The ability to extract information from vast amounts of text has made question-answering (QA) systems essential in the modern era of AI-driven apps. RAG-based question-answering systems use large language models to generate human-like responses to user queries. Whether it’s for research, customer support, or general knowledge retrieval, a Retrieval-Augmented Generation system enhances traditional QA models and building a RAG system for your own venture could be fruitful.
In this blog, we’ll walk through the process of building a RAG-based QA system using Python, the HuggingFace transformers library, and large language models like the “gemini-1.5-pro”. Let’s build a RAG-based QA system with WeCloudData.
Why Retrieval Augmented Generation (RAG)
Traditional AI QA models depend highly on pre-trained knowledge, which means models may find it challenging to answer questions based on new or domain-specific documents. A RAG-based system overcomes this limitation by retrieving relevant document chunks and using them as context to generate answers based on the user query and prompt. To learn more about RAG, follow this link where there is a detailed discussion on what is RAG!
Imagine you’re working with research papers or legal documents. Instead of training a massive AI model from scratch, a RAG system allows you to:
- Quickly search for relevant information
- Use AI to explain or summarize complex information
- Ensure up-to-date responses without retraining the model
- Language flexibility
- Reasoning capabilities
Let’s dive into the step-by-step process of building this system.
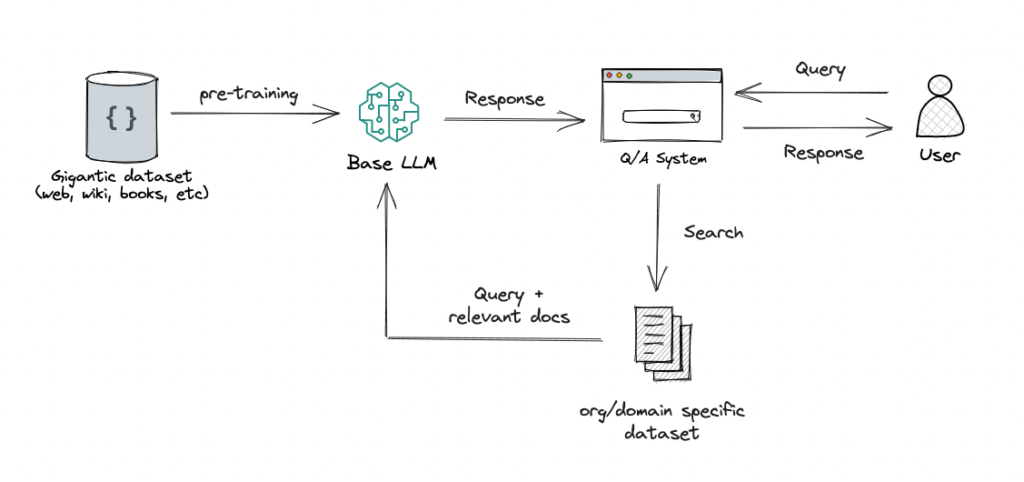
Understanding Our Approach
Our RAG-based Question Answering system retrieves relevant document segments before generating answers to improve AI-generated responses. Instead of asking an AI model directly, we use the FAISS library to first find the most relevant parts in our document, by converting text into embeddings and storing them in a vector database. When a user asks a question, we retrieve top-k relevant document sections and pass them to Google’s Gemini 1.5 Pro, our Large Language Model. After processing the user’s query and the retrieved context, Gemini (LLM) produces an intelligent and contextually aware response to the user’s query.
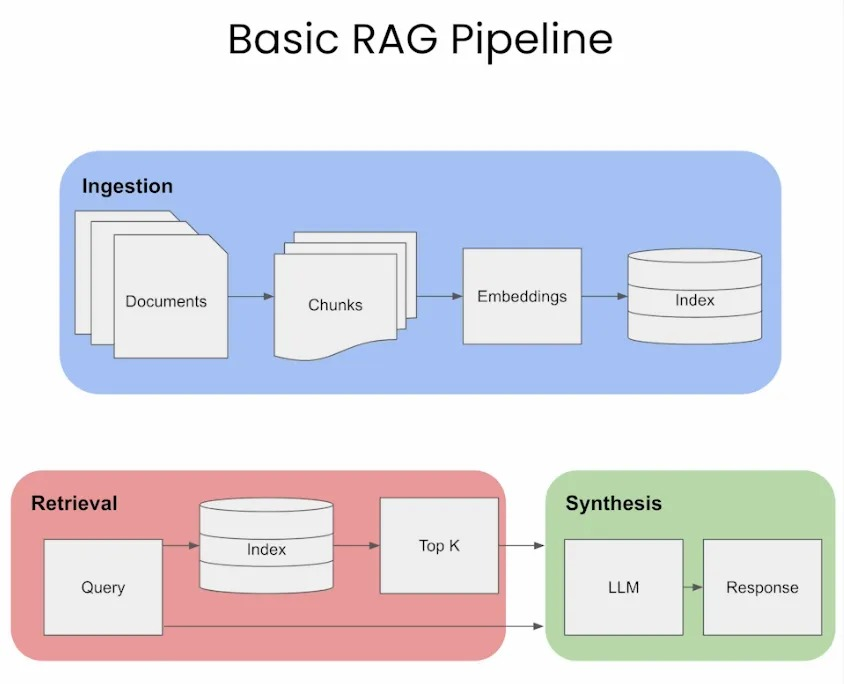
Step 1: Importing the Required Libraries
We need to install and import these necessary libraries to build an RAG-based QA system.

What Do These Libraries Do?
- PDFplumber: Extracts text from PDFs.
- Faiss: Stores and retrieves document embeddings for fast searches.
- Numpy: Helps with numerical computations.
- Google. generativeai: Google’s Generative AI is used to generate answers.
- Sentence-transformers: Converts text into embeddings for semantic search.
Step 2: Configuring Google’s Generative AI API
We’ll use Google’s Generative AI API to provide responses. To authenticate requests, an API key is required.
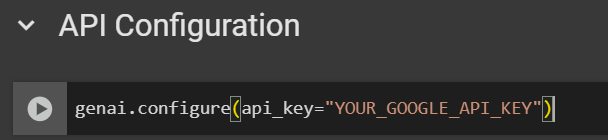
Replace “YOUR_GOOGLE_API_KEY” with your actual API key from Google.
Step 3: Reading & Extracting Text from PDFs
To answer questions based on a document, we first need to read and extract its content. Our document is in PDF format, so we use the PDFplumber library to read and extract text from the document.
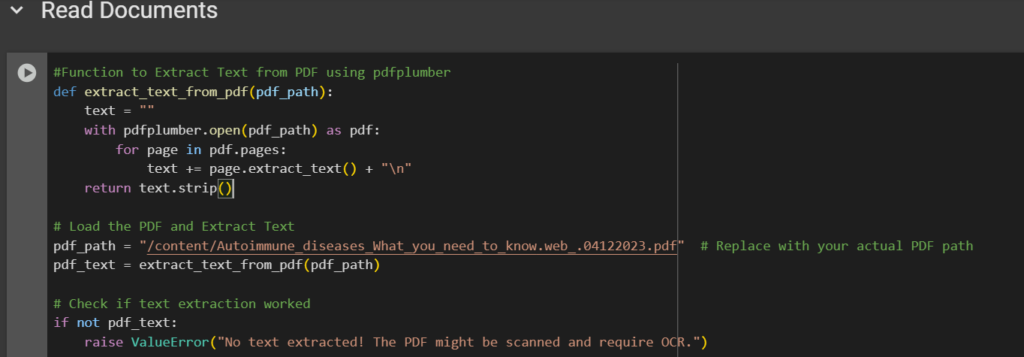
How Does This Work?
- Opens the PDF file
- Loops through each page and extracts text content
- Combines all the extracted text into a single string
- Added a check to ensure text extraction works.
- This step gives us the raw data to build our QA system.
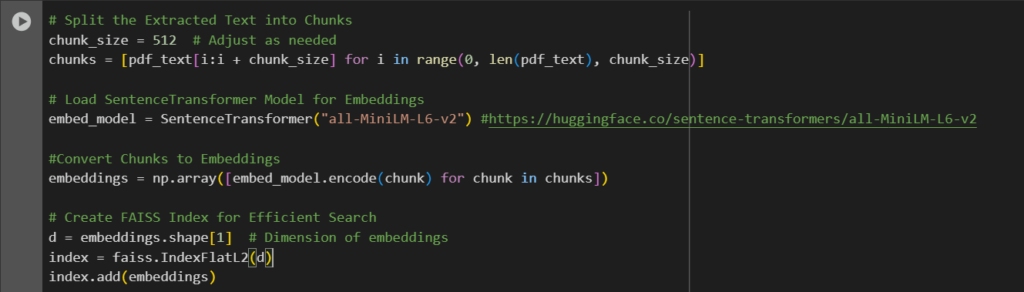
Step 4: Converting Text into Embeddings
After extracting the raw text, we need to convert it into a format our model supports. We use sentence transformers to transform text into embeddings from Hugging Face. Embeddings are numerical representations of data that capture relationships between inputs, allowing machine learning models to understand and process information more effectively.
After generating embeddings, we created an FAISS index to store embeddings for efficient search.
Why Are Embeddings Important?
Embedding captures the meaning of sentences in the textual data, thus making our RAG-based QA system more accurate and efficient.
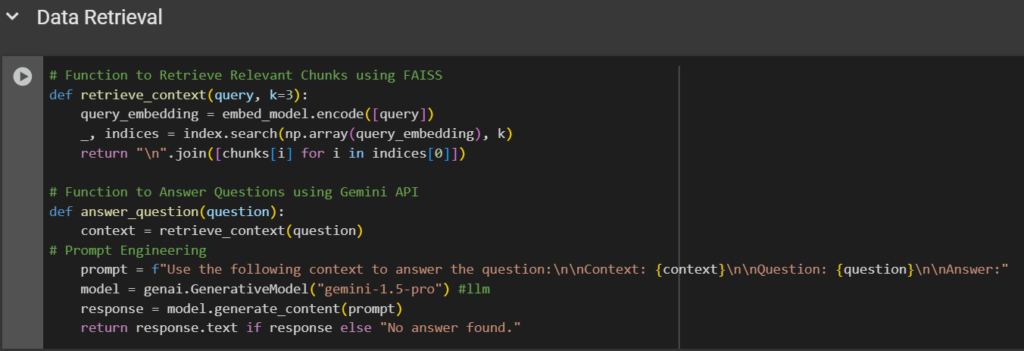
Step 5: Storing & Retrieving Data Using FAISS
After generating embeddings for the document, we need to store them for the quick retrieval of the most relevant information when a user asks a question. That’s where FAISS (Facebook AI Similarity Search) comes in. FAISS is a powerful library used to search through high-dimensional vectors.
FAISS is used to create a searchable “memory” of the document from embeddings, where each section is converted into a vector that can be compared to the user queries. When a user asks a question, the query is encoded for embedding in the same way, and FAISS is used to find the top-k most similar chunks; in this case, the value of K is 3 means the top three related chunks. A single context block is then created by combining these chunks. LLM Gemini 1.5 Pro receives this retrieved context and the user’s query via given prompt: “Use the following context to answer the question…” The given prompt guides the LLM to answer the question using only the retrieved context, leading to more accurate and context-aware answers.
By combining semantic search via FAISS and natural language generation using Gemini, this step allows the RAG-based QA system to provide meaningful responses based on the actual content of the document.
Step 6: Generating Answers – Asking Real Questions, Getting Smart Answers
Now that all the necessary preparations have been completed, like document processing, embeddings stored, FAISS ready, and Gemini integrated, it’s time to ask a question and observe the RAG-based QA system in operation.
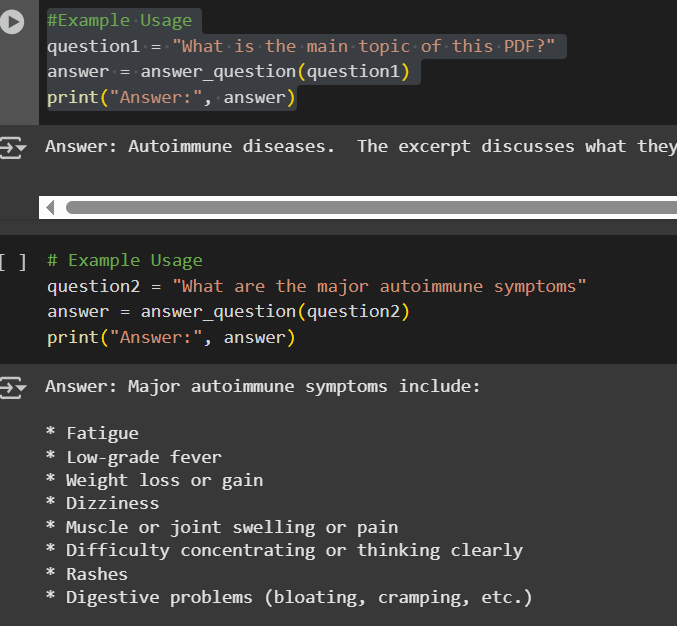
These lines of code trigger the entire pipeline behind the scenes. Query is transformed into an embedding, relevant sections of the document are found using FAISS, and a prompt is created that combines the user query with the context. Gemini 1.5 Pro receives this prompt and uses the information in the document to generate an understandable and well-informed response.
Smarter Answers with Simpler Tools
In this blog, we used Google’s Gemini 1.5 Pro, easily accessible Python packages, and a reliable sentence embedding model to create a lightweight yet effective RAG-based Q&A system. We’ve demonstrated how to create an intelligent assistant that reads, understand, and responde depending on the content of documents rather than educated guesses by combining semantic search (via FAISS) with context-aware language generation.
This is just a simple example of how to build a RAG system focused on question-answering. You can further customize and extend this system to suit your specific needs, such as using different language models, fine-tuning the models on your domain-specific data, working with multiple PDFs, scanned documents (with OCR), or adding any types of documents as per your needs.
Explore Data Science with WeCloudData
At WeCloudData, we specialize in cutting-edge AI and data solutions, helping professionals and businesses use AI technologies for real-world applications. Whether you’re looking to upskill, build AI-powered applications, or integrate AI into your workflow, our hands-on training programs and expert-led courses will guide you every step of the way.
Why Choose WeCloudData for Your Data Journey?
Because WeCloudData Offers:
- Self-paced Courses to learn at your convenience.
- Comprehensive course in Python, SQL, statistics, AI, and Machine Learning.
- Data & AI Training Programs for Corporate with expert instructors.
- Mentorship from industry professionals to guide your learning journey.
- Portfolio support to build projects that stand out.
- Career services to help you land your dream job.
Ready to kickstart your career? Visit our website today and take the first step toward an exciting future in data and AI!
