Data Engineering Series #2: Cloud Services and FOSS in Data Engineer’s World
Data Engineering Series #1: 10 Key tech skills you need, to become a competent Data Engineer. Data Engineering Series #2: Cloud Services and FOSS in Data Engineer’s world “Open Source (OSS) frameworks have improved the quality of Big Data processing with its diverse set of tools addressing numerous use cases In fact, if you are a […]
Data Engineering Series #1: 10 Key Tech Skills You Need, to Become a Competent Data Engineer.
Bridging the gap between Application Developers and Data Scientists, the demand for Data Engineers rose up to 50% in 2020, especially due to increase in investments on AI based SaaS products. After going through multiple Job Descriptions and based on my experience in the field , I have come up with the detailed skill sets to […]
Data Visualisation in Einstein Analytics using Stack Over Flow data from Redshift.

The blog is posted by WeCloudData’s student Sneha Mehrin. This Article Outlines the Key Steps in Creating a Highly Interactive Dashboard in Einstein Analytics by Connecting to Redshift. image from https://www.searchenginejournal.com/ This article is a part of the series and continuation from the previous article where we build a data warehouse in Redshift to store the streamed and processed […]
Creating a Data Warehouse Using Amazon Redshift for StackOverflow Data

The blog is posted by WeCloudData’s student Sneha Mehrin. Steps to Create a Data Warehouse and Automate the Process of Loading Pre-Processed Data Using Pyspark Script in Emr image from https://scpolicycouncil.org/ This article is part of the series and continuation of the previous post where we processed the streamed data using spark on EMR. Why use Redshift? Redshift is […]
Data Processing Stack Overflow Data Using Apache Spark on AWS EMR

The blog is posted by WeCloudData’s student Sneha Mehrin. An overview on how to process data in spark using DataBricks, add the script as a step in AWS EMR and output the data to Amazon Redshift This article is part of the series and continuation of the previous post. In the previous post, we saw how we can […]
Streaming Stack Overflow Data Using Kinesis Firehose

The blog is posted by WeCloudData’s student Sneha Mehrin. Overview on how to ingest stack overflow data using Kinesis Firehose and Boto3 and store in S3 This article is a part of the series and continuation of the previous post. Why using Streaming data ingestion? Traditional enterprises follow a methodology of batch processing where you […]
How to Build a Technical Design Architecture for an Analytics Data Pipeline

The blog is posted by WeCloudData’s student Sneha Mehrin. An Overview of Designing & Building a Technical Architecture for an Analytics Data Pipeline Problem. This article is a continuation of the previous post and will outline how to transform our user requirements into a technical design and architecture. Let’s summarise our two major requirements: Let’s […]
Build Real-Time Dashboard on Amazon Webservices

The blog is posted by WeCloudData’s student Luis Vieira. I will be showing how to build a real-time dashboard on Amazon Webservices for two different use cases, and a registry of open data from New York City Taxi and Limousine Commission (TLC) Trip Record Data. By the end you should have a Kibana Dashboard as following: […]
Preprocessing Criteo Dataset for Prediction of Click Through Rate on Ads

The blog is posted by WeCloudData’s student Amany Abdelhalim. In this post, I will be taking you through the steps that I performed to preprocess the Criteo Data set. Some Aspects to Consider when Preprocessing the Data Criteo data set is an online advertising dataset released by Criteo Labs. It contains feature values and click feedback […]
Building an End to End Analytics Pipeline Using Einstein Analytics, Kinesis, Spark and Redshift.

The blog is posted by WeCloudData’s student Sneha Mehrin. If you are a computer programmer or working in any tech-related industry, then chances are that, at least once a day google for answers in Stack Overflow. Stack Overflow is a question and answer site for professional and enthusiast programmers. The website offers a platform for […]
An Introduction To Spark and Its Behavior.

The blog is posted by WeCloudData’s Big Data course student Abhilash Mohapatra. Checklist Followed: Mapreduce, Hadoop and Spark. Spark Architecture. Spark in Cluster. Predicate Pushdown, Broadcasting and Accumulators. 1. Mapreduce, Hadoop and Spark For this section, let the below table represents data stored in S3 which is to be processed. Below table represents the Map and Shuffle […]
Looking to Upskill During the Pandemic? Here’s What Bootcamp Grads Have to Say on COVID-19 Experience
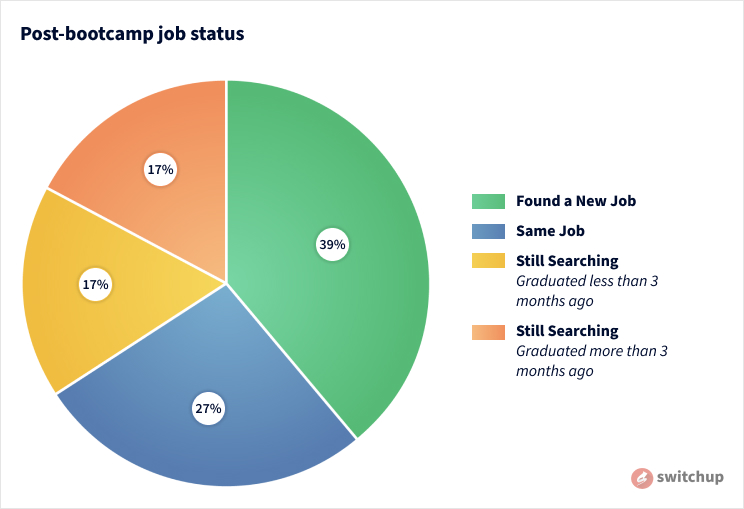
The newest article by Taylor Nichols on switchup shows that the move to online was more popular than people thought it would be. Turns out change can bring new opportunities and be great! Last Updated: September 21, 2020 Click on the link below and check out the article for yourself! https://www.prweb.com/releases/switchups_new_coding_bootcamp_rankings_offer_chance_to_boost_skills_and_career_opportunities_during_pandemic/prweb17413105.htm Key Insights Remote tools and […]
Data Analysis on Twitter Data Using DynamoDB and Hive

The blog is posted by WeCloudData’s student Amany Abdelhalim. There are two steps that I followed to create this pipeline : 1) Collect Twitter Feeds and Ingest into DynamoDB 2) Copy the Twitter Data from DynamoDB to Hive First: Collect Twitter Feeds and Ingest into DynamoDB In order to create a pipeline where I collect tweets on a […]
Analyzing Kinesis Data Streams of Tweets Using Kinesis Data Analytics

The blog is posted by WeCloudData’s student Amany Abdelhalim. In this article, I am illustrating how to collect tweets into a kinesis data stream and then analyze the tweets using kinesis data analytics.</p></p> The steps that I followed: Create a kinesis data stream. I created a kinesis data stream which I called “twitter” with one […]
Embarrassingly Parallel Model Training on Spark — Pandas UDF

The blog is posted by WeCloudData’s Big Data course student Udayan Maurya. Spark is one of the most popular tool to perform map-reduce tasks efficiently on large scale distributed data-sets. Additionally, Spark comes with MLlib package to perform Machine Learning on distributed data. On the flip side Python has very mature libraries: Numpy, Pandas, Scikit-Learn, […]
An Introduction to Big Data & ML Pipeline in AWS

The blog is posted by WeCloudData’s Big Data course student Abhilash Mohapatra. This story represents an easy path for below items in AWS : Build an Big Data Pipeline for both Static and Streaming Data. Process Data in Apache Hadoop using Hive. Load processed data to Data Warehouse solution like Redshift and RDS like MySQL. […]
An Introduction to Data Pipeline with Spark in AWS

The blog is posted by WeCloudData’s Big Data course student Abhilash Mohapatra. This story represents an easy path to Transform Data using PySpark. Along with Transformation, Spark Memory Management is also taken care. Here Freddie-Mac Acquisition and Performance Data from year 1999–2018 is used to create a Single o/p file which can further be used for Data Analysis or Building Machine […]
Building Data Pipeline in AWS for Retail Data
The blog is posted by WeCloudData’s Data Engineering course student Rupal Bhatt. Here is a Donut Chart prepared from processed data. Our data passes through several processes before meeting a dashboard and giving us a full picture like the one above. This is an attempt to show you one way of processing such data. Big […]
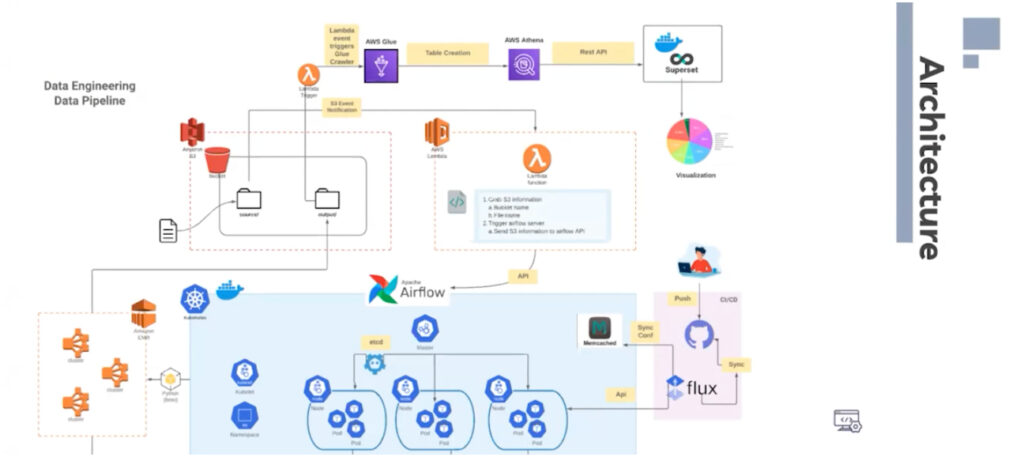
Building Superset Dashboard and Pipeline using Apache Airflow and Google Cloud SQL

The blog is posted by WeCloudData’s Data Science Bootcamp student Ryan Kang. Like Amazon AWS, Google Cloud is a popular cloud used by data analytics companies. Google Cloud allows continuous automation of workflow and big data computation. In this blog, I will briefly introduce how I set up Google Cloud for workflow and Superset dashboard […]
Interview with Shaohua Zhang, Data Scientist and CEO of WeCloudData – by Reena Shaw

This is a repost of Reena Shaw’s interview with our CEO published on Medium. Thanks, Reena (Linkedin Medium) for doing this interview! During my interviews with various data scientists, Shaohua Zhang is someone who struck me as unique for two reasons: 1) his incredible commitment and generosity to share his experience, and 2) his transition […]