Python Fundamentals

Career Switch from Accountant to Data Scientist with WeCloudData

The blog is posted by WeCloudData’s full-time data science diploma program student Yining Zhuang. In this blog, I would like to share my experience with people who are thinking of changing their career path from business to data science. I hope my journey can encourage people who are struggling in their current position, and help […]
Data Visualisation in Einstein Analytics using Stack Over Flow data from Redshift.

The blog is posted by WeCloudData’s student Sneha Mehrin. This Article Outlines the Key Steps in Creating a Highly Interactive Dashboard in Einstein Analytics by Connecting to Redshift. image from https://www.searchenginejournal.com/ This article is a part of the series and continuation from the previous article where we build a data warehouse in Redshift to store the streamed and processed […]
Data Processing Stack Overflow Data Using Apache Spark on AWS EMR

The blog is posted by WeCloudData’s student Sneha Mehrin. An overview on how to process data in spark using DataBricks, add the script as a step in AWS EMR and output the data to Amazon Redshift This article is part of the series and continuation of the previous post. In the previous post, we saw how we can […]
Streaming Stack Overflow Data Using Kinesis Firehose

The blog is posted by WeCloudData’s student Sneha Mehrin. Overview on how to ingest stack overflow data using Kinesis Firehose and Boto3 and store in S3 This article is a part of the series and continuation of the previous post. Why using Streaming data ingestion? Traditional enterprises follow a methodology of batch processing where you […]
How to Build a Technical Design Architecture for an Analytics Data Pipeline

The blog is posted by WeCloudData’s student Sneha Mehrin. An Overview of Designing & Building a Technical Architecture for an Analytics Data Pipeline Problem. This article is a continuation of the previous post and will outline how to transform our user requirements into a technical design and architecture. Let’s summarise our two major requirements: Let’s […]
Build Real-Time Dashboard on Amazon Webservices

The blog is posted by WeCloudData’s student Luis Vieira. I will be showing how to build a real-time dashboard on Amazon Webservices for two different use cases, and a registry of open data from New York City Taxi and Limousine Commission (TLC) Trip Record Data. By the end you should have a Kibana Dashboard as following: […]
Preprocessing Criteo Dataset for Prediction of Click Through Rate on Ads

The blog is posted by WeCloudData’s student Amany Abdelhalim. In this post, I will be taking you through the steps that I performed to preprocess the Criteo Data set. Some Aspects to Consider when Preprocessing the Data Criteo data set is an online advertising dataset released by Criteo Labs. It contains feature values and click feedback […]
Building an End to End Analytics Pipeline Using Einstein Analytics, Kinesis, Spark and Redshift.

The blog is posted by WeCloudData’s student Sneha Mehrin. If you are a computer programmer or working in any tech-related industry, then chances are that, at least once a day google for answers in Stack Overflow. Stack Overflow is a question and answer site for professional and enthusiast programmers. The website offers a platform for […]
An Introduction To Spark and Its Behavior.

The blog is posted by WeCloudData’s Big Data course student Abhilash Mohapatra. Checklist Followed: Mapreduce, Hadoop and Spark. Spark Architecture. Spark in Cluster. Predicate Pushdown, Broadcasting and Accumulators. 1. Mapreduce, Hadoop and Spark For this section, let the below table represents data stored in S3 which is to be processed. Below table represents the Map and Shuffle […]
Looking to Upskill During the Pandemic? Here’s What Bootcamp Grads Have to Say on COVID-19 Experience
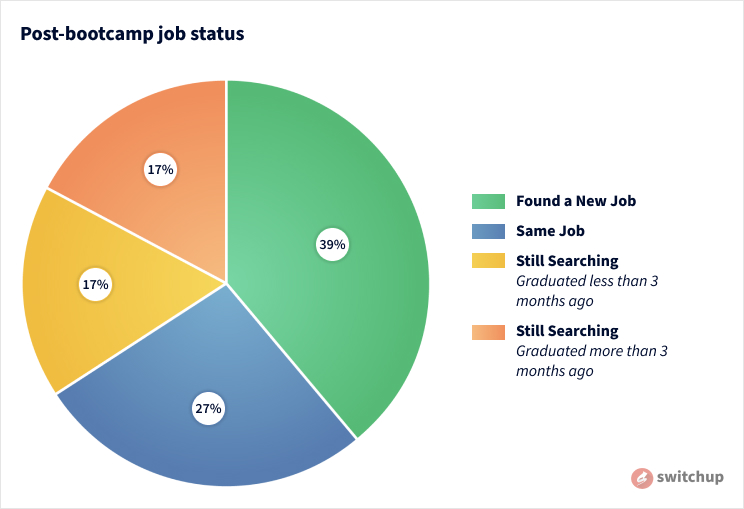
The newest article by Taylor Nichols on switchup shows that the move to online was more popular than people thought it would be. Turns out change can bring new opportunities and be great! Last Updated: September 21, 2020 Click on the link below and check out the article for yourself! https://www.prweb.com/releases/switchups_new_coding_bootcamp_rankings_offer_chance_to_boost_skills_and_career_opportunities_during_pandemic/prweb17413105.htm Key Insights Remote tools and […]
Data Analysis on Twitter Data Using DynamoDB and Hive

The blog is posted by WeCloudData’s student Amany Abdelhalim. There are two steps that I followed to create this pipeline : 1) Collect Twitter Feeds and Ingest into DynamoDB 2) Copy the Twitter Data from DynamoDB to Hive First: Collect Twitter Feeds and Ingest into DynamoDB In order to create a pipeline where I collect tweets on a […]
Analyzing Kinesis Data Streams of Tweets Using Kinesis Data Analytics

The blog is posted by WeCloudData’s student Amany Abdelhalim. In this article, I am illustrating how to collect tweets into a kinesis data stream and then analyze the tweets using kinesis data analytics.</p></p> The steps that I followed: Create a kinesis data stream. I created a kinesis data stream which I called “twitter” with one […]
Embarrassingly Parallel Model Training on Spark — Pandas UDF

The blog is posted by WeCloudData’s Big Data course student Udayan Maurya. Spark is one of the most popular tool to perform map-reduce tasks efficiently on large scale distributed data-sets. Additionally, Spark comes with MLlib package to perform Machine Learning on distributed data. On the flip side Python has very mature libraries: Numpy, Pandas, Scikit-Learn, […]
Let’s Read Customer Reviews (actually-make machines do it!)

The blog is posted by WeCloudData’s Bid Data course student Udayan Maurya. Customer reviews are invaluable information to understand the gap in your product market fit. If you sell your products on e-platforms: Amazon, Ebay, Appstore, Playstore, Youtube, etc. then you are in luck. You have direct access to your customers mind. However, to leverage customer’s […]
Live Twitter Sentiment Analysis

The blog is posted by WeCloudData’s Big Data course student Udayan Maurya. This Live Twitter Sentiment Analyzer helps track present sentiment for a given track word. In this document, I will describe the work flow I followed to develop this SaaS app. Contents Data Pipeline Map Data Collection Preparing Data for Data Analysis Training the […]
From Web Scraping to Useful Data Frames — How to Scrape a Website

The blog is posted by WeCloudData’s Big Data course student Laurent Risser. Toronto is known for its crazy housing market. It’s getting harder and harder to find an affordable and convenient place. Searching for “How to find an apartment in Toronto” on Google leads to dozens of pages of advice, which is a pretty good indicator […]
An Introduction to Big Data & ML Pipeline in AWS

The blog is posted by WeCloudData’s Big Data course student Abhilash Mohapatra. This story represents an easy path for below items in AWS : Build an Big Data Pipeline for both Static and Streaming Data. Process Data in Apache Hadoop using Hive. Load processed data to Data Warehouse solution like Redshift and RDS like MySQL. […]
An Introduction to Data Pipeline with Spark in AWS

The blog is posted by WeCloudData’s Big Data course student Abhilash Mohapatra. This story represents an easy path to Transform Data using PySpark. Along with Transformation, Spark Memory Management is also taken care. Here Freddie-Mac Acquisition and Performance Data from year 1999–2018 is used to create a Single o/p file which can further be used for Data Analysis or Building Machine […]
Eric’s Career Switch Journey from Civil to Data Science
It has been approximately one year since I decided to make a career switch from Civil Engineering to Data Science. After working as a Data Analyst at Slalom for 3 months, I think now would be a good time to share my experience. I will try to present this blog as 3 distinct parts: Why – […]