
[Webinar] Data Science Learning Path
Data Science Skills
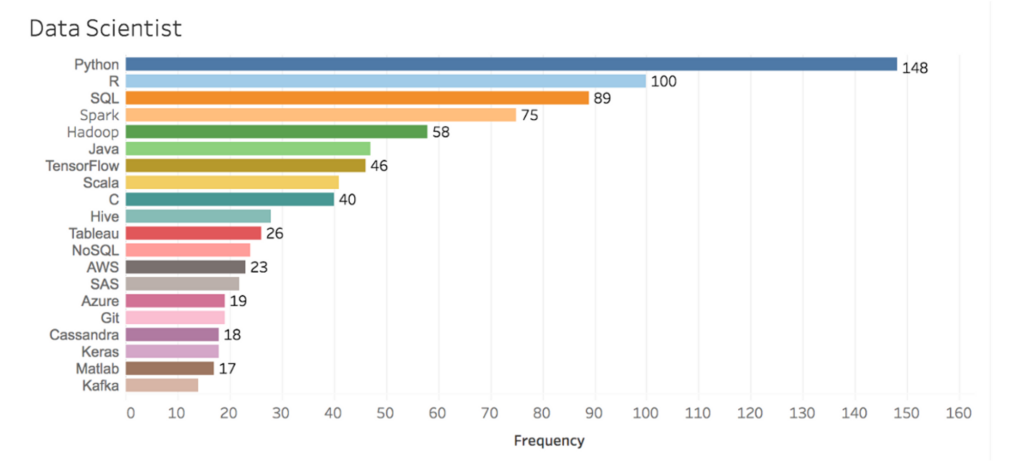
Data Scientists need to know many hard skills such as Python, SQL, R, Spark, Tableau, NoSQL, etc. It can be overwhelming to beginners. But Rome is not built in one day and you certainly don’t need all the skills in order to get into the industry. So focusing on learning the most essential skills is critical.
Data Science Learning Path (general)
Whether you’re self-learning data science or get trained through bootcamp programs, a well-structured curriculum is a key that leads to successful outcome. Below is a general data science learning path proposed by WeCloudData’s data science faculty team and this learning path has been tried by many students and proven successful.
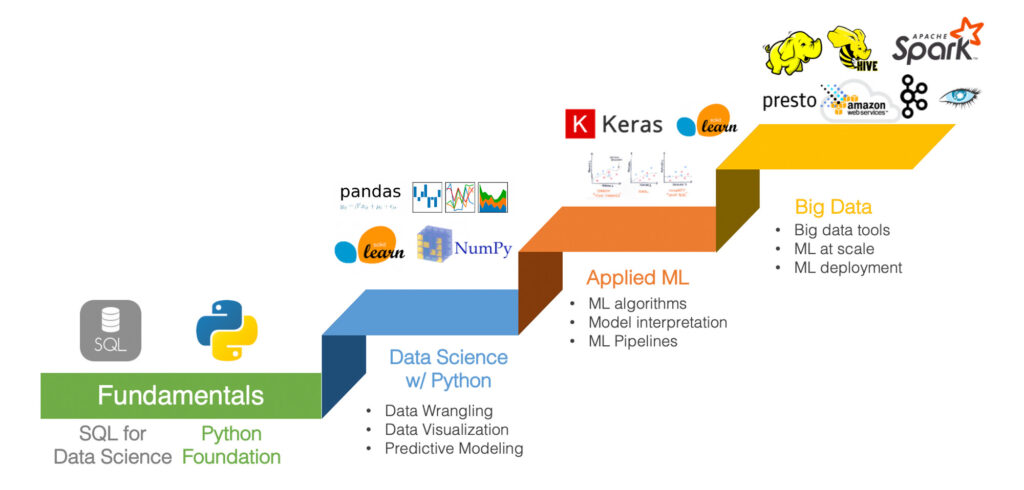
In general, someone who wants to get into data science needs to follow a few steps to learn the hard skills:
- SQL & Databases
- Python Programming (or R)
- Data Wrangling using DataFrames (Pandas, R)
- Statistics and Machine Learning
- Big Data and Cloud
The Importance of Fundamentals
When it comes to landing a data scientist job, nothing is more important than two fundamental skills: SQL and Python. They are the tools that allow a data scientist to extract, manipulate, and analyze data. Almost all data scientist interviews will arrange coding challenges and we’ve seen many job seekers with advanced skills failing the coding challenges and therefore lost good opportunities.
A data scientist with a strong foundation in programming can usually go farther down in the technical data science career path. There will be a higher chance moving into a machine learning engineer or AI engineer role. It is one of the reasons why CS graduates are usually favoured by employers.
Our advice to beginners is that you should focus on building up your coding skills at the beginning of your learning curve. Don’t get intimidated by programming if you’re not from computer background. There’re many great online resources that can help you get started. WeCloudData also offers online SQL and Python programming courses that can help you kick start your data science learning journey.
Data Science Learning Path: SQL
If there’s only one tool a data science or analyst should know, it should probably be SQL! Data science projects all start from data definition and exploration. SQL allows one to pull data from databases, data lakes, and other storage systems.
Note that SQL usually is associated with relational databases (RDBMS) but in this career guide, we refer SQL to the ability to write queries to extract and manipulate data from various sources. Companies usually deal with massive amounts of data that don’t fit in one’s laptop and for security’s purpose data is most likely stored in a distributed system or database that require remote access.
That’s why you need to learn SQL.
SQL is not only used by data scientists and analysts. It is used by many different data roles including BI analyst, business analyst, as well as big data developers.
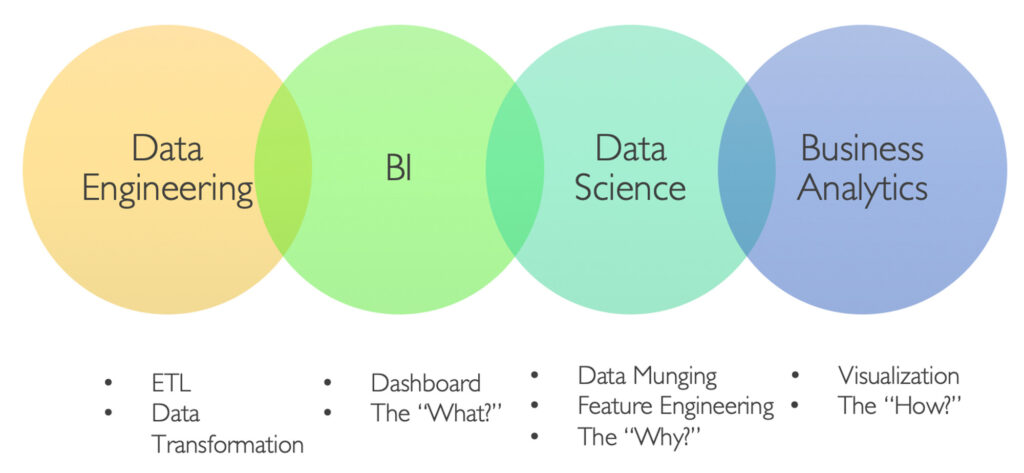
SQL is also widely adopted. It’s hard to find an organization that actually doesn’t use databases at all.

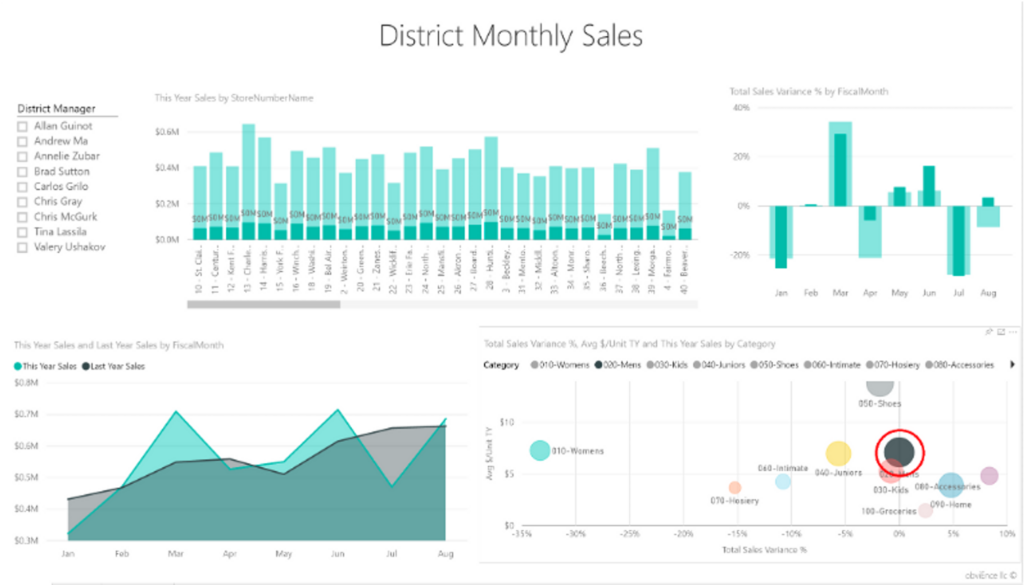
For BI specialists and data analysts who build visualization dashboards, SQL is also important because data that feeds the dashboards needs to be retrieved from databases through SQL queries. Uploading csv datasets directly to your dashboard tools such as PowerBI or Tableau is NOT how things work in practice.
Data Science Learning Path: Python
Python has become the most dominant programming language for data scientists. Though it is not the fastest computer programming language, but it’s flexibility, ease of use, and strong community support have made it the go-to language.
What can we use Python for?
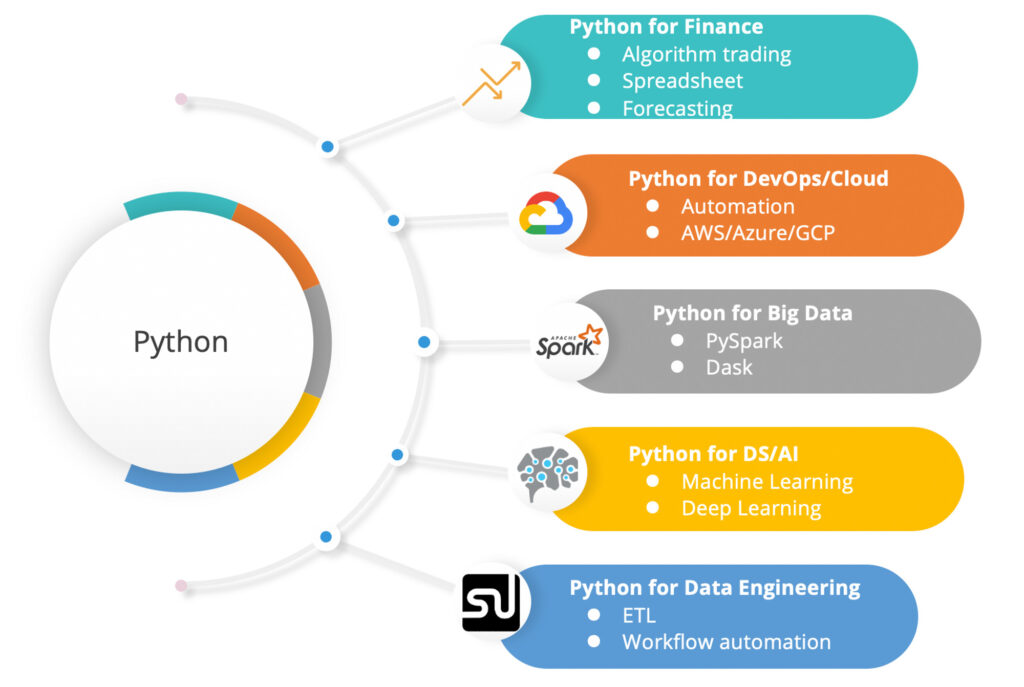
Python can be used for many different purposes. It’s sometimes considered as the glue language.
- As a programming language, python can be used for building web applications. For example, Djando, Flask, and FastAPI are backend frameworks for web development.
- One big reason why python is the favourite language for data science is it’s support for popular machine learning frameworks and packages such as Tensorflow, PyTorch, Scikit-learn, and Numpy/Scipy.
- Python is also very popular language for cloud computing and big data. For example, the most popular big data framework Apache Spark has strong support for Python and PySpark has become the most popular API. Cloud platforms such as AWS and Azure also provide python SDK that allows one to interact with cloud services via Python scripts.
However, Python’s flexibility can be a double-edged sword for beginners. When choosing a python programming course one needs to make sure that the goal is to learn python for data science instead of for web development. Below is a table that summarizes Python’s scientific ecosystem. You will be working frequently with some of the frameworks and libraries as you go down the learning path.

Data Science Learning Path: Data Wrangling & Analysis
Most Data Scientists spend 60%-70% of their time on data wrangling which includes data extraction, data querying, data manipulation, and data visualization. Usually a series of data manipulation tasks are carried out before a data scientist move on to the machine learning stage.

The emphasis on data wrangling over statistical modelling is especially true for junior data scientist and citizen data scientist. Experienced data science hiring manager will want to make sure that the candidates speak the data wrangling language fluently.
After you’ve learned python programming, make sure you spend significant effort on learning how to transform data into different shapes. Python’s Pandas and Numpy libraries are great ways to get started with data wrangling. In basic python programming, you learn basic data types such as List, Tuple, and Dictionary. Pandas DataFrame which is a structured data manipulation toolkit will empower data scientists and analysts to run much more complex queries against data and it’s also more efficient since Numpy is mostly written in C.
Here are some tips on how to learn data wrangling and basic analysis with Python:
- Data Wrangling
- Learn how to use Pandas to read data in different formats: JSON, text, CSV, database, etc.
- Learn how to filter and select the rows and columns you need for your base analysis
- Learn how to aggregate data to gain insight from the summary
- Learn how to transform data into different forms: pivot, melt, concatenate, merge, etc.
- Learn how to join and merge different datasets to include more dimensions into your analysis
- Data Visualization
- Data visualization can be applied in different stages of your analysis.
- During the data wrangling and exploration stage, visualization can help a data scientist understand the raw data, gain more intuition about the data, discover issues in data which all help the data scientist frame the data problems better
- During the statistical modelling and machine learning stage, visualization helps a data scientist understand ML features and therefore know how to engineer features and prepare features for machine learning.
- After the machine learning model training, data visualization also helps a data scientist understand the model performance and know where to improve.
- Look into packages such as Pandas, Plotly, Seaborn, etc. for exploratory data visualization tasks.
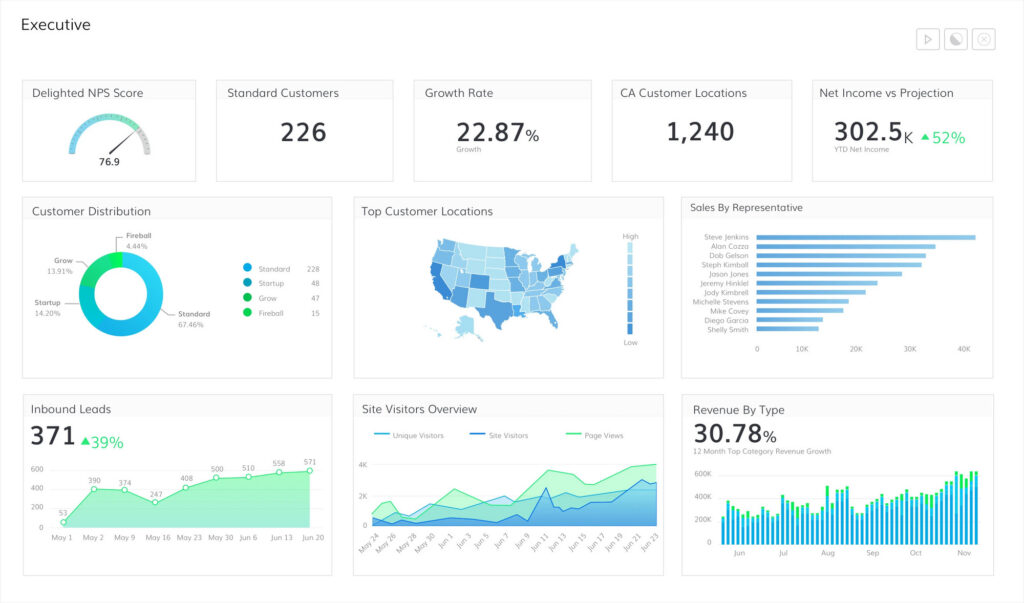
Sometime, data scientists also need to build visualization dashboard so they can present their work to the business teams in a small application or simply visualizing data for interpretation. Python also has some pretty cool Dashboard libraries such as Plotly Dash, Streamlit, and Panel. Look into that if that’s what you’re interested in.
Data Science Learning Path: Machine Learning
Machine Learning is a must-have skill for anyone who wants to become a data scientist. Whether you’re training your ML models using low-code/no-code tools or rolling up your sleeves and writing your own python code. Many things need to be covered when learning machine learning so here’s our two cents.
General Advice
If you’re a beginner trying to get started with machine learning, we’d suggest you start small. Try to learn how to build a machine learning model by going through some online tutorials is useful. Don’t start your ML journey by reading books as it could be quite ineffective. It’s important to able to see the outcome and understand how models can be used in real life. By understanding the big picture first and then go down the path to learn specific topics can keep you focused and motivated. Again, keep in mind that the goal here is to learn the right skills to get the foot in the door, rather than becoming a machine learning scientist through an academic environment. So here’re the steps we recommend:
- First Iteration
- Read a few ML use cases and understand how ML is applied in real-life
- Go through an online ML course and work on exercises to know the basics of using packages such as Scikit-Learn and Tensorflow
- Work with one or two kaggle datasets to complete an end to end ML project
- Read the solutions provided in the kaggle forum
- Second Iteration
- Review the learning plan and pick a few things to have deep dive
- Find tutorials about feature engineering and model tunings and apply what you learn to either improving the previous projects or new projects
- Brush up on your statistics and math knowledge based on what you know so far
- Start to read the
The elements of Statistical Learningbook
- 3rd Iteration
- Choose several popular ML algorithms and dive deeper into the theory
- Work on one or two capstone projects that are related to practical use cases
If you’re interested in building portfolio projects, consider WeCloudData’s portfolio course.
Importance of Understanding the ML pipeline

When you’re learning machine learning, it is very easy to lose sight of the big picture and focus only on the nitty-gritty of ML algorithms. Keep in mind that in practice, ML is part of a project and pipeline. Understanding the business problems, collecting the right data and labels, doing feature engineering the right way all contribute to the outcome of a solid machine learning model. And after the modeling building, interpreting the models to the business and getting the model deployed in production are also key steps that make sure the models generate real business value.
Data Science Learning Path: Big Data
30%-40% of the data scientist job postings will mention big data skills. Here’re some of the commonly asked big data skills:
Big Data tools to learn in 202x
- AWS or Azure or GCP
- AWS EMR (Hadoop, Hive, Presto)
- Apache Spark on Databricks
- Docker Containers
- NoSQL Databases (Elasticsearch, Cassandra, or MongoDB)
- Amazon SageMaker or equivalent
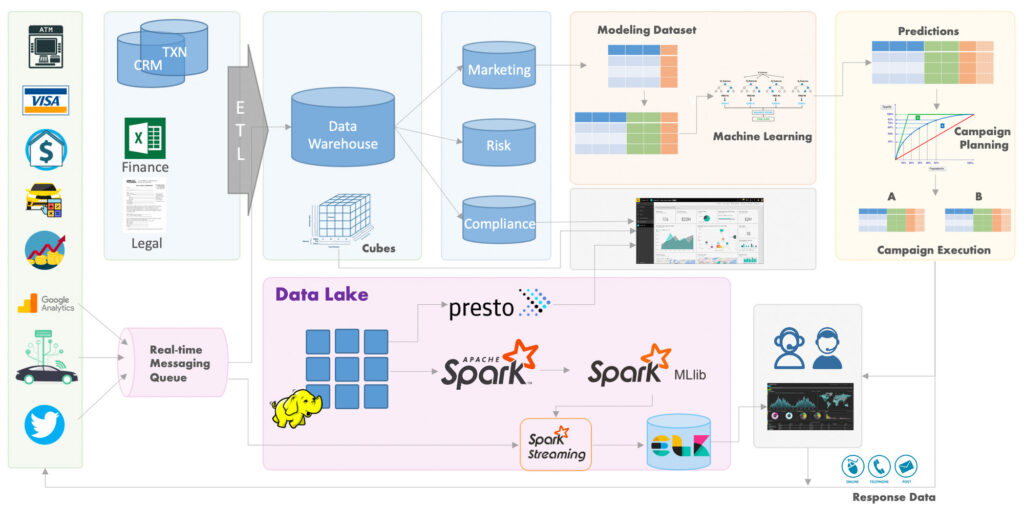
Big Data is NOT very easy to learn because the ecosystem contains many different tools and framework. It often intimidates data science learners because the sheer amount of information one needs to take in could be overwhelming. And it feels like a different world to the statistical analysis and machine learning realm.
WeCloudData’s suggestion to learners is that when it comes to big data, it is key to showcase you have knowledge about end to end data pipelines. When you work on big data projects, try to widen the scope and work on data collection, data ingestion, data analysis, machine learning, as well as model deployment. It will be great the project is architected over one of the cloud platforms such as AWS and definitely include Spark as the data munging tool.
Mistakes Beginners Frequently Make
Following a well-structured curriculum is key to the success. We’ve seen many students going down the rabbit holes of learning and end up being not able to complete end to end projects. Here we summarize some of the frequent mistakes we’ve seen:
Some of the mistakes we’ve seen many beginners make are as follows:
- Skipping SQL
- Don’t skip database queries. Unless you’re going after a ML Researcher role, SQL is one of the most important skills a DS needs to master.
- Learn Python the wrong way
- Try to focus on learning Python for data analysis. Don’t waste time on learning python for web development. Those are great skills to have (as web developers) but ROI will be really low for your job search.
- Focus too much on statistics and theory at the beginning
- Many students give up along the way because they get intimidated by the math part without understanding that data science also has a big focus on the DATA and you don’t need to write your own algorithms most of the time.
- Focus too much on technical side of machine learning
- It’s always great to learn more about ML theory but for job search, try to focus on ML pipelines, feature selections, model selection, and most importantly model presentation and interpretation.
- Learn for the sake of learning but not doing projects
- One can’t get a data scientist job without working on hands-on projects. Hiring managers can’t be fooled easily.
- Skipping big data and cloud
- Having big data and cloud skills under your belt will increase your chance of getting noticed. You don’t have to be an expert in big data before you start job searching. It will take you months to learn something new but keep learning is the key.