Data engineering is a hot topic in recent years, mainly due to the rise of artificial intelligence, big data, and data science. Every enterprise is transforming in the direction of digitalization. For enterprises, data is full of infinite value. For all the data requirements of organizations, the first thing they need to do is to establish a data architecture/platform and establish a pipeline to collect, transmit and transform data, which is what data engineering does.
In a Data Engineering project , data is collected, organized, processed, distributed and stored. For example, before starting an AI and Data Analysis project, Data Engineers first need to connect to various data sources to collect data, then work on data transmission and transformation, and finally store the data in a designated place(e.g. a data warehouse) , in a designated format(e.g. a database). We call the full process “a data pipeline”. From the endpoint where the final data is stored, the AI or Data Analysis team will build their connection to the data and start their data activities. In many cases data engineering also automates this data pipeline.

Data engineering is a hot topic in recent years, mainly due to the rise of artificial intelligence, big data, and data science. Every enterprise is transforming in the direction of digitalization. For enterprises, data is full of infinite value. For all the data requirements of organizations, the first thing they need to do is to establish a data architecture/platform and establish a pipeline to collect, transmit and transform data, which is what data engineering does.
Data Engineering is a field that has been growing rapidly in the past few years. The google trend above speaks for itself. You must have lots of questions about data engineering. For example,
- So what is data engineering?
- Why is data engineering important?
- Why should companies care about data engineering?
This article explains what data engineering is and introduces some useful use cases.
What is Data Engineering?
Data Engineering is the process of collecting, ingesting, storing, transforming, cleaning, and modelling big data. It is properly governed by people and process, driven by modern tools, and adopted by data engineers to support data & analytics teams to drive innovation.
It is safe to say that anything that’s data related has something to do with data engineering. And most importantly, all companies that invest in data science and AI need to have very solid data engineering capability.
The following are important aspects of data engineering.
Data Collection
Data collection is the process of collecting and extracting data from different sources. Most companies have at least a dozen different data sources. Data can come from different application systems, SaaS platforms, the Internet, and so on.
- If data comes from a database, data collection means building the connectors to read data from the databases (e.g., a relational database or NoSQL database)
- If data needs to be extracted from a SaaS software platform such as Mailchimp or Hubspot, then data collection means writing the connectors to read data from different data APIs
- When data is not directly available, data collection may involve writing javascript or python code to scrape data from the Web
Data Ingestion
When data gets collected from the source, it needs to be ingested into a destination. We can save the data as a CSV file on a server, however a well designed system will take many things into consideration:
- How fast does the data needs to be ingested?
- How frequently should the data be ingested?
- How many different destination will share the same data and at what pace?
- How scalable does the ingestion pipeline need to be?
Data Storage
Data storage is a big topic. Depending on the use cases of the data, data engineers may choose different storage systems and formats. For example, analytics engineers and data analysts may prefer data to be stored in a relational database (RDBMS) such as Postgres or MySQL, or a data warehouse system such as Snowflake, and Redshift. Big data engineers may want the data to be persisted in a data lake such as Hadoop HDFS, or AWS s3. Modern data engineers may even want the big data to be stored in a Lakehouse.
Data can also be stored in many different formats, from flat files such as CSV, to JSON and Parquet. In the database world, data can be stored in a row-oriented or columnar-oriented databases.
Data Transformation
Most data systems have a staging environment where raw data can be prepared before loaded into the destination systems. At this stage, data will go through a series of transformations to meet the business, compliance, and analytics needs. This is a stage where data engineers spend a big chunk of their effort on data transformations. Common data transformation steps include:
- Data selection
- Data filtering
- Data merging and joining
- Data aggregation
- Data grouping and windowing
There are many tools that are leveraged in this stage by data engineers. Depending on the data processing platforms, data engineers may use tools such as:
- DataFrame (Pandas, Dask)
- SQL
- Spark (MapReduce, SparkSQL)
Data Pipelines & Automation
Data engineers usually build data processing DAGs (Direct Acyclic Graph) that have dependencies on each other. In order to build high-quality data applications, data pipelines should be as automated as possible, and only intervened when parts of the lineage break that requires a data engineer’s attention. It turns out that data pipelines can become quite complex and unwieldy. It needs to be well-tested and software engineering best practices also need to be adopted by data engineers.

Data Quality and Governance
Data quality is a big part of enterprise data governance effort. While building a data pipeline, data engineers always need to include data quality checks so that the pipeline doesn’t run into Garbage in, garbage out problems. A small issue in a pipeline may result in very bad data quality and therefore ruin the entire data science and analytics effort.
Data governance is not just a technique. It involves people and processes. Companies assign data owners and stewards to come up with governance policies. Data quality and monitoring processes are essential parts of the process.
The Convergence of Engineering Disciplines

In the past few years, we’ve started to see the convergence of the engineering disciplines. Modern data engineering requires skill sets from many disciplines. For example, in some companies a data engineer may need to know DevOps to certain degree so that she/he can write well-tested and automated data pipelines. Data engineers are often writing production-grade software code such as data connectors and pipelines. In many organizations, data engineers may also need to do basic analytics, build dashboards, and even help data scientists automate machine learning pipelines.
Can Data Engineering be automated?
At WeCloudData, we often hear this from our students. Can data engineering be automated? The answer is: of course! And it should be automated as much as possible.
Automation is happening in every industry with the advancement in AI. For example, ChatGPT can probably write a data pipeline script by simply predicting the next word. Github copilot is already powering a lot of developer and software engineering’s daily work.
In recent, we also see many projects and startups building GUI-based data engineering tools, which make building data engineering a low-code or no-code effort.
However, from WeCloudData and many experts’ perspective, because producing high quality data for analytics and AI is so crucial for a company’s innovation, companies should and will rarely completely rely on code generated by bots and AI. While many low-level code should be automated, the business logics are often hard to automate. For example, banks using exactly the same tools and systems will end up building very different data engineering pipelines due to the differences among legacy systems, talent, budget, existing infrastructure, internal policies, and business logics.
Traditional Data Engineering
We’d like to point out that data engineering is actually not new concepts. It has been around for as long as data systems exist. However, it may have lived under different names. For example, data engineers might be called ETL Developer in a bank, or Big Data Developer in a tech company, Data Warehouse Engineer or Data Architect in an insurance company, or simply software engineer in a data-driven startup. The reason why we call it traditional data engineering is because the field has evolved so fast it the past 8-12 years that many old technology stacks are really used or are being phased out in many companies. The data industry is abundant with tooling choices and companies are constantly looking for better ways to scale and manage their data engineering efforts.
ETL Developer
- Big companies used to hire many ETL developers to work on data migration and ETL projects. ETL is short for Extract-Transform-Load. Identifying new data sources and requiring new data integration prompts the business to call upon ETL developers.
- ETL developers are very specialized in data transformation and usually work with legacy platforms such as IBM data stage, Informatica, etc.
SQL Developer
- Companies working with relational databases and data warehouses often need SQL developers to help write advanced queries to load and transform data. Compared to data analysts and data scientists, SQL developers are more specialized in database internals and are able to write more efficient and advanced queries. This usually means cost saving and improvement of query performance.
Big Data Developer
- Ever since the birth of MapReduce and Hadoop in 2016, big data developers have been in steady demand, especially in enterprises or tech firms that collect and process big data.
- Big Data Developers are usually coming from software engineering background. They understand distributed systems well and can write MapReduce and Spark jobs to process large datasets.
Modern Data Engineering
While the fundamentals of data engineering haven’t changed dramatically in the past 10 years. The tools and ecosystems have grown tremendously. For example, Apache Spark has dethroned MapReduce to become the king of big data processing. Many companies that have invested heavily in data lake are now realizing that they need to chase the next wave of Lakehouse initiatives while keeping running the legacy big data systems.
There’re a several data data engineering trends to watch out for in the coming years:
The Modern Data Stack
- SQL is having a comeback in recent years. This is certainly good news for many because SQL has been widely adopted and loved by analysts, engineers, and developers. The modern data stack community usually choose certain data technology stack and believe that SQL can be used to solve most of the modern data challenges.
- One example of a modern data stack is as follows:
- Data ingestion: Fivetran
- ELT: dbt + Snowflake
- Reverse ETL: Hightouch

The Data Lakehouse
- The traditional big data tech has proven to be clunky and doesn’t meet all the data processing needs by enterprises. In the past few years, streaming data processing has become more and more popular and companies have been asking for ACID features in the data lake.
- Data Lakehouse technologies such as Apache Hudi, Apache Iceberg, and Databrick’s Delta Lake have been the buzzwords in big data tech. It allows companies to combine the processing of both real-time and batch data.

Serverless Data Engineering
- Another interesting trend in modern data engineering is driven by the rapid adoption of Cloud technologies. Cloud service providers such as AWS, Azure, and GCP have built new capabilities that enable data engineers to run data processing and analytics pipelines in a serverless fashion.
- While it won’t meet every company’s needs, and can get overly complex for large-scale problems, Serverless brings the benefits of flexibility, transparency in pricing, and scalability.
Data Engineering Use Cases
Data Warehouse
A data warehouse is a centralized location for storing a company structured data. It usually stores product, sales, operations, finance, as well as marketing and customer data. Raw data will be extracted from data sources, properly cleaned and transformed, modelled and loaded into the data warehouse. An enterprise data warehouse powers most of the business intelligence and analytics efforts and therefore is a critical piece of data infrastructure.
For example, the sales team may want to understand daily/weekly sales performance. Traditionally, IT may help write SQL queries to prepare the data for ad-hoc reporting. However, the prepared data may have useful information that can be leveraged by marketing, sales, as well as product teams. Therefore, having a data engineer prepare the data and load the data into a data warehouse that can be access by different teams will be very valuable. Different teams will access a single source of truth so data interpretation can be as accurate and consistent as possible.
Who should care about Data Engineering?
The answer is simple: everyone should.
Executives and stakeholders
It is important that company’s executives understand the importance of data engineering. It’s directly related to budgeting and companies should invest in data engineering as early as possible. As the data systems and problems become more complex, the cost of data engineering and architect mistakes become higher.
Data Scientist
Data Scientists and analysts should have a solid understand of common data engineering best practices. Many organizations and data scientists believe that data engineers should always prepare the data. We believe that data scientists need to know how to write efficient data processing scripts, and rely less on data engineers to prepare data. Though data scientists don’t need to write and automate many data pipelines as data engineers do, acknowledging the importance of writing efficient and scalable code is important.
Developers
Software engineers and developers write web/mobile applications that generate raw data. They usually work with data engineers to collect and ingest data into data lakes and warehouses. Developers and data engineers must communicate frequently to sync up on source data structure changes and minimize the impact on data ingestion pipelines.
IT
IT will often need to work with data engineers to provide source data connection details, providing access to infrastructure, and respond to other internal requests. It’s important for IT professionals to understand common data engineering workflows.
Become a Data Engineer via WeCloudData’s Data Engineer Bootcamp
What is a Data Engineer
We introduced that data engineering as the process of collecting, ingesting, storing, transforming, cleaning, and modelling big data. Data engineers are the talents that are mainly involved in this process. Let’s break it down and give more specific examples.
Data Collection
Depending on the data sources, data engineers work with different tools to extract data.
- When the source data is a relational database such as Postgres or MySQL, data engineers will usually write SQL queries to extract the data. The queries contain business logic and data engineers contract the queries to retrieve data from databases. When the source data is stored in NoSQL databases, data engineers will construct queries using the NoSQL database specific API
- When the data sources are SaaS software such as Mailchimp or Hubspot, modern data engineers may work with pre-built connectors provided by tools such as FiveTran or Airbyte to automate the data extraction and ingestion. When connectors are not available, data engineers may need to write custom connectors or work directly with the SaaS API.
- Sometimes data engineers need to use Python or other programming tools to do web scraping and crawling to extract the data from websites. Scrapy, Selenium, and Beautifulsoup are popular python packages data engineers would use for web scraping.
Data Ingestion
Data engineers work with many tools for data ingestion. Which tool to use usually depends on the company’s existing data infrastructure and project goals and budget.
- In companies that build modern data stacks, data engineers might be working with Fivetran, Stitch, or Airbyte to directly ingest data into the data warehouse. In this case, coding is only required when custom connectors need to be created. The focus on data engineers will then be on the data transformation. This approach follows the ELT paradigm.
- In companies that deal with lots of unstructured data, data engineers may need to ingest data into the data lake first. For example, AWS S3 or Hadoop Distributed File System. In this case, data engineers will need to work with the input data format and help define the output data structure. Data engineers will also need to write code to do some preliminary data encryption and masking to comply with the privacy act. Serverless functions such as Lambda functions are often used to transform data on the fly before it gets saved into the destination.
- In many cases, modern data engineers may also need to work on ingesting streaming data for real-time processing and analytics. Data streams from the sources systems will be ingested into distributed message systems such as Kafka and Kinesis.
Data Storage
Data engineers also need to work with many different storage systems:
- Relational databases (Postgres, MySQL, SQL Server, etc.)
- NoSQL databases (MongoDB, DynamoDB, Cassandra, Elasticsearch, etc.)
- Data warehouse (Snowflake, Redshift, Big Query, Azure SQL Warehouse)
- Data lake storage (Hadoop, Object storage)
- Data lakehouse storage
Data engineers should understand the differences among different database engines and their particular use cases and help the company choose the right databases for storage. This is sometimes what data architects would do in bigger companies.
Data Transformation
Data transformation is where data engineers spend the bulk of their time. Data engineers work with tools like SQL, Spark, and Lambda functions to transform the data in batch or real-time.
Data transformation is important because only when business logics get applied to the process will the data generate real business value. This is where we see significant differences among companies.
- When the company deals with large datasets, data engineers may write Spark jobs to process data in a distributed cluster
- When the company uses a data warehouse, data engineers may leverage tools such as dbt and SQL for transforming complex data
- When is dataset is small and messy, data engineers may just work with Pandas for data transformation and the pipeline can get deployed in AWS Lambda.
Data transformation can happen in different places.
- If modern data stack is adopted, data engineers would write data transformation logics inside the data warehouse and use tools such as DBT to automate the workflow
- If the company adopts the ETL approach, data engineers might be using external tools and platforms such as Apache Spark for data transformations and then load the data into a traditional warehouse.
- The more traditional approach in big companies will have data engineers work with specialized ETL tools such as Informatica where transformation is done also in an external environment before data gets loaded into the downstream data store.
Data engineers working on ETL/ELT need to have very solid understanding of data modelling for RDBMS and NoSQL engines.
Data Pipelines & Automation
ETL/ELT are very complex processes. The code base can get hairy and hard to control as the project grow, especially when the business logics are complex. In some large systems, data engineers may need to deal with thousands of database tables and without automation is can be quite daunting tasks.
Data processing units often times have dependencies on each other. For example, a data pipeline that processes one massive transaction table might need to be used by several other downstream processes. Instead of building separate pipelines and re-process the hour-long data pipeline, it makes sense for all downstream pipelines to depend on the same pipeline that produces the transaction table. This creates a DAG (Direct Acyclic Graph) and data engineers will need to build and maintain the DAGs for complex data processing needs.
Data engineers will leverage platforms such as Apache Airflow, Prefect, or Dagster to build and orchestrate pipelines. Some of these platforms can be orchestrated on Kubernetes clusters so data engineers also need to have basic understanding of containers and container orchestration.
Data Engineer vs Data Scientist vs Software Engineer vs DevOps Engineer
You probably notice that when we introduced data engineering, we didn’t really mention statistics, math, and machine learning. That is one of the major difference between data engineering and data science. Data engineers mainly focus on building data pipelines, data ingestion, and preparing data for data analytics projects and don’t need to build machine learning models. However, data engineers work very closely with data scientists and share a set of common skill sets. Data engineers sometimes also need to have software engineering and devops skill sets.

Data Engineer vs Data Scientists

- Both data engineers and data scientists (or BI engineers) need to be very good with writing SQL queries, which is the fundamental data skills for manipulating data stored in relational databases. While data engineers will mainly use SQL to transform raw data and load them into analytics environments, data scientists will be extracting relevant data from the analytics databases for exploratory analysis and machine learning. In short, data engineers make sure that data is prepared properly with high quality and data scientists will perform actual analysis on those prepared data for insights.
- Data engineers and data scientists also need to be skilled at programming. When data is not processed in SQL databases, they may write python and spark scripts to process data in different execution environments such as a Spark cluster, or AWS Lambda function (serverless functions), or a python process in a container.
- Data engineers will be writing python scripts to automate data pipelines in Apache Airflow or Prefect, while data scientists might be using the same tools for building the machine learning pipelines. In some companies, ML pipeline automation can also be done by the data engineers but it’s up to the data scientists to develop, train, and tune the machine learning models.
- Data engineers and data scientists will also need to be comfortable with working with big data frameworks such as Hadoop and Spark, with data scientists focusing more on the ML side.
Data Engineer vs DevOps Engineer / Cloud Engineer

When you look at WeCloudData’s data engineering bootcamp curriculum, you will notice that we cover a lot of cloud computing knowledge. We not only teach students how to work with data but also cover important aspects of data and cloud infrastructure. Both DevOps Engineer and Cloud Engineer need to work with cloud infrastructure as well. Here’re the similarities between data engineers and DevOps/Cloud Engineers
- DevOps engineers help software team build CI/CD pipelines. This requires knowledge of software development lifecycle, continuous integration, and continuous deployment. On the CI/CD side, DevOps engineers mainly deal with software code. Data engineers on the other hand, work with data pipelines. They not only work with pipeline code but also need to make sure that the data is properly version controlled and is of high quality.
- DevOps engineers version control code while data engineers version control both code and data.
- Both DevOps engineers and data engineers need to know how to write test cases and follow test-driven best practices.
- Both DevOps engineers and data engineers work with cloud infrastructures. While DevOps engineers focus more on IaaS (Infrastructure-as-a-service) and IaC (Infrastructure-as-code), data engineers work more closely with PaaS (Platform-as-a-service) tools. For example, data engineers might be working with Snowflake for data warehousing and Databricks for big data processing, but they usually don’t set up the underlying infrastructure for these platforms. From time to time, during PoC (proof-of-concept) stage data engineers may be required to benchmark different tools and will set up the environment using docker containers and work with cloud compute and storage systems such as AWS EC2, ECS, and S3.
- DevOps and Cloud Engineers will spend more effort on creating and maintaining the cloud infrastructure. For example, to help the company scale the application and data systems, DevOps engineers will work with cloud engineers to create a Kubernetes cluster. They make sure that the infrastructure is reliable, secure, and scalable. On the other hand, data engineers focus on processing the data that gets generated through applications and prepare them for analytics purposes.
Data Engineer vs Software Engineer

In big tech companies, a lot of data engineers actually come from software engineering background. Some of these are data-savvy engineers and developers. Data engineers and software engineers sometimes need to work closely to define the data format used for extraction and ingestion purpose. Any upstream changes on the software application side such as adding new tables, changing table structures, or adding/removing fields need to be communicated properly with data engineers who work on data ingestion.
- Data engineers also share a common set of skills with software engineers. For example, they all need to have good foundational knowledge of computer science. They know at least one programming language very well, such as Python, Java, or Scala.
- Both data engineers and software engineers need to be familiar with distributed systems and big data. The big data engineers might be focusing on streaming data processing and building data-intensive applications, while data engineers focus more on building big data pipelines for batch and streaming data.
- Both data engineers and software engineers need to know SQL very well. Software engineers write CRUD (Create, Read, Update, Delete) operations so their applications can interact with databases, while data engineers will be working with lots of data at the same time (extracting, transforming, loading) in batches.
- Software engineers and data engineers also need to know how to write unit test and integration test cases. Data engineer will write test cases to make sure that data transformation functions and UDFs are validate and take all cases into consideration. They also need to write queries to test the validity of the data tables they are dealing with in the data pipeline, to avoid garbage in, garbage out situations.
The Value of Data Engineers
Truth be told, data engineers don’t get the same glamour as data scientists do. DS and DA work more closely with the business teams such as product, marketing, and sales. Business teams are always hungry for data and insights to drive better decisions. Therefore, data scientists and analytics are more likely to get the recognition.
Data engineers are the unsung heroes. But many organizations today are starting to realize the importance of data engineers. In the U.S., senior data engineers earn higher salary on average compared to DS and DA jobs. Many startups are hiring data architect and engineers before hiring data scientists. We created the diagram below to help you understand how different teams collaborate and the importance of data engineers.
Let’s start from the bottom of the diagram.
- Data Engineers
- Before any machine learning and analytics can happen, data need to be collected. Data engineers work with the application team to identify data sources and metadata.
- Data engineers help ingest the raw data into the data warehouse or data lake and help encrypt and mask the raw data.
- Data engineers then build data pipelines to transform and integrate all the data to create the analytics data tables for analytics purpose.
- Data Analysts
- Data analysts extract data from the analytics database and create ad-hoc reports to address business users’ questions.
- Data analysts work with dbt to transform data and build wide tables for reporting purposes (in some companies this could be done by BI developers, analytics engineers, or data engineers)
- Data analysts present the dashboard and ad-hoc reports to the business, get their feedback, and tweak the dashboards/reports till it’s accepted by the end users
- Data Scientists
- Data scientists extract data from analytics database or data lake and begin with data exploration (EDA → Exploratory Data Analysis). Heavy lifting data preparation steps are usually performed in data warehouse (snowflake, redshift, big query), or data lake (athena, trinodb, spark, etc.)
- Data scientists then bring data into the machine learning environment such as AWS SageMaker and Databricks spark cluster
- Data scientists work on various experimentations and build ML pipelines for supervised or unsupervised learning
- The predictive modeling outcome will be interpreted by data scientists to the product and marketing teams
- Once the models are accepted, data scientists work with data engineers or machine learning engineers to automate the scoring process (in many companies, the model scoring and deployment is handled by data scientists as well)
- Machine Learning Engineer
- Machine learning engineer help data scientists train and tune ML models at scale. For data intensive ML jobs, machine learning engineers may leverage distributed platforms such as Spark for data transformation and feature engineering
- For model training, machine learning engineers leverage open source frameworks such as Ray or Spark ML for large-scale model training. AWS Sagemaker is used by MLE at companies that prefers the AWS ML stack
- Machine learning engineer also need to help deploy the ML models. Some of the tasks cover model packaging, building prediction service endpoints, and model testing and validation after deployment. Model retraining and tuning pipelines are automated by ML Engineers as well. Some of these fall under the MLOps realm but in many organizations, MLE actually wear multiple hats. The line between MLOps and MLE are pretty blurred.
Hopefully this section explains the importance of data engineers. One suggestion WeCloudData would like to give is try to develop crossover skills. Whether you want to specialize in DS, DE, or MLE, it’s always helpful to learn some skills from other roles.

A Day in the Life of a Data Engineer
What does a typical day look like for a data engineer? Well, it varies and depends on what type of data engineer we will talk about. For this section, let’s have a look at a typical day in the life of a data engineer working on data lake projects. Note that not all data engineers work in the same way so take it with a grain of salt.
- 9:30 – 10:00 – Log on to work laptop and reply some emails. Have a quick check the data pipeline dashboard to make sure nothing alarming’s going on
- 10:00 – 10:30 – Meet with the team in daily project standup meeting to discuss accomplishment, challenges, roadblocks for the day
- 10:30 – 12:30 – Then pick an assigned task from JIRA and start to work on a new data transformation task using AWS Lambda function
- 12:30 – 13:30 – Lunch break
- 13:30 – 14:30 – Wrapping up the data transformation task, test it locally, and deploy it to the cloud
- 14:30 – 15:00 – Join a meetup with the product manager and data scientists to discuss new data ingestion requirements. Contribute to the meeting minutes.
- 15:00 – 17:00 – Draft the data pipeline architecture using Lucidchart and send the draft diagram to related teams
- 17:00 – 17:30 – Send slack messages to the platform team to discuss the pros and cons of different CDC (change data capture) strategies for a new ingestion project. Log the work in JIRA or Notion and wrap up the day.
Different Types of Data Engineer

If you’re about to embark on a data engineering career, make sure you understand that there are different types of data engineers and depending on the teams, the scope of their work may be very different.
Data Architect vs Data Engineer
We got this questions often: what is the difference between a data architect and engineer?
Well, while a data architect may come from a data engineering background, he/she primarily work at the strategy level. Data engineers on the other hand spend more time on the executions. Let’s dive in and discuss the different types of data engineers.
Four types of data engineers
In this section, WeCloudData categorizes data engineers into four different types:
- ETL/ELT Engineer
- ETL engineers are typically involved in data ingestion, integration, and transformation. They work with various data sources and bring the source data into the data lake/warehouse. They work with different data connectors and data ingestion tools to bring web analytics data, SaaS data, and operational data together and integrate them via big data processing. Some big companies use traditional tools such as Data Stage and Informatica and require data engineers who have specialized experiences. Many tech companies may work with open source tools such as Apache NiFi, Kafka, and Hadoop for data ingestion and integration. ETL engineers need to learn many different tools as they move from projects to projects. But keep in mind… tools are just tools, the most important skills of ELT engineers is the ability to write good code to transform data based on complex business logic, and this requires strong SQL, python, spark programming skills, solid understanding of data models, and great attention to details.
- Data-savvy Software Engineer
- In big tech companies, many data engineers are from software engineer background. This type of data engineers help companies build data-intensive applications. For example, to build a real-time recommender system that can handle tens of thousands of requests every second requires very good system design skills. Unlike the ETL/ELT data engineers who take care of the quality of data throughout the transformation stages, data software engineers care about the scalability of the data applications, latencies, and reliability. They work with streaming data ingested into Kafka and write Spark Streaming jobs or Apache Flink jobs to process the data in near real-time, and ingest the processed data to other data store such as caching or NoSQL databases. Instead of SQL and python, they are more likely to work with programming tools such as Scala, Java, or Go.
- BI/Analytics Engineer
- BI and Analytics Engineers mainly work in the data warehouse environments. They work with data connectors such as Fivetran to ingestion data into the data warehouse such as Snowflake, use dbt for SQL-based data transformations, build the dimensional models or wide tables for analytics purposes.
- Analytics engineers don’t need to be specialized in python and spark and they need to be really good with complex sql queries and data modeling.
- The rapid development of the modern data stack ecosystem has helped create many analytics engineer jobs. Cloud data warehouse platforms such as snowflake has also resurged sql-based data modeling.
- ML Data Engineer
- A common understanding is that ML engineers work on building ML pipeline. But, in many companies, especially startups data engineers need to wear multiple hats. Ultimately it’s the job description, not the job title that defines a role. So don’t be surprised to be asked to automate ML pipelines.
- Data engineers also work really closely with the data science team or even work in the data science team. A lot of the ML Engineering work actually involve data engineering skills.
- WeCloudData’s suggestion for aspiring data engineers is never give up the opportunities to learn crossover skills.
We hope that this article helps you understand what data engineers are and what they do on a daily basis. If you liked this article, please help us spread the word.
Data Engineer Career Path
Understanding the career path of a data engineer is important before you kick start your new career. The good news is that data engineers have many career path options. We’ve seen people going down different paths and be successful and happy with their jobs.

Senior/Lead/Staff Data Engineer
Data engineers spend most of their time heads down working on implementation, be it a data pipeline or spark job optimization. As the role becomes more senior, the role will get more involved in architectural design meetings and business meetings. Time will also be allocated to mentoring other junior data engineers. A lead data engineer will also be setting the project roadmap along with the leaders and carrying out larger scope data projects. If you want to go down the technical career track and become the staff engineer eventually, be prepared to:
- Go deep and become specialized in certain areas
- Keep learning new technologies in this field and stay abreast with the latest trends
- Work on a variety of large-scale project implementation and widen your knowledge base
- Become a generalist since a large scope project will require more than just one skill
- Get comfortable working with different teams including: software, data science, platform, as well as business.
- Be ready to lead even without a manager title
Manager Track
As the data engineer moves up the career ladder and take up more responsibilities, he/she will start to spend less time on execution and more time on mentoring, business communication, and management. A manager’s role is not the best fit for everyone. Many engineers would avoid becoming a manager so that they can focus on the technology side. However, the persons with the right mindset and motivation will make the transition and thrive in a leadership role.
WCD’s suggestion for those who would like to work in tech leadership roles is that you need to ask yourself the following questions:
- Would enjoy having a job that requires less technical implementation tasks
- Would you enjoy a role that requires you to support other team members instead of focusing on your own growth
- Are you the type who
- Are you dealing with different teams and
- Are you able to have tough conversations and pick up leadership skills
Talking to a mentor who has been in tech leadership roles can be very helpful. Once you’re sure, start preparing early. Opportunities are there for those who are prepared.
Data Science & Analytics
It’s not uncommon to see data engineers going down the data science and analytics route. Data engineers usually work on the data ingestion and ETL parts of the data pipeline but they don’t do a lot of analysis of the data. Since data engineers share a common set of skills such as Python, SQL, AWS, and Spark, it’s not a very big jump from a technical perspective.
However, data engineers will need to put more effort into statistics and machine learning so that they have the advanced analytics skills required for the DS job.
Data Engineering requires less statistics, math, and machine learning. The requirements for coding is higher, data engineers need to be comfortable writing production-grade code. Data transformation functions need to be properly tested. And data engineers also need to have an architect-level view of the entire data pipeline and make sure things run smoothly in production.
Software Engineer
Software engineering can be a good career path for data engineers as well.
Data engineers and web developers share similar skills but the two roles are quite different. For example, a full-stack engineer job will require the knowledge of front-end and back-end development. A data engineer role doesn’t overlap much with it and data engineers will need to learn new skills such as Javascript, React, and/or Node in order to work in web development.
Data engineers have skills more similar to backend software engineers. For example, both need to know RDBMS, NoSQL, Python or Java, APIs, etc. If a data engineer wants to become a software engineer later to work on building data-intensive software application, he/she will need to learn the fundamentals of software development lifecycle and system design.
Tech Evangelist / Developer Advocate
Another interesting path to go down is the tech evangelist route. If you love new technologies, have worked on many different types of projects using different tools and platforms, and love communications and community building, the tech evangelist role might be a good fit. Take the big data world for an example, when new technologies such as Hadoop, Spark got open sourced, many startups were created for that specific technology in the ecosystem. Companies will need very good tech evangelists who come from a technical background and who can help advocate the technologies and build up the developer ecosystem.
Consulting
With so many businesses going through digital transformations, the demand for data consultants become increasingly high. Many companies don’t have the budget to own or experience to run a data engineering and science team. But they still have interesting data problems. Companies that want to collect more data for advanced analytics also want some experts’ help on laying the data infrastructure, migrating legacy systems to the cloud, and building the data pipelines. This is where consultants step in and provide lots of value.
One suggestion WeCloudData would like to give anyone who wants to work on data engineering consulting is that you need to become specialized in certain areas. Companies hiring consultants are usually looking for specific skills. As a consultant, you also need to learn and adapt to new skills very quickly.
Data Engineer Job Market
Data engineer jobs are in very high demand. Though the job market demand is seasonal and fluctuates a lot throughout the year. The overall trend is very encouraging. A quick search on LinkedIn (as of Feb 6, 2023, after the recent tech job cuts) shows 18,373 results for data engineer jobs. Of course, the matching results may include jobs that are not strictly data engineer roles but the relative scale speaks for itself.
Data Engineer Jobs on Linkedin
Compared to data analytics and data science jobs, job demand of data engineers is also usually on par! Many companies have started to realize the importance of data engineering and that’s great news for career switchers.
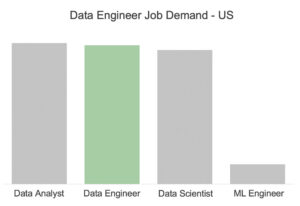
Data Engineer Jobs by Region
Data Engineer Jobs in the U.S.
If you zoom in on the region level, in the United States, data engineer job demand come from many different states, with a concentration on California, and Virginia, Texas, and New York.
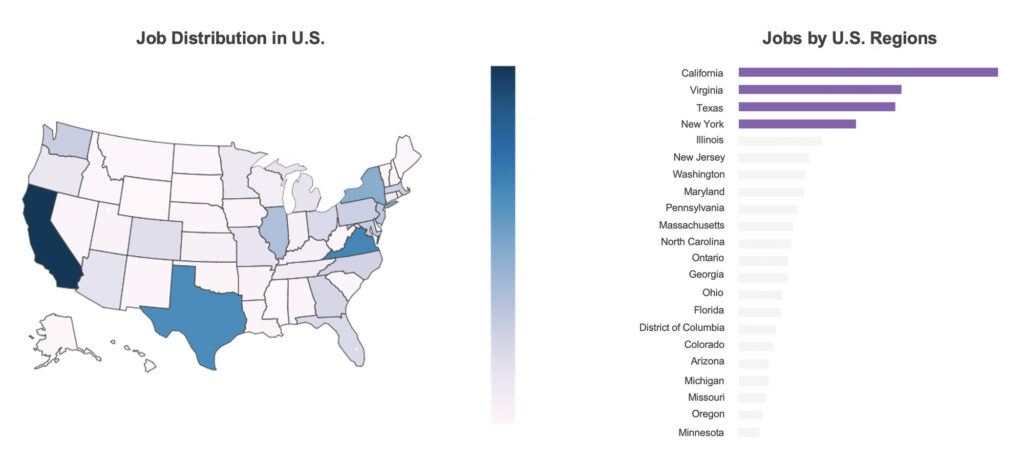
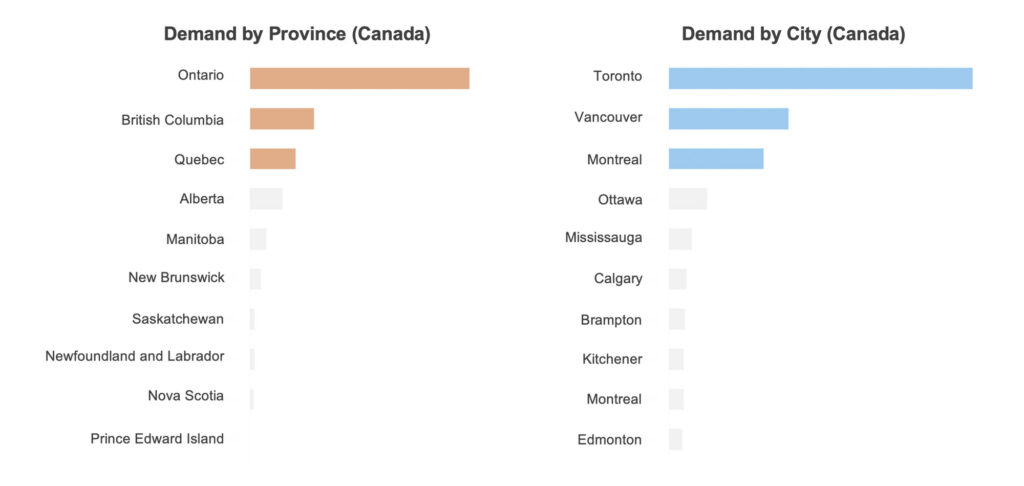
Data Engineer Jobs in Canada
In Canada, the Greater Toronto Area accounted for a large portion of data engineering jobs, followed by Vancouver and Montreal areas.
Data Engineer Job Market: Work Experience
While data engineer jobs are in high demand, it usually requires more experience. Based on WeCloudData’s research and our experience working with different hiring partners and recruiters, we came to a conclusion that in the current job market, and as more companies go through digital transformation, senior roles are in higher demand.
After collecting thousands of jobs from recruiting websites, we did some analysis on the years of experience required for DE jobs which validates our assumption. The chart below shows that 32% of the DE jobs require mentioned 3 years of experience, and usually in job description
Job Market: Demand by Years of Experience
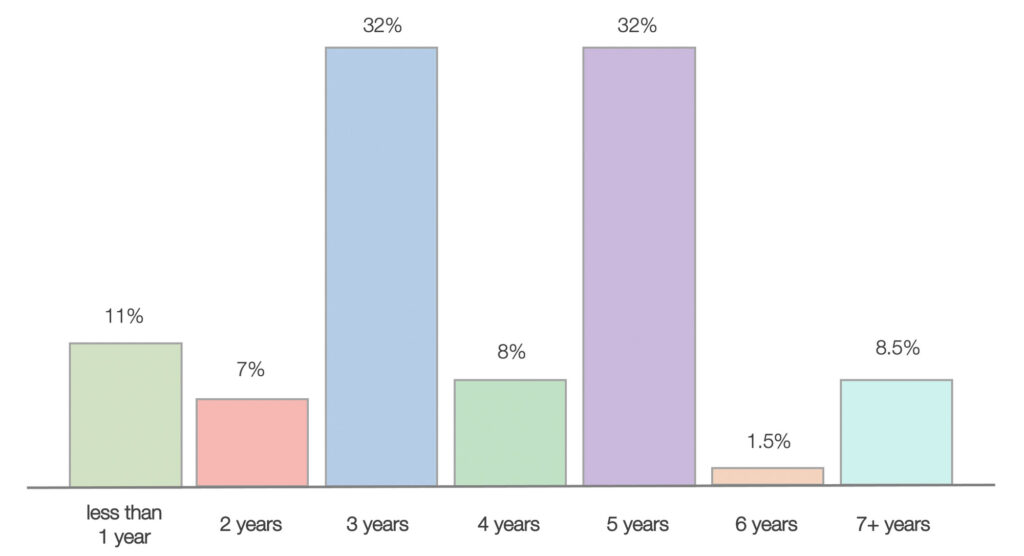
Data Engineer Jobs: Distribution of Work Experience Requirements
However, it doesn’t mean that junior data engineers are not able to find jobs. WeCloudData’s recommendation to career switchers are as follows:
- Hands-on projects can help you fill the experience gap. Unlike data science, there’s no Kaggle-like platforms for data engineers to work on projects. However, it also means that competition will be lower and if you have an awesome portfolio of projects, it’s quite easy to stand out.
- Try to gain end-to-end project experience. Companies would prefer data engineers who have understanding of the entire life cycle of a DE project: data collection, data ingestion, data transformation, etc.
Data Engineer Job Market: Salary
As enterprises pay more and more attention to data, the market demand for data engineering continues to rise. Data engineering is usually the first priority for companies entering the data world. Therefore, in recent years, the market demand for data engineering is very high and has caused a shortage of data engineering talents.
The demand for Data Engineers is the growth in big data engineering services provided by consulting firms like Accenture and other tech companies like Cognizant. The global big data and data engineering services market is certainly experiencing high demand. Growth estimates from 2017-2025 range from 18% to a whopping 31% p.a.
In the mean time, the salary of the Data Engineer is increasing faster than other similar positions. The following charts are the salary distribution of the Senior Data Engineers in the U.S. and Canada.
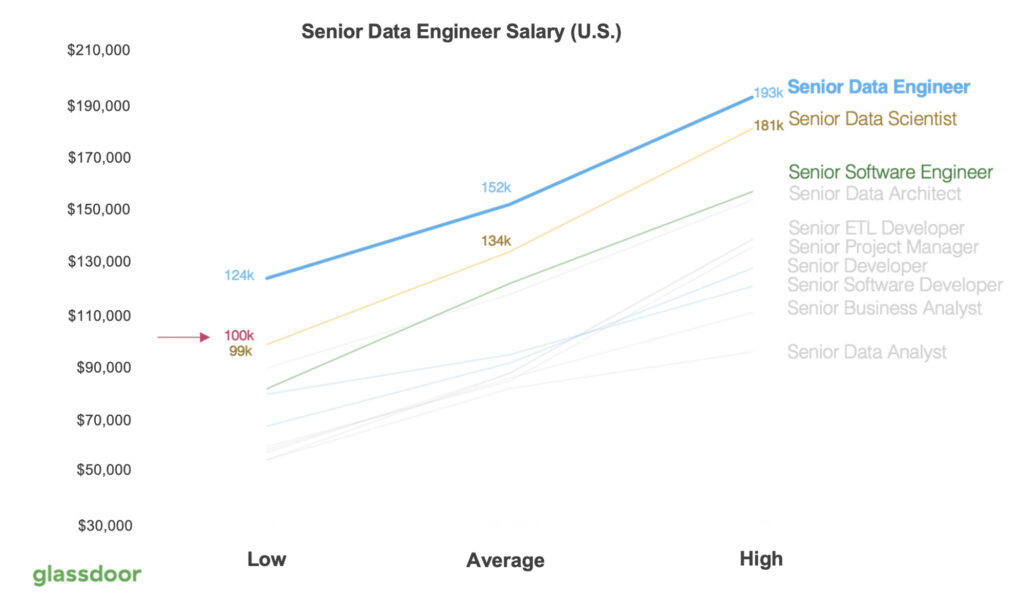
As you can see, in the U.S., senior data engineer has an average salary of $152,000 USD, and even higher than the average salary for data scientists. Take the data with a grain of salt because this may vary a lot depending on the companies and industries. With signing bonuses and stock options, data engineers joining big tech may get paid well over $200,000 in the first year.
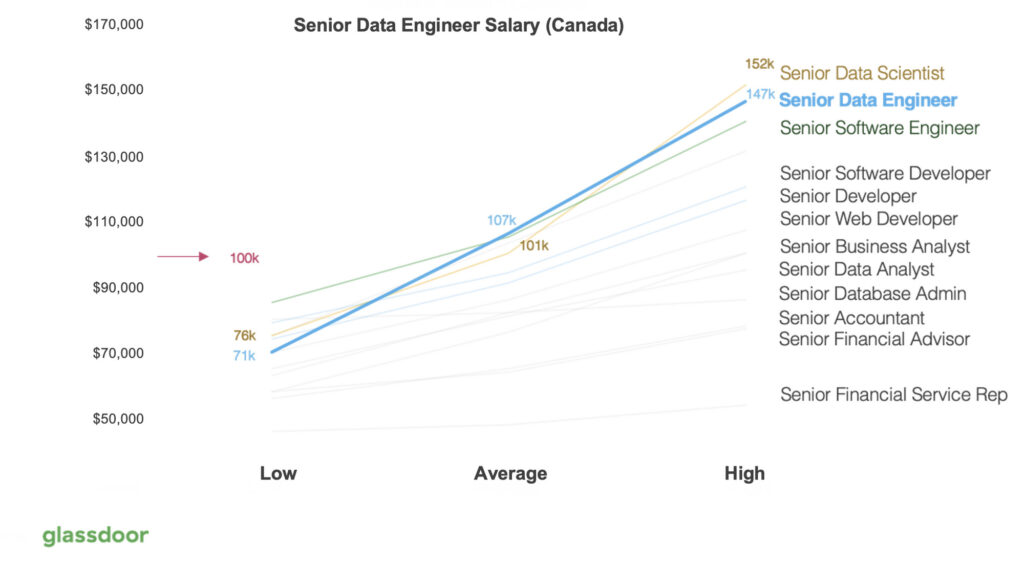
The average base salary of an intermediate level Data Engineer in Toronto is $91,497, according to Glassdoor’s 2022 market data. Here is a breakdown of the Data Engineer salaries by level:
| Level | Average Base Salary (CAD) |
|---|---|
| Junior Data Engineer | $81,923 |
| Intermediate Data Engineer | $91,497 |
| Senior Data Engineer | $121,241 |
| Lead Data Engineer | $ 125,567 |
Data Engineer Learning Path
The Importance of a Structured Curriculum
If you do some research on Google regarding top skills of a data engineer, you will be surprised to see how many skills a data engineer needs to know! Based on WeCloudData’s research (analysis done on thousands of job postings), top skills that appear most frequently on data engineer job descriptions are:
- Python
- SQL
- Spark
- AWS
- Hadoop
- Java/Scala
- Kafka
- NoSQL
- Hive
- Snowflake
- etc.
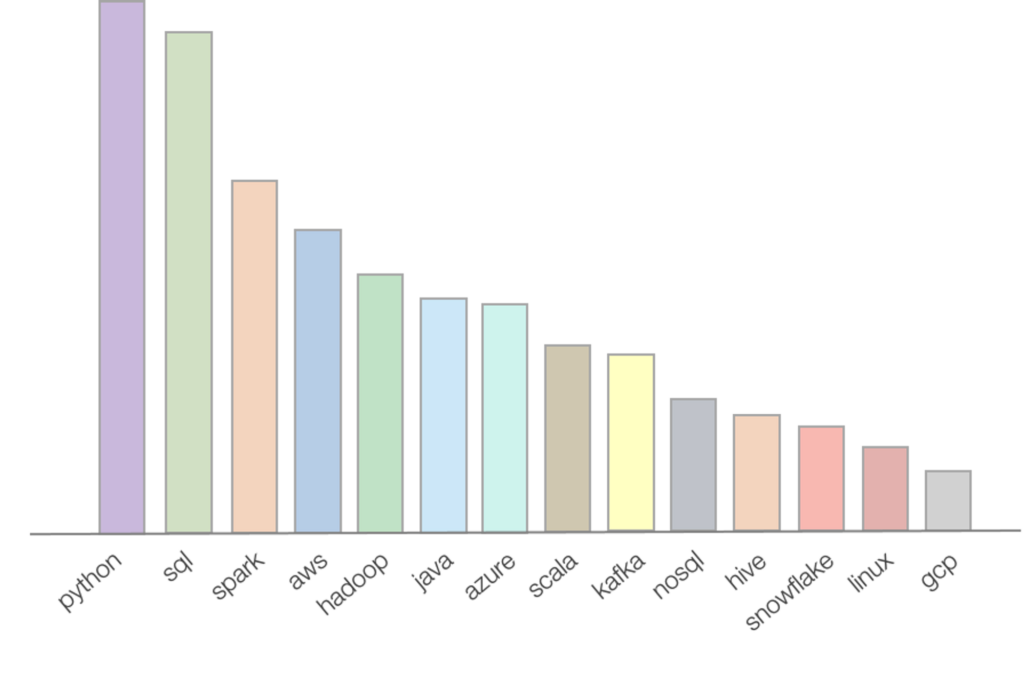
The actual list is quite long and for beginners that can look quite daunting. To make the matter worse, these tools cover different aspects of data engineering and it’s rare to have someone learn everything. It usually takes years of working on different types of DE projects to achieve that.
One of the mistakes frequently made by learners is chasing the tools. Warning ahead! Tools are just tools and one should not learn them for the sake of learning. Listing 30+ tools on the resume is going to cause more harm than good.
The best way to learn data engineering is to follow a structured curriculum. WeCloudData’s data engineering bootcamp has open sourced its curriculum. In this guide, we will discuss it in detail.
Following a structured curriculum has the following benefits:
- A structured curriculum can help the learners focus on learning the skills that are relevant and important
- A structured curriculum will tell the learners what’s important at each stage of learning and what can be learned later
- A structured curriculum will help the learners stay focused and get less distracted
- A structured curriculum can help the learners achieve their goals faster
- A structured curriculum with solid instructional design can help the learners become a more effective learner and grasp the concepts faster than self-paced learning
- A structured curriculum provides hands-on projects and exercises that can help the learners practice and reinforce the concepts
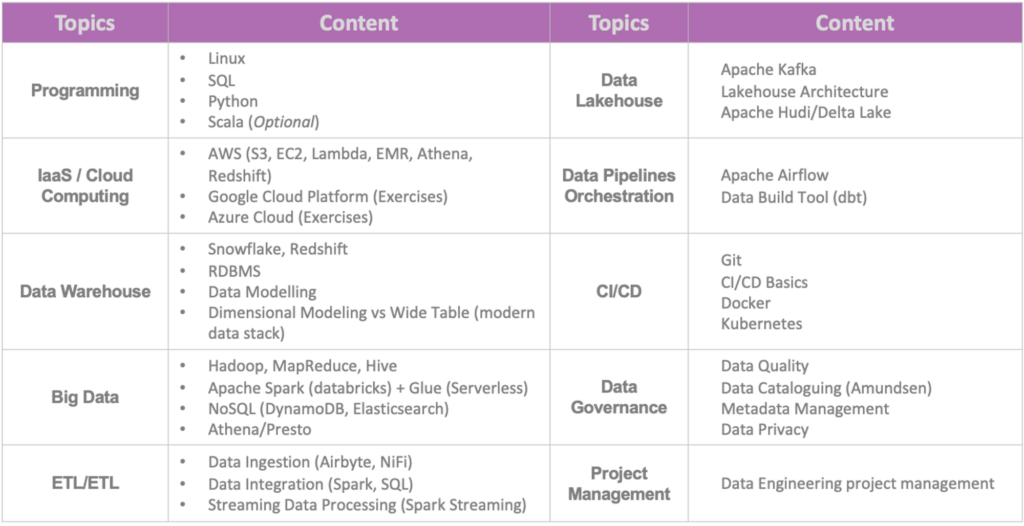
Here’s a list of topics that WeCloudData’s data engineering bootcamp covers:
- Programming (taught as part of the pre-bootcamp)
- Data Infrastructure & Cloud Computing
- Data Warehouse
- Big Data and Distributed Systems
- ETL & Data Integration
- Data Lake(house)
- Data Pipeline and Orchestration
- CI/CD for Data Engineers
- Data Governance
- Project Management
The Importance of Fundamentals
Before jumping into advanced topics of data engineering such as distributed systems, ETL, and streaming data processing, it’s important to have the fundamental building blocks of data engineering developed. For any data jobs, SQL and Python are always the most important skills to grasp. For data engineers in particular, linux commands and git are also key skills to learn.
Data engineers love the fact that they can choose from dozens of different tools to solve a single problem. We’ve seen many online tutorials covering tools at the superficial level so learners end up knowing a bit of everything. But when it comes to job interviews, many candidates lack the necessary experience dealing with real data and therefore failed to pass. For example, a candidate may know spark dataframe syntax very well, but doesn’t know how to use the tool to process complex data joins and aggregations.
For many real-life data problems, the data skill is actually more important than the coding skill. That means the candidate needs to know different types of SQL functions and statements, knowing query performance tunings, as well as database internals. A data engineer will need to have the skills of joining 10 tables in one query, navigate complex entity relationships while maintaining the quality of code and correctness of the query output. To achieve this takes more than just learning the tools and syntax. It takes real hands-on project implementation experience. Different industries also have different types and shapes of data, ingested and stored in different ways, and processed with different business logics.
Industry experts recommend Python or Scala for data engineers. WeCloudData suggests learners to focus on one programming language, get good at it before moving on to another programming language. For learners from non-tech or DA/DS background, we recommend starting from Python first. For learners from CS and development background, picking up both Scala and Python shouldn’t be a big challenge.
Data Engineering Fundamentals
Let’s now dive into the details and discuss the important fundamental skills to grasp for data engineers.
SQL
SQL is the Structured Query Language that is used to interact with relational databases. It’s a common language shared by many different database engines. Different dialects exist but most of the SQL syntax look the same across different database engines.
SQL is probably THE most important tool to grasp as a data engineer. It’s probably even more important than Python in most of the DE roles.
Data engineers write SQL queries to retrieve data from databases, use SQL functions to transform data in the database, and use JOIN operations to merge data from different sources, and use GROUP BY operators to aggregate data and generate insights. Processing engines like Spark and traditional RDBMSs execute most ETL/ELT pipelines, which developers write in SQL.
Here’re some suggestions from WeCloudData on learning SQL:
- Get familiar with basic SQL functions such as JOIN, GROUP BY, etc.
- Go two steps deeper to learn SQL performance tuning and learn how to write optimized SQL code
- Learn advanced analytics functions
- Practice, practice, practice on datasets/tables with complex entity relationships (avoid working on problems that only have one table involved)
Python
Python is currently the king of data programming language. It’s always worth your effort to learn Python at an intermediate to advanced level. To get prepared for a data engineering career one should at least have intermediate level knowledge of python programming.
Important python skills to have
- Master the basic data types such as list, tuple, set, dictionary, string
- Master python functions and modules
- Have very solid understanding of Object-Oriented Programming and Python class.
Other python related knowledge to have:
- Project packaging
- Exception handling
- Logging
- Pytest or Unittest
Python data libraries to grasp
- Pandas dataframe
- SQLAlchemy (for database integration)
- PySpark (learn this in the big data section)
- Flask/FastAPI (basic knowledge is good enough)
Linux Commands
Linux is also an important skills a data engineer needs to be good at. There’s no need to become a Linux OS expert. Data engineers just need to know enough commands so that he/she can deal with AWS CLI, run python scripts and work with docker containers in the command line.
Some of the linux OS and commands to be familiar with include:
- Basic file system knowledge
- Navigating folders in linux
- Manage file permissions
- Move files around in linux
- Run scripts in linux with parameters
- Working with file editors in linux
- Download/upload files
- Basic CRON job knowledge
Git
Git and github are important skills a data engineer needs to grasp as well. Knowing how to version control scripts and pipeline DAGs is important because data engineers often collaborate with other engineers on building complex pipelines.
Some of the basic Git knowledge that are nice to have include:
- Basic push and pull/rebase
- Working with branches
- Create pull request and merge code
Cloud: AWS (or Azure, GCP)
While more and more companies are moving their data infrastructure to the cloud, AWS/GCP/Azure skills become indispensable. While data engineers don’t need to have the same level of knowledge as a cloud engineer, they need to have working experience of some of the data related cloud services very well.
One common questions WeCloudData get from students is which cloud platform should they invest time in. We think it doesn’t matter unless the company has very specific requirements for which cloud platform to use. Experience with one platform is pretty transferrable to other platforms so it shouldn’t take long for one to adapt to new platforms.
Keep in mind that most of the time data engineers are end users of cloud services. Big companies will have platform engineers or DevOps teams to set up data infrastructure so data engineer will focus on processing the data. However, in smaller organizations data engineers may need to roll up their sleeves and manage infrastructure as well.
Some of the AWS services we suggest aspiring data engineers to learn include:
- EC2 (Compute)
- Lambda (Compute/Serverless)
- S3 (Storage)
- RDS (Database/RDBMS)
- Redshift (data warehouse)
- Athena (Presto/distributed serverless queries)
- EMR (Managed Hadoop/Spark cluster)
- Kinesis (Distributed Messaging Queues)
- ECS/ECR (Container Registry and Service)
- Step Function (Pipelines)
At the beginning of your learning journey, you should probably only begin with EC2 and S3. As you go through the curriculum, you can pick up AWS services one by one. Learning under context is always more effective. For example, learn RDS when you start to embark on the database section and try to run your SQL database queries on a managed RDS instance.
Specialization
After you’ve learned the data engineering fundamentals, it’s time to move on to specialization topics. Currently, the data engineering field has a couple trends:
- Analytics engineering with modern data stack
- Big data engineering with data lake(house)
- Serverless data engineering
1. Analytics Engineering
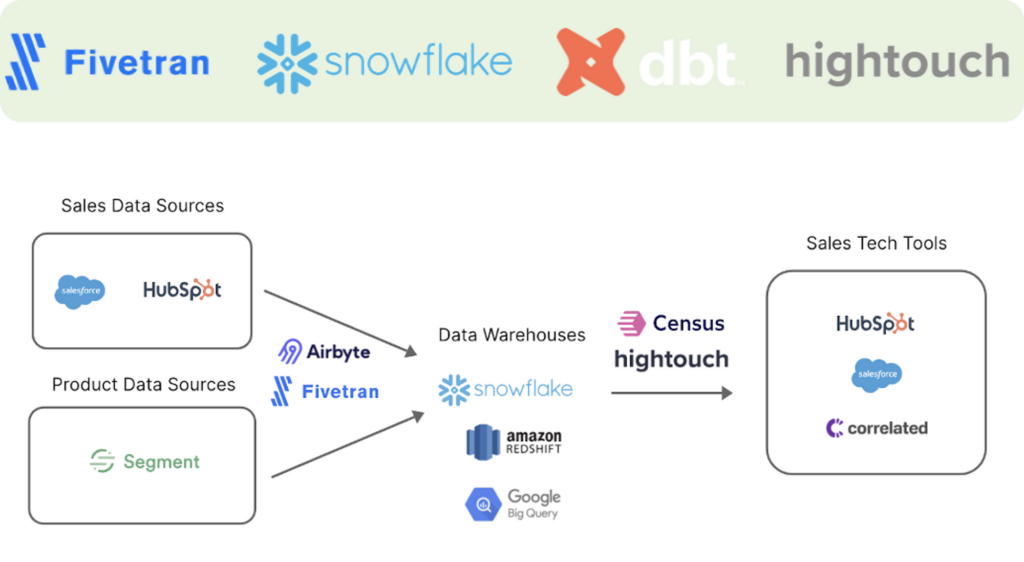
Analytics engineers mainly work with the modern data stack. SQL in recent years is having a big comeback. It’s partly driven by the innovation in the database world. For example, Snowflake data warehouse engine separates storage from compute and makes the cluster super easy to manage. The modern data ecosystem evolved around it and it’s quite common to see companies investing in similar tool stack:
- Fivetran for data ingestion
- dbt for data transformation
- Snowflake as data warehouse engine
- Hightouch for data activation and reverse ETL
To master the modern data stack as an analytics engineer, one needs to be familiar with the following concepts
Database
The modern data stack is mainly running on relational databases. More specifically, it favours data warehouses. However, databases such as Postgres can be used as well. A data engineer needs to be very familiar with relational databases such as MySQL, Postgres.
Some of the important database concepts to grasp include:
- Column-oriented vs Row-oriented databases
- Database partitioning and sharding
- Data modelling and Entity relationship
- Query plan and query optimization
Data Warehouse
Data warehouse is a complex system that centralizes a company’s important business data. It is primarily used for structured data but increasingly powered by modern database engines to store and analyze semi-structured and even unstructured data.
EDW is playing an essential role in enterprise business intelligence. Data from disparate sources are collected, transformed, and loaded into the warehouse for storage and queries. The way the data is modeled in the warehouse depends on how the business would like to query the data and therefore is critical for the performance and information access.
Modern data warehouse such as Bigquery and Snowflake separate storage from compute and thus making it very scalable. Instead of the traditional ETL and dimensional modelling approach, companies who follow the modern data stack also promotes ELT over ETL, which means transformation happens in the warehouse after data gets loaded in first.
Some of the important database concepts to grasp include:
- Dimensional modeling
- Incremental data loading
- Slowly changing dimensions
- Wide tables
- DBT data build tool
Data Connectors
Data engineers also need to understand how to work with different data sources. In modern data stack, platforms such as Apache Airbyte and Fivetran can be configured easily to connect to different data sources.
When data is not available via APIs or connectors, data engineers will be tasked to scrape data or write custom connectors. Writing custom connectors require basic sense of SDLC and code needs to be version controlled, tested, and maintained properly.
ELT with DBT
The modern data stack world is a pretty big believer of ELT (Extract-Load-Transform). Unlike the traditional ETL approach where data is transformed in specialized tools before loaded into the data warehouse. There’re a few advantages of ELT compared ETL:
- Data gets loaded into the destination warehouse faster
- No specialize ETL tool is required and T (transform) happens in data warehouse
- Data analysts are empowered and have more flexibility in terms of data transformation
Tools like DBT has become an essential tool in the modern BI. dbt is basically the T in ELT. It doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse.
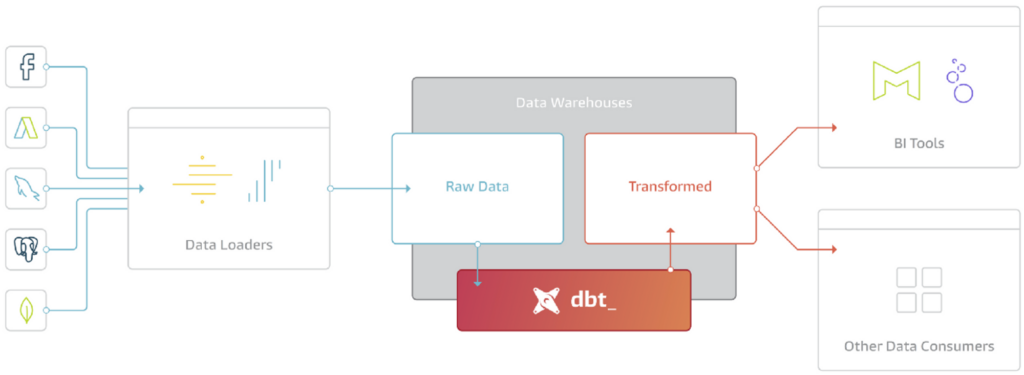
One of the main selling point of dbt is that it allows BI analysts to build complex data processing lineage and help manage the dependencies.

Data Modeling
How data is structured and stored inside the database is at the core of a data warehouse. There are different approaches and people also follow different schools of thoughts. There are two popular approaches in the modern data warehouse:
- Dimensional Modeling
- Kimball Dimensional Model / Star Schema
- Inmon Dimensional Model
- Wide Tables or OBT (One Big Table)
OBT is very popular and a preferred approach in the modern data stack. Many practitioners working with DBT would prefer building wide tables. The pros and cons of different approaches is worth a separate blog post. WeCloudData’s suggestion for analytics engineers is to spend more effort on learning and practicing data modelling and it will pay off!
2. Big Data Engineering
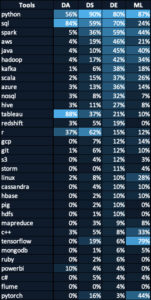
The table below compares the key stills among different data roles. As you will notice, Apache Spark (3rd row in this table) is very important skill for data engineers. This is because data engineers usually work with raw data that tends to be large-scale. The datasets used by data scientists are usually processed and trimmed down version.
Modern data engineers will definitely need to have big data skills under their belts. It is an imperative skill if one wants to work for big tech as a data engineer because you will most likely be dealing with massive data instead of the tiny million row tables. Yes, we’re talking about hundreds of billions and trillions of rows.
Of course, big data is not only associated with the word big. The 4 v’s of big data are:
- Volume
- Variety
- Velocity
- Value (you will certainly find different versions of this online)
Here’re some of the tech trends you need to keep in mind when you’re studying big data engineering.
Distributed System
Back in 2013/2014, Google published the Google File System and MapReduce paper. It led to the birth of the open source big data framework: Hadoop. At its core, Hadoop has a distributed file system HDFS and a distributed computation engine called MapReduce.
Hadoop, along with the NoSQL databases in its ecosystem have together led to the big data era. Numerous tools and companies were created and some are still growing as of today, such as Datastax, Databricks, Cloudera, etc.
Even though Hadoop is not the go-to big data platforms anymore in the modern cloud era, where AWS, GCP, Azure are the de-facto standards for scalable computing; and Apache Spark has also dethroned Hadoop MapReduce as the king of distributed processing engines; the concepts of distributed system and MapReduce are still very important foundational knowledge.
Suggestions for aspiring modern data engineers:
- You probably don’t need to learn how to set up a Hadoop cluster anymore
- Learn MapReduce concept is still important and apply it with other framework such as Spark or Flink.
Data Lake
Data lake is not just a specific tool. It contains the big data tools in the ecosystem but also increasingly become a process or philosophy of big data processing.
Most people will associate data lake with the storage layer. For example, Amazon S3 is commonly used as the object store for big data. S3 is powering images, videos, and files of many successful social media platforms such as Instagram, Tiktok, etc.
WeCloudData’s suggestion for learning data lake technologies are as follows:
- You not only need to know how to store big data, but also the right strategies to store it. For example
- What should be the data staging strategy in the data lake?
- How should we structure the folders and buckets?
- How do we protect the sensitive data via encryption and masking?
- What’s the best way to store metadata?
- Processing the big data in the data lake requires different tools. Hive, Presto, Spark are common tools used for big data processing.
Apache Spark
Spark is a distributed processing engine. It overtook Hadoop as one of the most popular engine. The commercial company Databricks has been widely successful in the industry. It started as a data processing tool and has since evolved into a one-size fit many type of unified analytics engine. Spark itself has an ecosystem that allows it to do many tasks such as ETL, streaming data analytics, machine learning and data science.
As a data engineer, Spark is definitely one of the most important skills to learn. Keep in mind that data engineers will need to learn Spark at a deeper level:
- Understand the Spark internals
- Know how to debug spark programs
- Gain hands-on experience tuning spark job performance
Common platforms that host Spark jobs include AWS’s Elastic MapReduce (EMR) service, Google Cloud’s Dataproc, Azure Databricks or Azure Synapse Analytics (Spark Pools), and Databrick’s Spark distribution. AWS Glue is also provides spark runtime in a serverless fashion.
Presto/TrinoDB/Athena
Facebook open sourced both Apache Hive and Presto. It has a large base of SQL users and realized the importance of bringing SQL into the distributed systems such as Hadoop.
Hive is still run at large tech companies and big banks. It has started to become a legacy big data system. But it’s still a very powerful tool. It’s successor Presto DB has become a very popular open source project. Unlike Hive, it is a extremely fast distributed SQL engine that allows BI analysts and data engineers to run federated queries.
The founders of Presto has since started TrinoDB and Amazon has also created its variation called Athena, which is a very popular AWS query service.
Streaming Data
Many big data applications require high velocity (low latency). When large number of events need to be processed in a very low-latency fashion, a distributed processing engine is usually required, such as Spark Streaming or Apache Flink. These tools usually consume data from a distributed messaging queue such as Apache Kafka. One of Kafka’s common use cases is relaying data among different systems and consumers pull data as topics from the message brokers. Kafka’s advantage is that it stores data on disks in the brokers for a given number of days and weeks so that it can replay the streams when necessary.
Data engineers don’t need to be the expert of configuring Kafka clusters, but knowing how to consume data from Kafka and how to ingest data into the Kafka queues can be very helpful.
Data Lakehouse
The Data lake technologies have been around for many years. However, it hasn’t fully delivered the promise of big data to many companies. For example, data lakes don’t support ACID transactions which is common is the database world. It’s also hard to combine batch and streaming jobs in data lake and therefore, data engineer always need to maintain separate pipelines for batch and real-time. Due to these limitations, companies such as Databricks, Netflix, and Uber have created Lakehouse architectures that try to solve these challenges. Common lakehouse architectures include:
- Delta Lake (Databricks)
- Hudi (Uber)
- Iceberg (Netflix)
The diagram below shows Uber’s 3rd-gen big data platform since 2017. Apache Hudi has played an important role in terms of allowing incremental big data ingestion. WeCloudData suggests aspiring data engineers to at least get familiar with the concepts of Lakehouse and try out Apache Hudi or Iceberg.
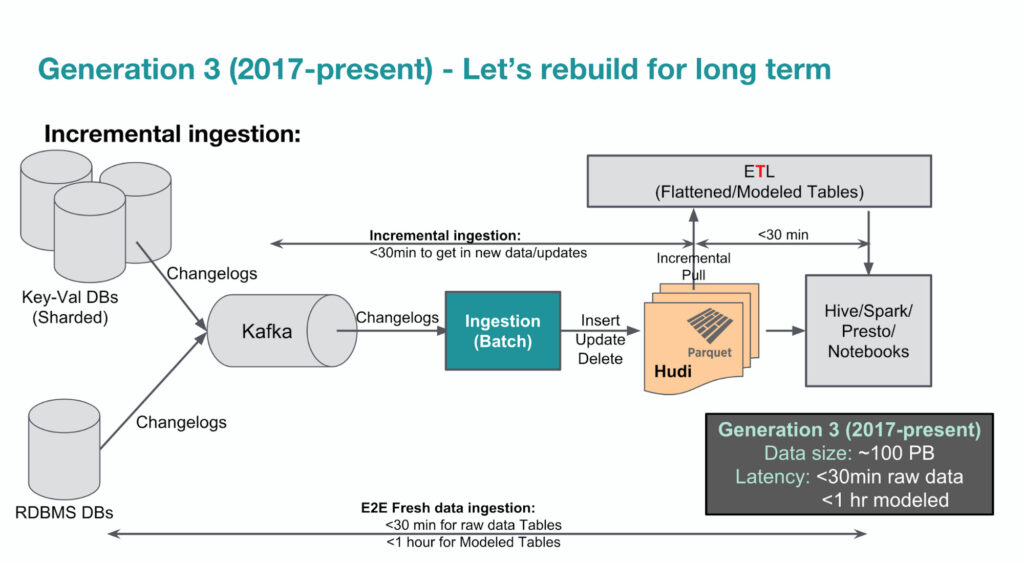
3. Data Integration & Pipelines
Companies are dealing with different types of data sources and in order to create powerful insights, data from different sources usually need to be integrated. ETL is playing an important role in data integration and data engineers will be writing data pipelines for complex transformations.
Apache Airflow | Dagster | Prefect
As a data engineer, being able to write automated data pipelines is a very crucial skillset. Apache Airflow is probably by far the most popular data pipeline and lineage tool in terms of community. It’s developed in Python and can be think of CRON on steroids. In recent years, projects such as Dagster and Prefect are also becoming quite popular and are even preferred by some companies.
WeCloudData’s suggestion for aspiring data engineers about data pipelines:
- Build an end-to-end data pipeline using Apache Airflow
- Read some articles about the pros and cons of Airflow vs Dagster vs Prefect.
4. Data Governance
Data governance is probably a relatively more alien topic for many beginner data engineers. It usually involves people, process, and technology. It will be hard to self-learn because you probably won’t get a good use case to apply it on your own. The story below can help you understand some of the pain points and why governance is needed.
The Data Governance Story
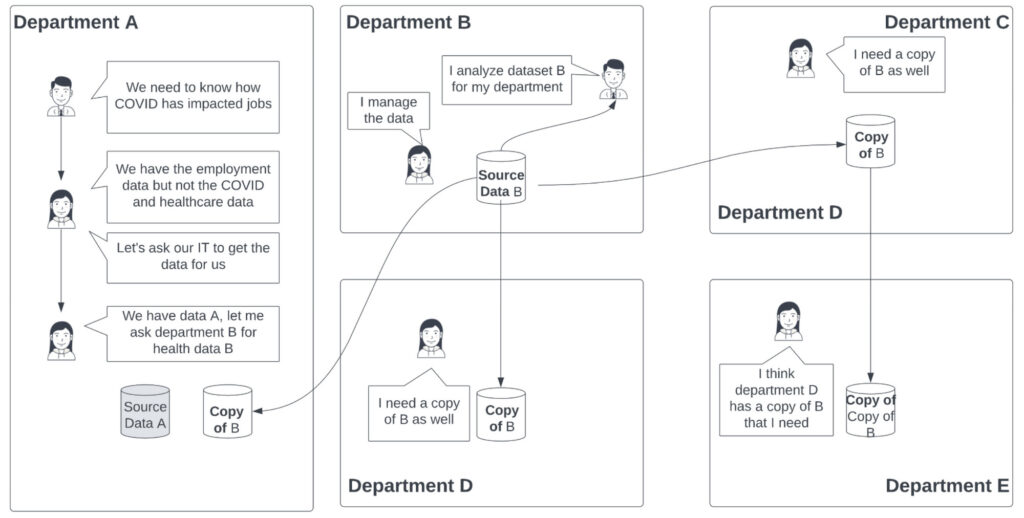
- Department B owns the data source B
- Department B collects and cleans data source B and use it for reporting and analytics purposes
- Department B is responsible for infrastructure security, privacy compliance, data quality.
- Department B gives department A access to the data
- Things are still manageable
- Soon department B’s data becomes popular and many departments want the data.
- Department E wants the same data and asks for a copy from Department C.
As you can see, things quickly become unmanageable.
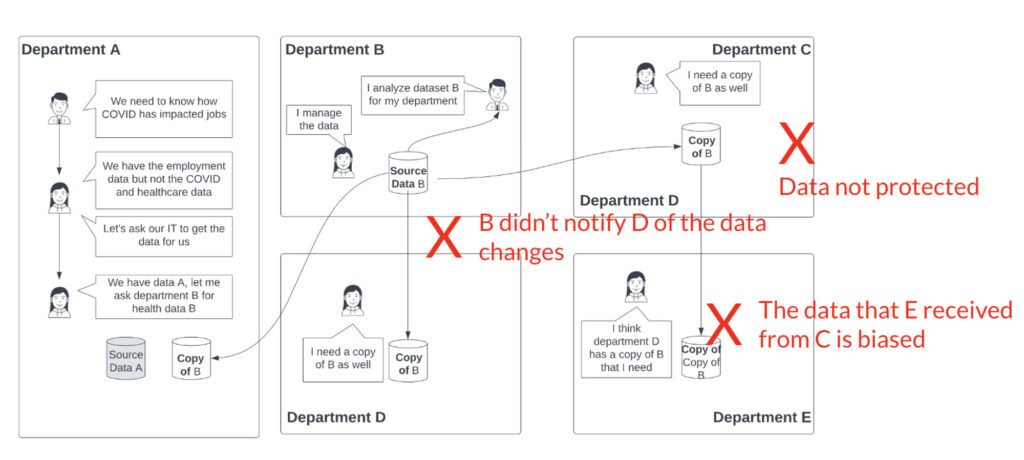
Some of the important aspects of data governance include:
- Privacy
- Security
- Bias
- Quality
WeCloudData’s suggestion for aspiring data engineers:
- Data governance may not seems very sexy but it’s definitely one of the most important in data engineering.
- Data engineers will need to understand the technology, policies, and best practices of data governance very well.
Data Governance Tools
- Amundsen
- Azure Purview
- AWS Glue, LakeFormation
Learning Guide for Career Switchers
Switch from Non-Tech to Data Engineer
Over the years WeCloudData has worked with many career switchers from non-tech background who successfully transitioned to data engineering. One common questions we receive from non-tech background professionals is how hard is it to switch to the data fields if one doesn’t come from coding and tech background.
Instead of giving a simple yes/or answer, we’d like to help everyone understand what type of challenges non-tech candidates will run into and what it takes to become a data engineer from scratch.
Challenges for non-tech switchers
- Learning curve
- Most learners who don’t come from tech background will go through a pretty steep learning curve.
- Even though Python and SQL might be easier to pick up for some, the learning curve will go up pretty quickly when learners are introduced to various tools, and this can be frustrating for many.
- Patience
- Learning new tools will always require good patience. Many learners will feel not making good process and therefore lose the momentum.
- Setting the right expectation upfront is very important. Talk to an advisor or mentor who’s more experienced and ask about their experiences.
- Begin with solving small challenges to keep yourself motivated
- Experience gap
- In the data engineer job market chapter, we shared that data engineers are usually expected to have more years of experience. Most non-tech switchers will have a disadvantage when it comes to experience
- The way you structure your resume and hands-on project implementation experience will be the key to success.
Recommendations for no-tech background learners
- Build relevant skills that are in-demand
- It’s very important to follow a structured learning path and build up your relevant skills
- We highly recommend you follow WeCloudData’s curriculum to learn data engineering
- Use project to fill the Experience gap
- Implementing end-to-end DE projects is the most effective way to close the experience gap.
- You need to work on projects that are industry-grade
- You need to showcase your experience dealing with different data engineering problems such as data collection, ingestion, pipelines, ETL/ELT, data warehouse, etc.
- Mentorship and career preparation is necessary
- Having instructors and mentors or even alumni who have been there will definitely help you save a lot of time and avoid going down the wrong path
- Mentors can help you scope out a more meaningful project
- Networking and referrals will be important for career switchers from non-tech background
Switch from IT to Data Engineer
Below we will introduce the learning path and focuses for career switchers from IT backgrounds. It doesn’t apply to every single cases so only use it as a generic guide.

Switch from Database Admin to Data Engineer
The rise of managed database services provided by AWS, GCP, Azure have reduced the need for database administrators. IT departments are cutting tech roles, directly impacting DBAs.
DBAs have very specialized knowledge about particular database technologies. They understand database internals and management really well. This is their advantage when it comes to job switch to DE. However, an important duty of a data engineer is data processing (ETL, integration) and most DBAs don’t really directly work on data processing.
WeCloudData’s suggestion for DBAs
- Switching to modern data stack might be a short path because you already know SQL well.
- Practice SQL and apply your data modelling experience to actual hands-on projects
- It’s still necessary to learn Python. It might be new to many DBAs but shouldn’t be hard for you to pick up
- Switching to Java/Scala might be more challenging if you haven’t done programming for many years. Begin with Python and learn PySpark and big data processing.
- Definitely learn how to set up cloud databases such as RDS and transfer your experience to the managed service world.
Switch from IT Support to Data Engineer
If you come from IT support background and have done much programming, WeCloudData would recommend the following path:
- Start from learning Python and SQL and make sure your programming skills are solid
- Learn one of the cloud platforms such as AWS, Azure. Cloud engineering could be another career path to pursue.
- Learn big data tools such as Spark
- Work on lots of mini-projects before working on big scope ones
- Learn scripting and automating data pipelines with Airflow
Switch from Traditional ETL to Data Engineer
If you come from ETL background, your background is very relevant. You’ve basically already been working as a data engineer. However, you may have been dealing with legacy or traditional ETL tools such as data stage, SSIS, or Informatica. You probably don’t do a lot of Spark programming.
WeCloudData’s suggestion for ETL developers
- Learn Python or Scala first
- Pick up one of the cloud platforms
- Equip yourself with Spark skills. Get ready for a modern DE role that requires more hands-on coding instead of low-code ETL tools
- Since you’ve already had years of experience with batch ETL jobs, try to learn Kafka and Spark Streaming so you’re open to real-time data processing ETL jobs
- Learn Lakehouse tools will be helpful so you’re well prepared for big data engineer jobs
Switch from Software Development to Data Engineer
Software developers in big tech may not get big salary jump when switching to data engineer jobs. However, there’s big demand for software engineers who can build data-intensive applications. So it’s not necessarily a career switch. Instead, it’s an up-skilling path.
Most software developers/engineers come from CS background and they have good experience with databases and SQL.
WeCloudData’s suggestion for SDEs switching to DE are as follows:
- Learn both Scala and Python (maybe you already know Python)
- Pick up one of the cloud platforms and learn to use data related services
- Learn how to build streaming applications using kafka, flink, and spark streaming
Switch from Platform & Infrastructure to Data Engineer
Platform engineers usually work with DevOps to deliver infrastructure for the data teams. Though they may be very familiar with different systems such as Spark, Hadoop, and Cloud, they usually don’t work closely with data.
WeCloudData’s suggestion for Platform/Infra engineers switching to DE:
- Try to leverage your cloud infrastructure experience and begin with building Serverless data applications
- For example, use Kinesis and Lambda to process data ingested in real-time
- Learn Spark and Spark SQL so you know how to process big data
- Learn the basics of data warehouse and dimensional modelling will be very helpful as well
- Depending on your interest, you can focus on either the modern data stack or the big data engineer route.
What are portfolio projects?
What are portfolio projects?
A portfolio is a collection of projects, code, document, and other things that can help you showcase your skills. These usually go beyond degrees and certifications and show practical skills that the candidates have obtained.
A decent portfolio project usually take more effort than most learners would expect. It’s more than just uploading your code to github. Data engineering projects are not as easy to demonstrate as compared to a data science project that has more visual components.
Below is a list of things aspiring data engineers can work on to strength their profile.
- Personal Projects
- Project summary
- Data pipeline architecture diagrams
- Data infrastructure configuration templates/scripts
- Working code and scripts (ETL/ELT scripts, pipeline DAGs, etc.)
- Github
- Code committed and pushed to your github branches that employers can look into
- Blogs
- Blog posts that document your learning journey and your views on the data engineering world. We suggest Medium/Substack as the blogging platform or WordPress. You can also set up your own Github pages.
WeCloudData’s suggestion
- Portfolio is extremely important because job search is usually a chicken and egg problem. It’s somewhat hard for applicants to show work related experiences without actually working in a DE role. Therefore, one of the best ways to showcase a career switcher’s background and skills is the project!
- Blog posts and Github can be used as great tools for networking and LinkedIn cold calling
- Portfolio projects not only demonstrate your skills but also show the hiring team how serious you’re and the level of effort you’ve put in
Building End-to-End DE Projects
Traditional data engineers in big companies may just need to focus on very specific tasks. For example, as an ETL specialist the DE may work with Informatica to transform and prepare data in the Informatica environment. The job market is increasingly looking for candidates who know more tools and design patterns. Especially in startups and tech companies that build their infrastructure on public clouds, data engineers have access to an abundant amount of tools and they either need to know how to work with a lot of those tools, or have to learn very quickly.
Therefore, WeCloudData suggests that when learning data engineering and building your portfolio projects, it’s very important to build projects that are end-to-end.
What does end-to-end project mean? An end-to-end project covers the entire data pipeline, from data collection, ingestion, to cleaning/transformation (ETL/ELT), loading into data lake/warehouse, and reverse ETL. It will be challenging to build something of this scope for a learner but try to build a pipeline that’s as complex and complete as possible.
Only showing code/scripts of processing data for ETL is not going to give candidates a huge advantage in the job search process.
Keep in mind that hiring managers always want to know the following:
- What problem are you trying to solve?
- What tools and platforms did you use?
- Why and how did you make some of the decisions on some tools and approaches
- What benefits did you approach have? Was it trying to optimizing the speed, or lowering the infrastructure cost, or improving the reliability?
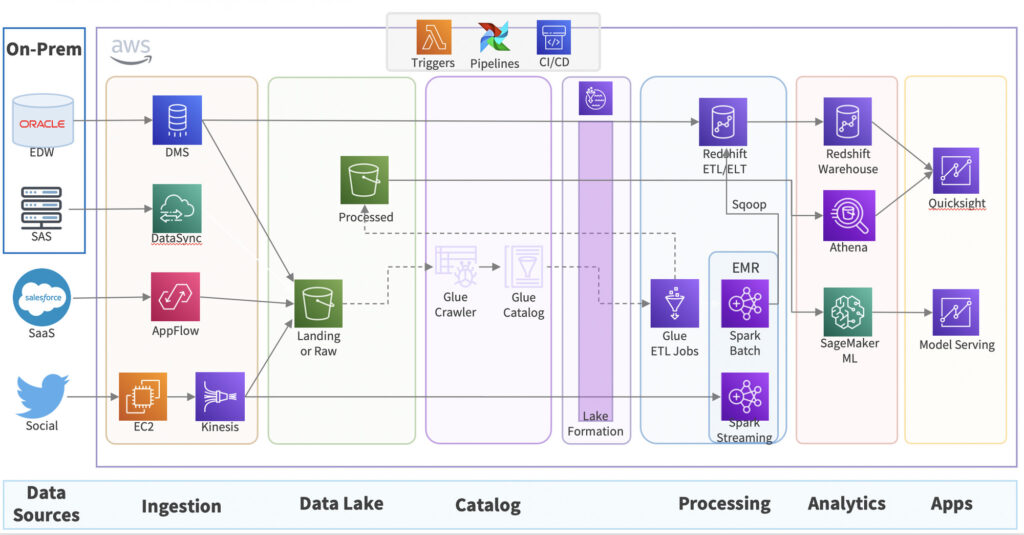
Importance of Data Architecture and Demo
It’s very hard to explain the data pipeline and the best way is to create your pipeline diagram. Data engineers need to know how to work with diagraming tools such as draw.io or lucidchart to design pipeline/data architectures. It doesn’t have to be the most professional looking diagram but some key components need to be articulated. This will help the hiring managers understand what you did and leave a very strong impression. It can also be used as a potential tool during an interview for you to walk the hiring managers and senior data engineers through your project.
Things to include on a DE project diagram
- Data sources
- Data destinations
- Data store (databases, data warehouse, or data lake)
- Data ingestion process (CDC, Kafka, or airbyte/fivetran, etc.)
- Staging vs production zones
- Critical logics in your pipelines
- Automation workflow
- Environment/Infrastructure (AWS, Kubernetes, Spark Clusters, etc.)
- Analytics output if possible (BI dashboards)
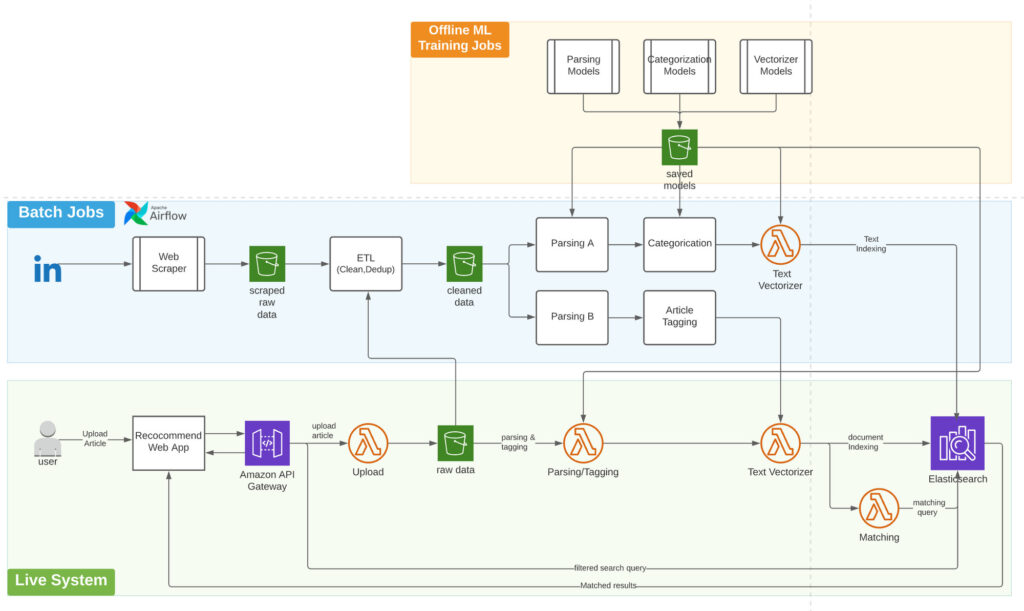
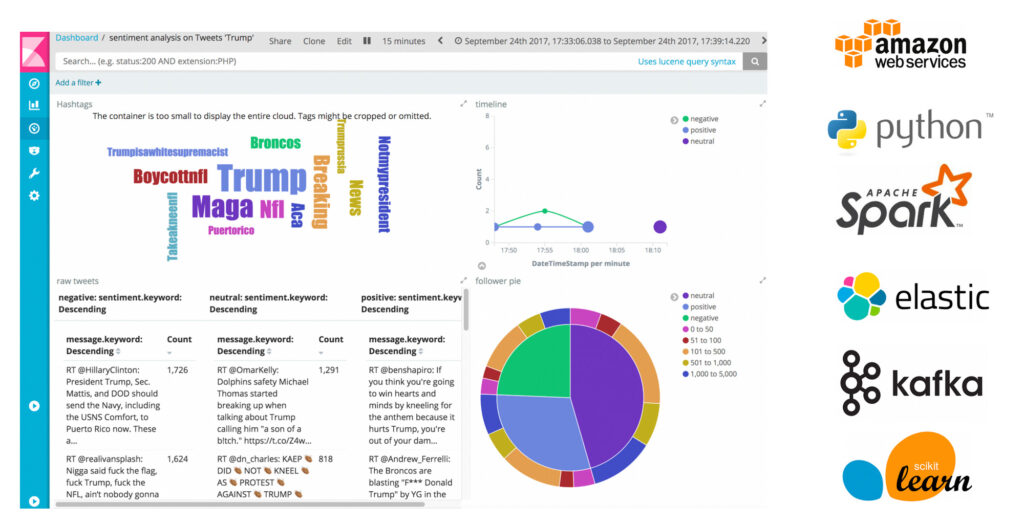
Importance of real project experience
Nothing beats real hands-on experience! Hiring managers will always prefer to hire someone who has real experiences. Real experience doesn’t mean work experience, it could be self-guided projects, freelance projects, or some kind of real project experience working with clients.
In this section, we will discuss why having real project experience can help you stand out easily. Here’re some of the benefits of real client projects:
- You will gain experience working with real companies and clients so your work can be articulated in interviews and helps you build more credibility
- You will get more interviews because of the real experience
- You will be able to negotiate for higher starting salary
- For career switchers, real projects help you close the experience gap.
Let’s try to understand the important factors in hiring decisions:
- Hiring managers want to hire someone who has the right skills
- Hiring managers want to hire someone who has good track record so they have more certainty in the hiring decision
- Hiring managers want to hire someone who is at lower risks
- It’s not about how MANY tools a candidate knows
- It’s not about how MANY years of experience a candidate has
- It’s more about experience which is related to problem solving skills
For career switchers coming from non-data and non-tech background, your past work experience doesn’t carry much weight and often times creates disadvantages. It’s pretty easy for hiring managers to make biased assumptions that you’re not a good fit without even looking into your skills and capabilities. Working on real client projects means the work you do will carry more weight on your resume and help build more trust. Employers will have more confidence when they are deciding among different candidates. You will also learn things that you don’t have the opportunities to practice yourself:
- Project scoping and requirements gathering
- Business communications
- Task prioritization
- Debugging, solving technical challenges, handling messy situations, and learning from mistakes
- Associating your work with measurable business values
Understanding how real-life projects work
Here’s a sample data warehousing project workflow.
A project team is creating a modern data warehouse in the Azure cloud. The project managers, data engineers, IT/platform engineers need to work together to make the following things happen for the company/client:
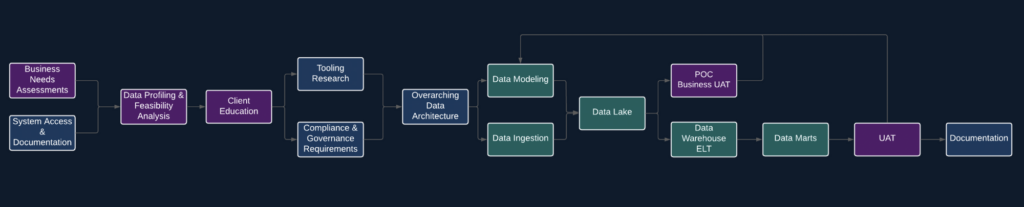
- Understand the business needs of a data warehouse
- Get IT infrastructure access sorted out
- Perform data profiling and assess the feasibility/scope of the work involved
- Decide the tools/platforms to use for the data warehouse project
- Work with compliance team to make sure best practices are followed
- Design the overarching data architecture
- Create the data models (dimension models, wide tables, etc.)
- Ingest the data from different sources to the data lake or staging database
- Write ELT/ETL scripts to materialize the tables in data warehouse
- Run UAT sessions with the business users along the way
- Create wide tables and data marts and build dashboards for final UAT and approval
- Document the entire process for the company/client
Sample Data Engineering Portfolio Projects
Do know where to get started from? Get some inspiration from WeCloudData students/alumni. You can find some project demos on our youtube channel: https://youtube.com/@weclouddata
