
The Importance of a Structured Curriculum
If you do some research on Google regarding top skills of a data engineer, you will be surprised to see how many skills a data engineer needs to know! Based on WeCloudData’s research (analysis done on thousands of job postings), top skills that appear most frequently on data engineer job descriptions are:
- Python
- SQL
- Spark
- AWS
- Hadoop
- Java/Scala
- Kafka
- NoSQL
- Hive
- Snowflake
- etc.
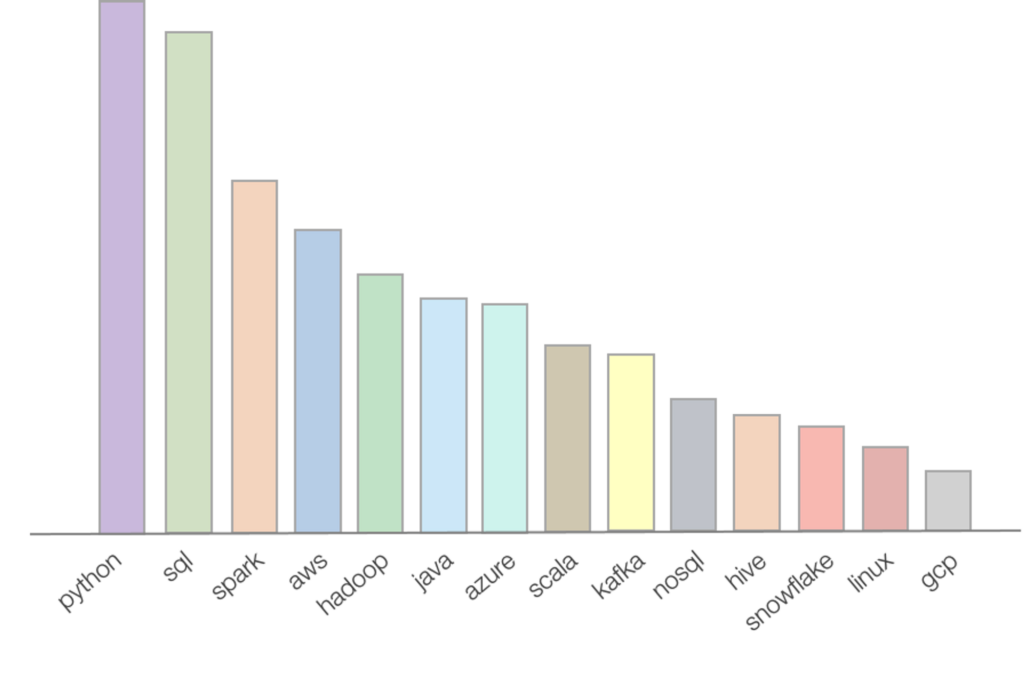
The actual list is quite long and for beginners that can look quite daunting. To make the matter worse, these tools cover different aspects of data engineering and it’s rare to have someone learn everything. It usually takes years of working on different types of DE projects to achieve that.
One of the mistakes frequently made by learners is chasing the tools. Warning ahead! Tools are just tools and one should not learn them for the sake of learning. Listing 30+ tools on the resume is going to cause more harm than good.
The best way to learn data engineering is to follow a structured curriculum. WeCloudData’s data engineering bootcamp has open sourced its curriculum. In this guide, we will discuss it in detail.
Following a structured curriculum has the following benefits:
- A structured curriculum can help the learners focus on learning the skills that are relevant and important
- A structured curriculum will tell the learners what’s important at each stage of learning and what can be learned later
- A structured curriculum will help the learners stay focused and get less distracted
- A structured curriculum can help the learners achieve their goals faster
- A structured curriculum with solid instructional design can help the learners become a more effective learner and grasp the concepts faster than self-paced learning
- A structured curriculum provides hands-on projects and exercises that can help the learners practice and reinforce the concepts
Here’s a list of topics that WeCloudData’s data engineering bootcamp covers:
- Programming (taught as part of the pre-bootcamp)
- Data Infrastructure & Cloud Computing
- Data Warehouse
- Big Data and Distributed Systems
- ETL & Data Integration
- Data Lake(house)
- Data Pipeline and Orchestration
- CI/CD for Data Engineers
- Data Governance
- Project Management
The Importance of Fundamentals
Before jumping into advanced topics of data engineering such as distributed systems, ETL, and streaming data processing, it’s important to have the fundamental building blocks of data engineering developed. For any data jobs, SQL and Python are always the most important skills to grasp. For data engineers in particular, linux commands and git are also key skills to learn.
One interesting thing about data engineering is that there are so many different tools that can be applied to solve the same problem. We’ve seen many online tutorials covering tools at the superficial level so learners end up knowing a bit of everything. But when it comes to job interviews, many candidates lack the necessary experience dealing with real data and therefore failed to pass. For example, a candidate may know spark dataframe syntax very well, but doesn’t know how to use the tool to process complex data joins and aggregations.
For many real-life data problems, the data skill is actually more important than the coding skill. That means the candidate needs to know different types of SQL functions and statements, knowing query performance tunings, as well as database internals. A data engineer will need to have the skills of joining 10 tables in one query, navigate complex entity relationships while maintaining the quality of code and correctness of the query output. To achieve this takes more than just learning the tools and syntax. It takes real hands-on project implementation experience. Different industries also have different types and shapes of data, ingested and stored in different ways, and processed with different business logics.
From a programming tool perspective, Python or Scala are recommended for data engineers. WeCloudData suggests learners to focus on one programming language, get good at it before moving on to another programming language. For learners from non-tech or DA/DS background, we recommend starting from Python first. For learners from CS and development background, picking up both Scala and Python shouldn’t be a big challenge.
Data Engineering Fundamentals
Let’s now dive into the details and discuss the important fundamental skills to grasp for data engineers.
SQL
SQL is the Structured Query Language that is used to interact with relational databases. It’s a common language shared by many different database engines. Different dialects exist but most of the SQL syntax look the same across different database engines.
SQL is probably THE most important tool to grasp as a data engineer. It’s probably even more important than Python in most of the DE roles.
Data engineers write SQL queries to retrieve data from databases, use SQL functions to transform data in the database, and use JOIN operations to merge data from different sources, and use GROUP BY operators to aggregate data and generate insights. Most of the ETL/ELT pipelines are written in SQL and executed in RDBMS or other processing engines like Spark.
Here’re some suggestions from WeCloudData on learning SQL:
- Get familiar with basic SQL functions such as JOIN, GROUP BY, etc.
- Go two steps deeper to learn SQL performance tuning and learn how to write optimized SQL code
- Learn advanced analytics functions
- Practice, practice, practice on datasets/tables with complex entity relationships (avoid working on problems that only have one table involved)
Python
Python is currently the king of data programming language. It’s always worth your effort to learn Python at an intermediate to advanced level. To get prepared for a data engineering career one should at least have intermediate level knowledge of python programming.
Important python skills to have
- Master the basic data types such as list, tuple, set, dictionary, string
- Master python functions and modules
- Have very solid understanding of Object-Oriented Programming and Python class.
Other python related knowledge to have:
- Project packaging
- Exception handling
- Logging
- Pytest or Unittest
Python data libraries to grasp
- Pandas dataframe
- SQLAlchemy (for database integration)
- PySpark (learn this in the big data section)
- Flask/FastAPI (basic knowledge is good enough)
Linux Commands
Linux is also an important skills a data engineer needs to be good at. There’s no need to become a Linux OS expert. Data engineers just need to know enough commands so that he/she can deal with AWS CLI, run python scripts and work with docker containers in the command line.
Some of the linux OS and commands to be familiar with include:
- Basic file system knowledge
- Navigating folders in linux
- Manage file permissions
- Move files around in linux
- Run scripts in linux with parameters
- Working with file editors in linux
- Download/upload files
- Basic CRON job knowledge
Git
Git and github are important skills a data engineer needs to grasp as well. Knowing how to version control scripts and pipeline DAGs is important because data engineers often collaborate with other engineers on building complex pipelines.
Some of the basic Git knowledge that are nice to have include:
- Basic push and pull/rebase
- Working with branches
- Create pull request and merge code
Cloud: AWS (or Azure, GCP)
While more and more companies are moving their data infrastructure to the cloud, AWS/GCP/Azure skills become indispensable. While data engineers don’t need to have the same level of knowledge as a cloud engineer, they need to have working experience of some of the data related cloud services very well.
One common questions WeCloudData get from students is which cloud platform should they invest time in. We think it doesn’t matter unless the company has very specific requirements for which cloud platform to use. Experience with one platform is pretty transferrable to other platforms so it shouldn’t take long for one to adapt to new platforms.
Keep in mind that most of the time data engineers are end users of cloud services. Big companies will have platform engineers or DevOps teams to set up data infrastructure so data engineer will focus on processing the data. However, in smaller organizations data engineers may need to roll up their sleeves and manage infrastructure as well.
Some of the AWS services we suggest aspiring data engineers to learn include:
- EC2 (Compute)
- Lambda (Compute/Serverless)
- S3 (Storage)
- RDS (Database/RDBMS)
- Redshift (data warehouse)
- Athena (Presto/distributed serverless queries)
- EMR (Managed Hadoop/Spark cluster)
- Kinesis (Distributed Messaging Queues)
- ECS/ECR (Container Registry and Service)
- Step Function (Pipelines)
At the beginning of your learning journey, you should probably only begin with EC2 and S3. As you go through the curriculum, you can pick up AWS services one by one. Learning under context is always more effective. For example, learn RDS when you start to embark on the database section and try to run your SQL database queries on a managed RDS instance.
Specialization
After you’ve learned the data engineering fundamentals, it’s time to move on to specialization topics. Currently, the data engineering field has a couple trends:
- Analytics engineering with modern data stack
- Big data engineering with data lake(house)
- Serverless data engineering
1. Analytics Engineering
Analytics engineers mainly work with the modern data stack. SQL in recent years is having a big comeback. It’s partly driven by the innovation in the database world. For example, Snowflake data warehouse engine separates storage from compute and makes the cluster super easy to manage. The modern data ecosystem evolved around it and it’s quite common to see companies investing in similar tool stack:
- Fivetran for data ingestion
- dbt for data transformation
- Snowflake as data warehouse engine
- Hightouch for data activation and reverse ETL
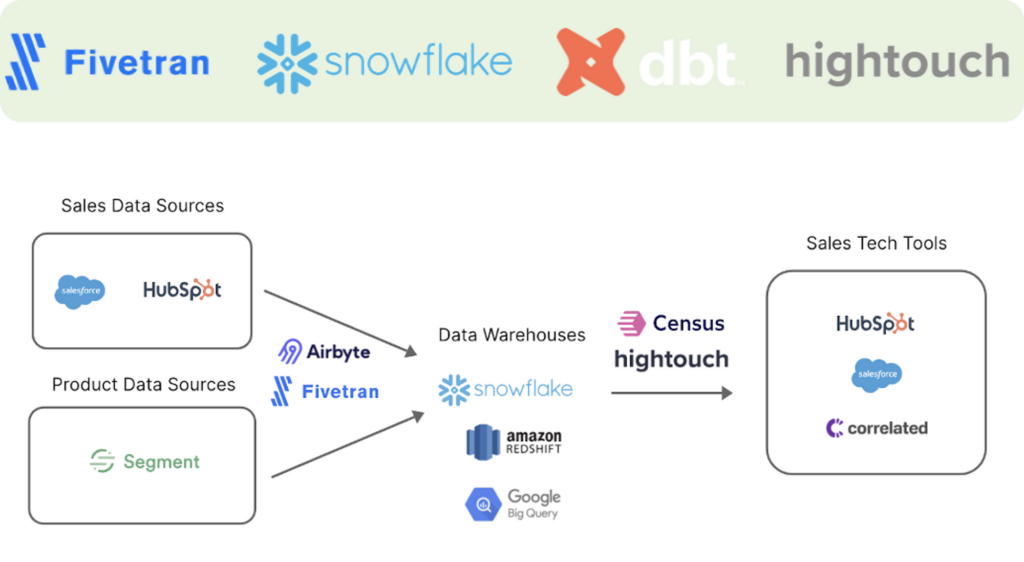
To master the modern data stack as an analytics engineer, one needs to be familiar with the following concepts
Database
The modern data stack is mainly running on relational databases. More specifically, it favours data warehouses. However, databases such as Postgres can be used as well. A data engineer needs to be very familiar with relational databases such as MySQL, Postgres.
Some of the important database concepts to grasp include:
- Column-oriented vs Row-oriented databases
- Database partitioning and sharding
- Data modelling and Entity relationship
- Query plan and query optimization
Data Warehouse
Data warehouse is a complex system that centralizes a company’s important business data. It is primarily used for structured data but increasingly powered by modern database engines to store and analyze semi-structured and even unstructured data.
EDW is playing an essential role in enterprise business intelligence. Data from disparate sources are collected, transformed, and loaded into the warehouse for storage and queries. The way the data is modeled in the warehouse depends on how the business would like to query the data and therefore is critical for the performance and information access.
Modern data warehouse such as Bigquery and Snowflake separate storage from compute and thus making it very scalable. Instead of the traditional ETL and dimensional modelling approach, companies who follow the modern data stack also promotes ELT over ETL, which means transformation happens in the warehouse after data gets loaded in first.
Some of the important database concepts to grasp include:
- Dimensional modeling
- Incremental data loading
- Slowly changing dimensions
- Wide tables
- DBT data build tool
Data Connectors
Data engineers also need to understand how to work with different data sources. In modern data stack, platforms such as Apache Airbyte and Fivetran can be configured easily to connect to different data sources.
When data is not available via APIs or connectors, data engineers will be tasked to scrape data or write custom connectors. Writing custom connectors require basic sense of SDLC and code needs to be version controlled, tested, and maintained properly.
ELT with DBT
The modern data stack world is a pretty big believer of ELT (Extract-Load-Transform). Unlike the traditional ETL approach where data is transformed in specialized tools before loaded into the data warehouse. There’re a few advantages of ELT compared ETL:
- Data gets loaded into the destination warehouse faster
- No specialize ETL tool is required and T (transform) happens in data warehouse
- Data analysts are empowered and have more flexibility in terms of data transformation
Tools like DBT has become an essential tool in the modern BI. dbt is basically the T in ELT. It doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse.
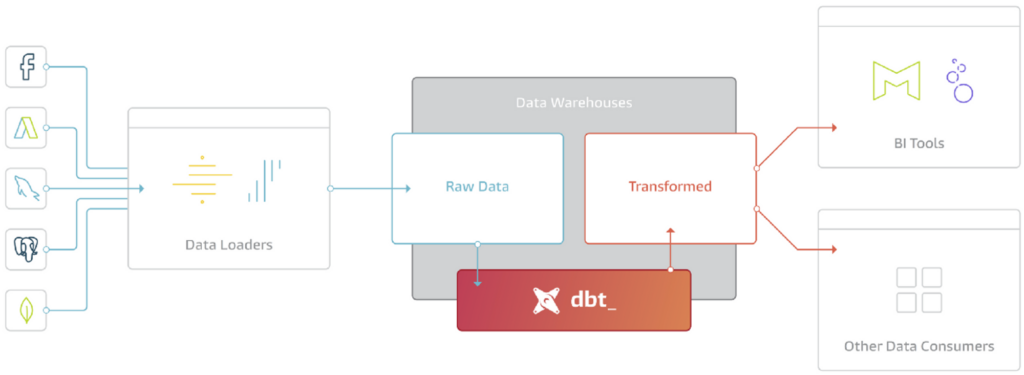
One of the main selling point of dbt is that it allows BI analysts to build complex data processing lineage and help manage the dependencies.

Data Modeling
How data is structured and stored inside the database is at the core of a data warehouse. There are different approaches and people also follow different schools of thoughts. There are two popular approaches in the modern data warehouse:
- Dimensional Modeling
- Kimball Dimensional Model / Star Schema
- Inmon Dimensional Model
- Wide Tables or OBT (One Big Table)
OBT is very popular and a preferred approach in the modern data stack. Many practitioners working with DBT would prefer building wide tables. The pros and cons of different approaches is worth a separate blog post. WeCloudData’s suggestion for analytics engineers is to spend more effort on learning and practicing data modelling and it will pay off!
2. Big Data Engineering
The table below compares the key stills among different data roles. As you will notice, Apache Spark (3rd row in this table) is very important skill for data engineers. This is because data engineers usually work with raw data that tends to be large-scale. The datasets used by data scientists are usually processed and trimmed down version.
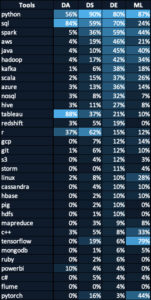
Modern data engineers will definitely need to have big data skills under their belts. It is an imperative skill if one wants to work for big tech as a data engineer because you will most likely be dealing with massive data instead of the tiny million row tables. Yes, we’re talking about hundreds of billions and trillions of rows.
Of course, big data is not only associated with the word big. The 4 v’s of big data are:
- Volume
- Variety
- Velocity
- Value (you will certainly find different versions of this online)
Here’re some of the tech trends you need to keep in mind when you’re studying big data engineering.
Distributed System
Back in 2013/2014, Google published the Google File System and MapReduce paper. It led to the birth of the open source big data framework: Hadoop. At its core, Hadoop has a distributed file system HDFS and a distributed computation engine called MapReduce.
Hadoop, along with the NoSQL databases in its ecosystem have together led to the big data era. Numerous tools and companies were created and some are still growing as of today, such as Datastax, Databricks, Cloudera, etc.
Even though Hadoop is not the go-to big data platforms anymore in the modern cloud era, where AWS, GCP, Azure are the de-facto standards for scalable computing; and Apache Spark has also dethroned Hadoop MapReduce as the king of distributed processing engines; the concepts of distributed system and MapReduce are still very important foundational knowledge.
Suggestions for aspiring modern data engineers:
- You probably don’t need to learn how to set up a Hadoop cluster anymore
- Learn MapReduce concept is still important and apply it with other framework such as Spark or Flink.
Data Lake
Data lake is not just a specific tool. It contains the big data tools in the ecosystem but also increasingly become a process or philosophy of big data processing.
Most people will associate data lake with the storage layer. For example, Amazon S3 is commonly used as the object store for big data. S3 is powering images, videos, and files of many successful social media platforms such as Instagram, Tiktok, etc.
WeCloudData’s suggestion for learning data lake technologies are as follows:
- You not only need to know how to store big data, but also the right strategies to store it. For example
- What should be the data staging strategy in the data lake?
- How should we structure the folders and buckets?
- How do we protect the sensitive data via encryption and masking?
- What’s the best way to store metadata?
- Processing the big data in the data lake requires different tools. Hive, Presto, Spark are common tools used for big data processing.
Apache Spark
Spark is a distributed processing engine. It overtook Hadoop as one of the most popular engine. The commercial company Databricks has been widely successful in the industry. It started as a data processing tool and has since evolved into a one-size fit many type of unified analytics engine. Spark itself has an ecosystem that allows it to do many tasks such as ETL, streaming data analytics, machine learning and data science.
As a data engineer, Spark is definitely one of the most important skills to learn. Keep in mind that data engineers will need to learn Spark at a deeper level:
- Understand the Spark internals
- Know how to debug spark programs
- Gain hands-on experience tuning spark job performance
Common platforms that host Spark jobs include AWS’s Elastic MapReduce (EMR) service, Google Cloud’s Dataproc, Azure Databricks or Azure Synapse Analytics (Spark Pools), and Databrick’s Spark distribution. AWS Glue is also provides spark runtime in a serverless fashion.
Presto/TrinoDB/Athena
Facebook open sourced both Apache Hive and Presto. It has a large base of SQL users and realized the importance of bringing SQL into the distributed systems such as Hadoop.
Hive is still run at large tech companies and big banks. It has started to become a legacy big data system. But it’s still a very powerful tool. It’s successor Presto DB has become a very popular open source project. Unlike Hive, it is a extremely fast distributed SQL engine that allows BI analysts and data engineers to run federated queries.
The founders of Presto has since started TrinoDB and Amazon has also created its variation called Athena, which is a very popular AWS query service.
Streaming Data
Many big data applications require high velocity (low latency). When large number of events need to be processed in a very low-latency fashion, a distributed processing engine is usually required, such as Spark Streaming or Apache Flink. These tools usually consume data from a distributed messaging queue such as Apache Kafka. One of Kafka’s common use cases is relaying data among different systems and consumers pull data as topics from the message brokers. Kafka’s advantage is that it stores data on disks in the brokers for a given number of days and weeks so that it can replay the streams when necessary.
Data engineers don’t need to be the expert of configuring Kafka clusters, but knowing how to consume data from Kafka and how to ingest data into the Kafka queues can be very helpful.
Data Lakehouse
Data lake technologies have been around for many years. However, it hasn’t fully delivered the promise of big data to many companies. For example, data lakes don’t support ACID transactions which is common is the database world. It’s also hard to combine batch and streaming jobs in data lake and therefore, data engineer always need to maintain separate pipelines for batch and real-time. Due to these limitations, companies such as Databricks, Netflix, and Uber have created Lakehouse architectures that try to solve these challenges. Common lakehouse architectures include:
- Delta Lake (Databricks)
- Hudi (Uber)
- Iceberg (Netflix)
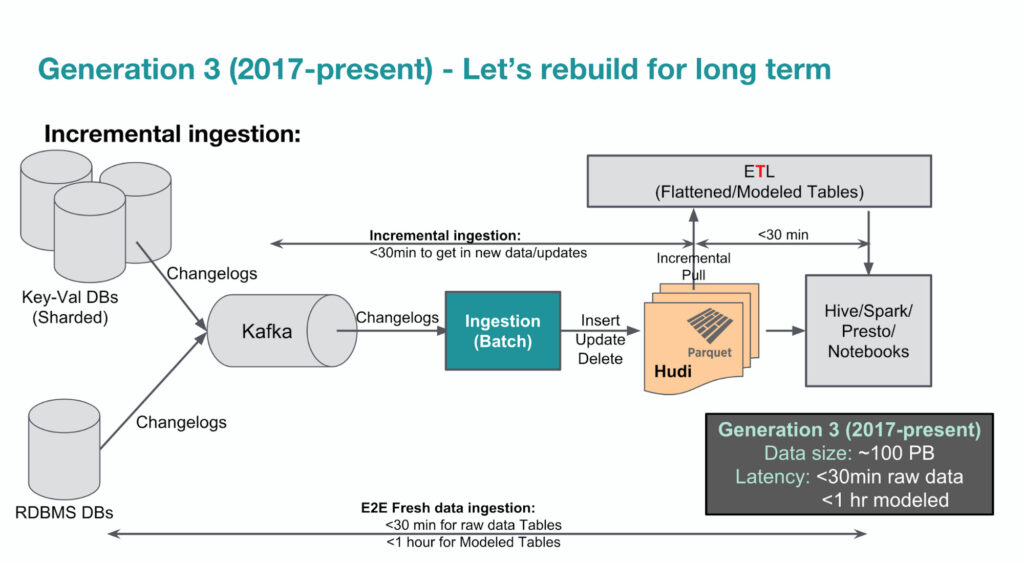
The diagram below shows Uber’s 3rd-gen big data platform since 2017. Apache Hudi has played an important role in terms of allowing incremental big data ingestion. WeCloudData suggests aspiring data engineers to at least get familiar with the concepts of Lakehouse and try out Apache Hudi or Iceberg.
3. Data Integration & Pipelines
Companies are dealing with different types of data sources and in order to create powerful insights, data from different sources usually need to be integrated. ETL is playing an important role in data integration and data engineers will be writing data pipelines for complex transformations.
Apache Airflow | Dagster | Prefect
As a data engineer, being able to write automated data pipelines is a very crucial skillset. Apache Airflow is probably by far the most popular data pipeline and lineage tool in terms of community. It’s developed in Python and can be think of CRON on steroids. In recent years, projects such as Dagster and Prefect are also becoming quite popular and are even preferred by some companies.
WeCloudData’s suggestion for aspiring data engineers about data pipelines:
- Build an end-to-end data pipeline using Apache Airflow
- Read some articles about the pros and cons of Airflow vs Dagster vs Prefect.
4. Data Governance
Data governance is probably a relatively more alien topic for many beginner data engineers. It usually involves people, process, and technology. It will be hard to self-learn because you probably won’t get a good use case to apply it on your own. The story below can help you understand some of the pain points and why governance is needed.
The Data Governance Story
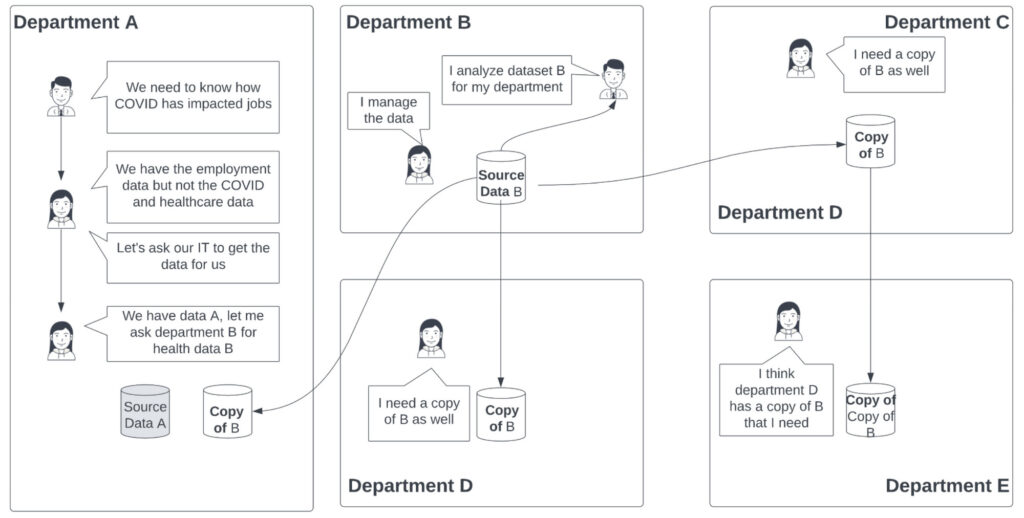
- Department B owns the data source B
- Department B collects and cleans data source B and use it for reporting and analytics purposes
- Department B is responsible for infrastructure security, privacy compliance, data quality.
- Department B gives department A access to the data
- Things are still manageable
- Soon department B’s data becomes popular and many departments want the data.
- Department E wants the same data and asks for a copy from Department C.
As you can see, things quickly become unmanageable.
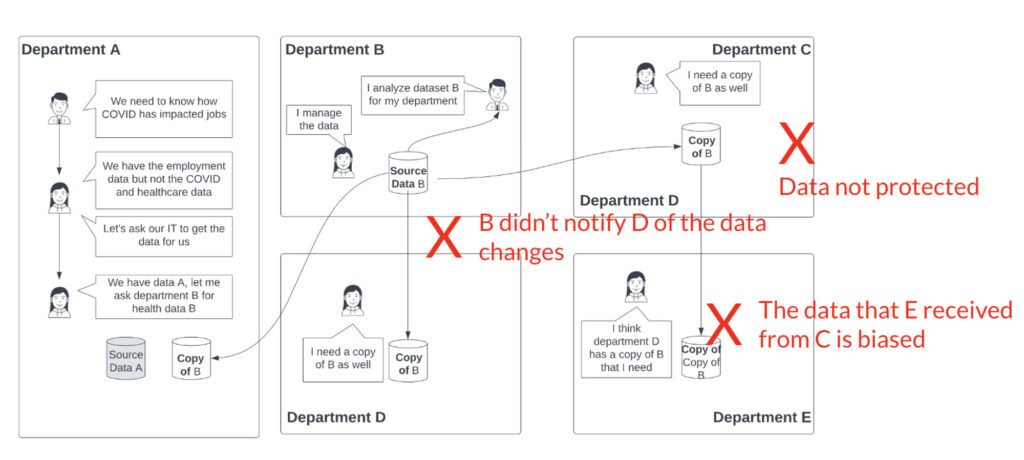
Some of the important aspects of data governance include:
- Privacy
- Security
- Bias
- Quality
WeCloudData’s suggestion for aspiring data engineers:
- Data governance may not seems very sexy but it’s definitely one of the most important in data engineering.
- Data engineers will need to understand the technology, policies, and best practices of data governance very well.
Data Governance Tools
- Amundsen
- Azure Purview
- AWS Glue, LakeFormation
Learning Guide for Career Switchers
Switch from Non-Tech to Data Engineer
Over the years WeCloudData has worked with many career switchers from non-tech background who successfully transitioned to data engineering. One common questions we receive from non-tech background professionals is how hard is it to switch to the data fields if one doesn’t come from coding and tech background.
Instead of giving a simple yes/or answer, we’d like to help everyone understand what type of challenges non-tech candidates will run into and what it takes to become a data engineer from scratch.
Challenges for non-tech switchers
- Learning curve
- Most learners who don’t come from tech background will go through a pretty steep learning curve.
- Even though Python and SQL might be easier to pick up for some, the learning curve will go up pretty quickly when learners are introduced to various tools, and this can be frustrating for many.
- Patience
- Learning new tools will always require good patience. Many learners will feel not making good process and therefore lose the momentum.
- Setting the right expectation upfront is very important. Talk to an advisor or mentor who’s more experienced and ask about their experiences.
- Begin with solving small challenges to keep yourself motivated
- Experience gap
- In the data engineer job market chapter, we shared that data engineers are usually expected to have more years of experience. Most non-tech switchers will have a disadvantage when it comes to experience
- The way you structure your resume and hands-on project implementation experience will be the key to success.
Recommendations for no-tech background learners
- Build relevant skills that are in-demand
- It’s very important to follow a structured learning path and build up your relevant skills
- We highly recommend you follow WeCloudData’s curriculum to learn data engineering
- Use project to fill the Experience gap
- Implementing end-to-end DE projects is the most effective way to close the experience gap.
- You need to work on projects that are industry-grade
- You need to showcase your experience dealing with different data engineering problems such as data collection, ingestion, pipelines, ETL/ELT, data warehouse, etc.
- Mentorship and career preparation is necessary
- Having instructors and mentors or even alumni who have been there will definitely help you save a lot of time and avoid going down the wrong path
- Mentors can help you scope out a more meaningful project
- Networking and referrals will be important for career switchers from non-tech background
Switch from IT to Data Engineer
Below we will introduce the learning path and focuses for career switchers from IT backgrounds. It doesn’t apply to every single cases so only use it as a generic guide.

Switch from Database Admin to Data Engineer
The rise of managed database services provided by AWS, GCP, Azure have reduced the need for database administrators. IT departments have been cutting their IT roles and DBAs are among those who are impacted.
DBAs have very specialized knowledge about particular database technologies. They understand database internals and management really well. This is their advantage when it comes to job switch to DE. However, an important duty of a data engineer is data processing (ETL, integration) and most DBAs don’t really directly work on data processing.
WeCloudData’s suggestion for DBAs
- Switching to modern data stack might be a short path because you already know SQL well.
- Practice SQL and apply your data modelling experience to actual hands-on projects
- It’s still necessary to learn Python. It might be new to many DBAs but shouldn’t be hard for you to pick up
- Switching to Java/Scala might be more challenging if you haven’t done programming for many years. Begin with Python and learn PySpark and big data processing.
- Definitely learn how to set up cloud databases such as RDS and transfer your experience to the managed service world.
Switch from IT Support to Data Engineer
If you come from IT support background and have done much programming, WeCloudData would recommend the following path:
- Start from learning Python and SQL and make sure your programming skills are solid
- Learn one of the cloud platforms such as AWS, Azure. Cloud engineering could be another career path to pursue.
- Learn big data tools such as Spark
- Work on lots of mini-projects before working on big scope ones
- Learn scripting and automating data pipelines with Airflow
Switch from Traditional ETL to Data Engineer
If you come from ETL background, your background is very relevant. You’ve basically already been working as a data engineer. However, you may have been dealing with legacy or traditional ETL tools such as data stage, SSIS, or Informatica. You probably don’t do a lot of Spark programming.
WeCloudData’s suggestion for ETL developers
- Learn Python or Scala first
- Pick up one of the cloud platforms
- Equip yourself with Spark skills. Get ready for a modern DE role that requires more hands-on coding instead of low-code ETL tools
- Since you’ve already had years of experience with batch ETL jobs, try to learn Kafka and Spark Streaming so you’re open to real-time data processing ETL jobs
- Learn Lakehouse tools will be helpful so you’re well prepared for big data engineer jobs
Switch from Software Development to Data Engineer
Software developers in big tech may not get big salary jump when switching to data engineer jobs. However, there’s big demand for software engineers who can build data-intensive applications. So it’s not necessarily a career switch. Instead, it’s an up-skilling path.
Most software developers/engineers come from CS background and they have good experience with databases and SQL.
WeCloudData’s suggestion for SDEs switching to DE are as follows:
- Learn both Scala and Python (maybe you already know Python)
- Pick up one of the cloud platforms and learn to use data related services
- Learn how to build streaming applications using kafka, flink, and spark streaming
Switch from Platform & Infrastructure to Data Engineer
Platform engineers usually work with DevOps to deliver infrastructure for the data teams. Though they may be very familiar with different systems such as Spark, Hadoop, and Cloud, they usually don’t work closely with data.
WeCloudData’s suggestion for Platform/Infra engineers switching to DE:
- Try to leverage your cloud infrastructure experience and begin with building Serverless data applications
- For example, use Kinesis and Lambda to process data ingested in real-time
- Learn Spark and Spark SQL so you know how to process big data
- Learn the basics of data warehouse and dimensional modelling will be very helpful as well
- Depending on your interest, you can focus on either the modern data stack or the big data engineer route.