LLM generates a response based on its existing knowledge and the provided context. Large Language Models generates more precise, informative, and engaging responses based on the augmented context present in prompt.
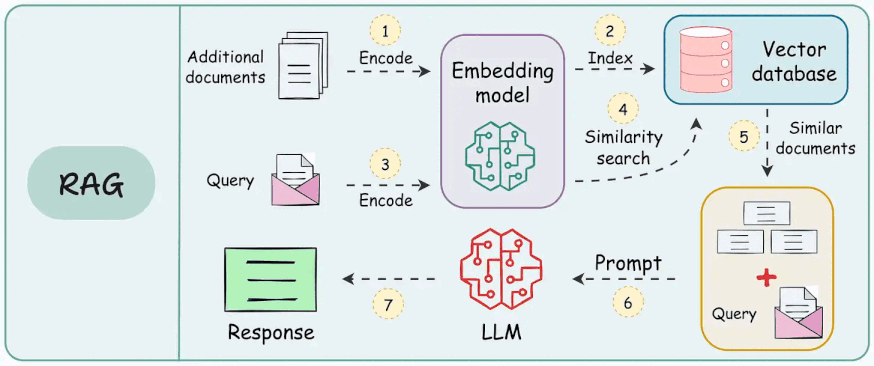
Caption: RAG System Architecture
Applications of RAG
Multiple domains widely use RAG, including these prominent sectors:
Customer Support Systems: RAG enables chatbots to quickly retrieve data from FAQs or product manuals to accurately and promptly answer client questions.
Medical and Legal Query Resolution: RAG can get information from legal documents or medical journals to help professionals make well-informed decisions in domains where precision is important.
Knowledge-Intensive NLP operations: RAG is perfect for activities that require access to outside knowledge, such as content creation, summarization, and question-answering.
Why RAG Matters
A major problem with generative AI systems like ChatGPT is illusions, which occurs when a model produces false or misleading information. RAG plays a major role in solving this issue by providing access to updated information and factual grounding, allowing data fetching from vector databases and knowledge graphs. Key benefits of RAG are;
- Improved AI-generated responses in terms of reliability and precision.
- Improved transparency by linking generated outputs to retrievable sources.
- The capability of dynamically updating AI knowledge without requiring complete model retraining.
Next Steps for Hands-on Exploration
Here are some resources and tools to help you get started if you want to experiment with RAG.
LangChain: A framework that supports RAG by enabling seamless integration of retrieval and generation components.
Vector Databases: Tools like Pinecone and Milvus are excellent for storing and retrieving vectorized data, which is essential for RAG systems.
Research Papers: Dive deeper into the technical aspects by exploring the original RAG paper, which provides a comprehensive overview of the architecture and its applications.
At WeCloudData, we specialize in cutting-edge AI and data solutions, helping professionals and businesses using AI technologies for real-world applications. Whether you’re looking to upskill, build AI-powered applications, or integrate AI into your workflow, our hands-on training programs and expert-led courses will guide you every step of the way.
Why Choose WeCloudData for Your Data Journey?
Because WeCloudData Offers:
- Self-paced Courses to learn at your convenience.
- Comprehensive course in Python, SQL, statistics, AI, and Machine Learning.
- Data & AI Training Programs for Corporate with expert instructors.
- Mentorship from industry professionals to guide your learning journey.
- Portfolio support to build projects that stand out.
- Career services to help you land your dream job.
Ready to kickstart your career? Visit our website today and take the first step toward an exciting future in data and AI!
