Best Programming Language for MLOps?

MLOps (Machine Learning Operations) has quickly become one of the most in-demand fields in tech. As more organizations scale their AI initiatives, the need for professionals who can build, deploy, and maintain machine learning models in production is skyrocketing. But here’s the question many aspiring engineers ask: What’s the best programming language for MLOps? The […]
Beginner Friendly DevOps Transformation Roadmap for 2025
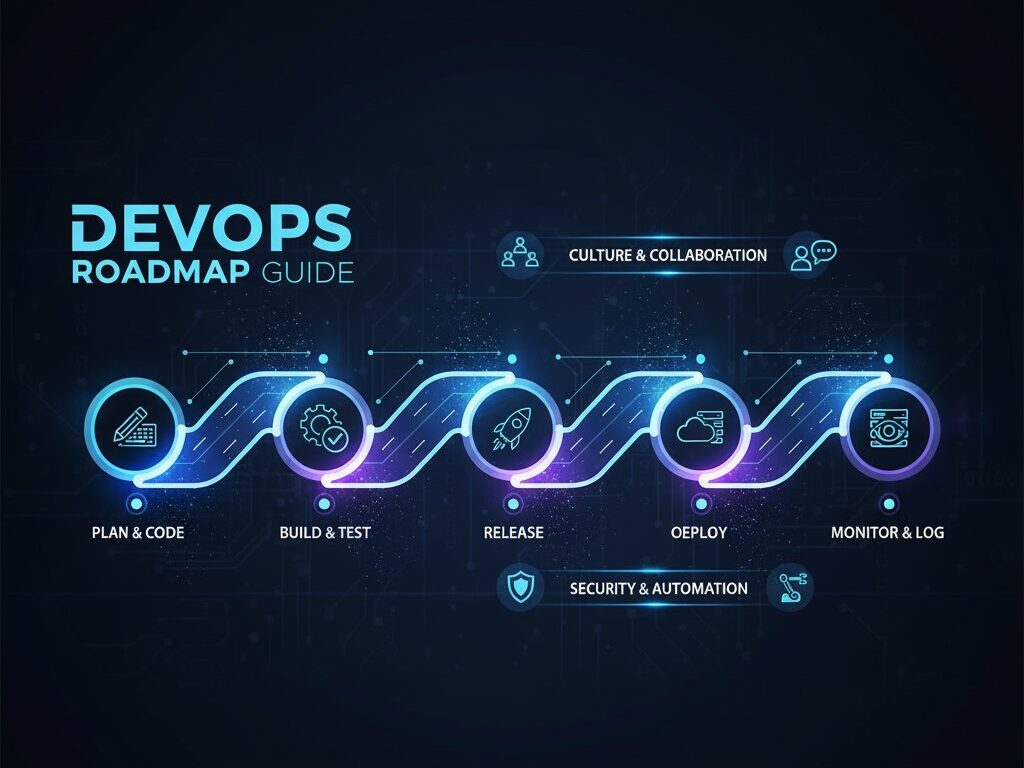
What is DevOps? If you’ve been exploring career paths in technology, you’ve probably asked yourself: What is DevOps? Simply put, DevOps is a set of practices, tools, and a cultural philosophy that brings together software development (Dev) and IT operations (Ops). The goal is to shorten the software development lifecycle, deliver features faster, and improve […]
Cloud Storage

Our digital lives would be much different without cloud storage, which makes it easy to share, access, and protect data across platforms and devices. The cloud market has huge potential and is continuously evolving with the advancement in technology and time. This blog highlights cloud storage mechanisms, cost models, trends, service providers, and the benefits […]
Cloud Engineer

Cloud computing has become the backbone of modern digital infrastructure, revolutionizing business operations. As organizations rapidly adopt cloud technologies, there is an increasing demand for skilled cloud professionals. Whether you are curious about cloud computing, looking for cloud computing courses, or an enthusiastic tech professional, this quick cloud engineer roadmap blog covers everything you need […]
Smart Agriculture: How Machine Learning is Helping Farming

Discover how machine learning is revolutionizing smart agriculture, enhancing crop yields, optimizing resources, and making farming more sustainable. Learn about the latest technologies and trends in agriculture.
Hybrid Cloud

Hybrid cloud computing is a type of cloud computing that combines the benefits of both private and public clouds. It has emerged as a pivotal strategy for organizations aiming to balance scalability, agility, and control. The hybrid cloud empowers businesses to optimize performance, enhance security, and drive innovation. This blog explores the current landscape of […]
Cloud Governance

Cloud computing is the foundation of modern infrastructure and technology. With the growing shift toward the cloud, the challenges of managing security, compliance, costs, and operational efficiency are also increasing. Cloud Governance provides the framework for effective, secure, and compliant cloud environments while maximizing the benefits of cloud computing. This blog gives you a brief […]
Private Cloud

A private or enterprise cloud is the type of cloud computing in which all the resources are dedicated to a single tenant. Private cloud allows organizations a high level of cloud computing benefits such as scalability, flexibility, access control, and faster service delivery. This blog explores the fundamentals of the private cloud framework. Let’s learn […]
Public Cloud

A public cloud is a type of cloud computing in which a third-party service provider provides computing resources via the internet. The computing resources are accessible to multiple tenants, sharing the same public internet. Public cloud frameworks offer cost-efficiency and scalability along with other benefits to organizations. This blog explores the public cloud framework, key […]
Fraud Detection in the Banking Industry: Leveraging Machine Learning for Credit Card Fraud Detection

Machine Learning revolutionizes fraud detection in the banking industry. Explore advanced algorithms shaping the future of credit card fraud detection for enhanced security and proactive risk management.
More Accurate Predictions for Your Day: Machine Learning in Weather Forecasting

Weather forecasting is a complex science that involves analyzing vast amounts of data from various sources, including satellites, weather stations, and radar systems.
Consulting Case Study: Real-time Data Streaming Pipeline Optimization

Background Our client is providing advanced agriculture tools and digital information to farmers to become more profitable. The company utilizes sensor solutions and provides real-time and actionable insights. It also provides farmers with the power to control their operating costs. Their product is a solution that saves farms over $20,000 annually by improving energy efficiency […]
Consulting Case Study: Job Market Analysis

Executive Summary WeCloudData is one of the fastest growing Data & AI training companies in the world. Since 2016, WeCloudData has trained and helped thousands of students and clients level up their data skills and mature their data organizations. Understanding the job market is a central business need for many organizations and for all HR […]
Data Visualisation in Einstein Analytics using Stack Over Flow data from Redshift.

The blog is posted by WeCloudData’s student Sneha Mehrin. This Article Outlines the Key Steps in Creating a Highly Interactive Dashboard in Einstein Analytics by Connecting to Redshift. image from https://www.searchenginejournal.com/ This article is a part of the series and continuation from the previous article where we build a data warehouse in Redshift to store the streamed and processed […]
Creating a Data Warehouse Using Amazon Redshift for StackOverflow Data

The blog is posted by WeCloudData’s student Sneha Mehrin. Steps to Create a Data Warehouse and Automate the Process of Loading Pre-Processed Data Using Pyspark Script in Emr image from https://scpolicycouncil.org/ This article is part of the series and continuation of the previous post where we processed the streamed data using spark on EMR. Why use Redshift? Redshift is […]
Data Processing Stack Overflow Data Using Apache Spark on AWS EMR

The blog is posted by WeCloudData’s student Sneha Mehrin. An overview on how to process data in spark using DataBricks, add the script as a step in AWS EMR and output the data to Amazon Redshift This article is part of the series and continuation of the previous post. In the previous post, we saw how we can […]
How to Build a Technical Design Architecture for an Analytics Data Pipeline

The blog is posted by WeCloudData’s student Sneha Mehrin. An Overview of Designing & Building a Technical Architecture for an Analytics Data Pipeline Problem. This article is a continuation of the previous post and will outline how to transform our user requirements into a technical design and architecture. Let’s summarise our two major requirements: Let’s […]
Build Real-Time Dashboard on Amazon Webservices

The blog is posted by WeCloudData’s student Luis Vieira. I will be showing how to build a real-time dashboard on Amazon Webservices for two different use cases, and a registry of open data from New York City Taxi and Limousine Commission (TLC) Trip Record Data. By the end you should have a Kibana Dashboard as following: […]
Data Analysis on Twitter Data Using DynamoDB and Hive

The blog is posted by WeCloudData’s student Amany Abdelhalim. There are two steps that I followed to create this pipeline : 1) Collect Twitter Feeds and Ingest into DynamoDB 2) Copy the Twitter Data from DynamoDB to Hive First: Collect Twitter Feeds and Ingest into DynamoDB In order to create a pipeline where I collect tweets on a […]
Live Twitter Sentiment Analysis

The blog is posted by WeCloudData’s Big Data course student Udayan Maurya. This Live Twitter Sentiment Analyzer helps track present sentiment for a given track word. In this document, I will describe the work flow I followed to develop this SaaS app. Contents Data Pipeline Map Data Collection Preparing Data for Data Analysis Training the […]