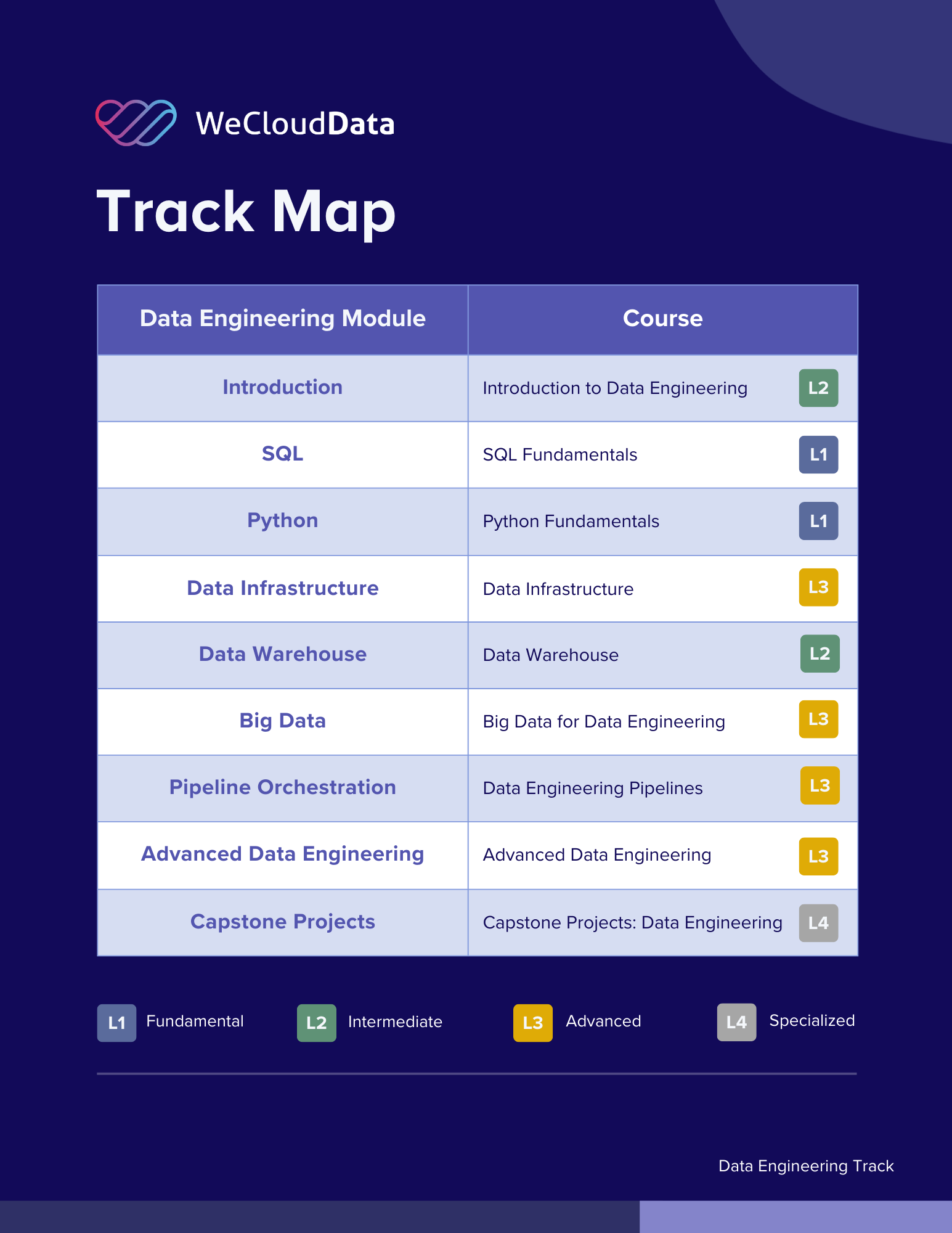
Introduction to Data Engineering
Intermediate
By the end of this course, participants will be able to:
- Define the role and core responsibilities of a data engineer and distinguish it from related roles.
- Describe the end-to-end lifecycle of a data engineering project.
- Identify key tools, systems, and architectural patterns used in data engineering workflows.
- Understand the principles of scalable and maintainable data architecture.




















